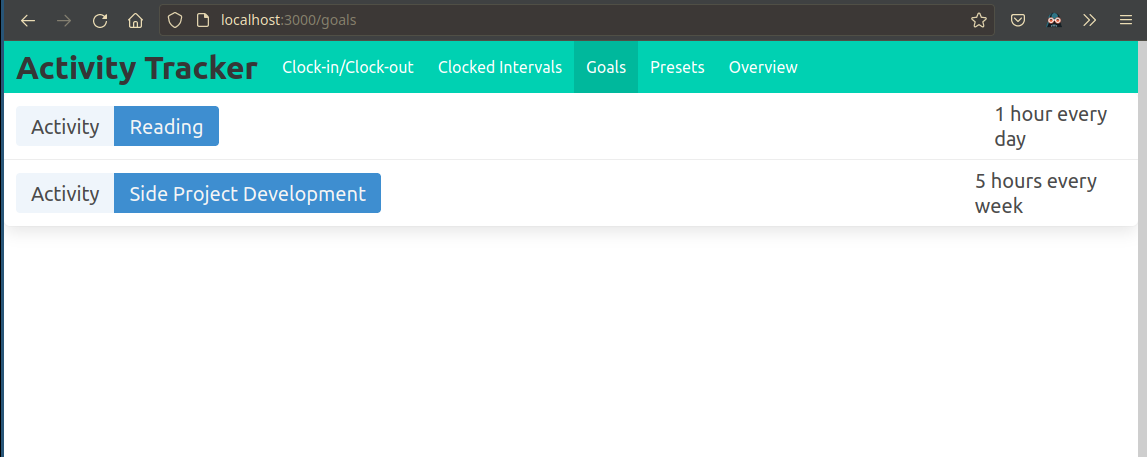
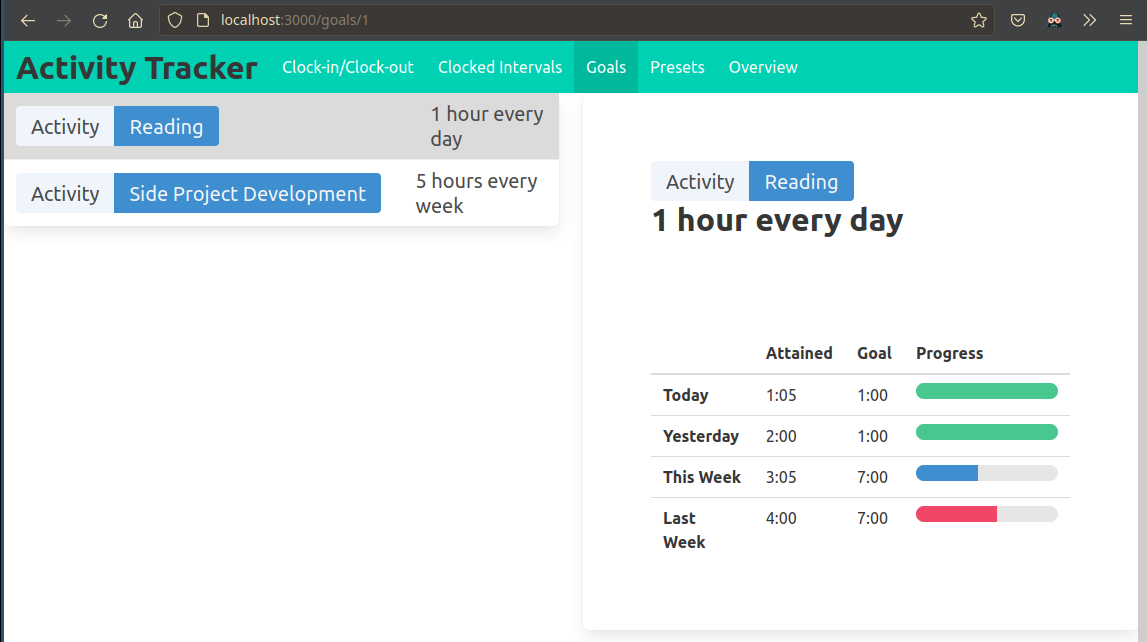
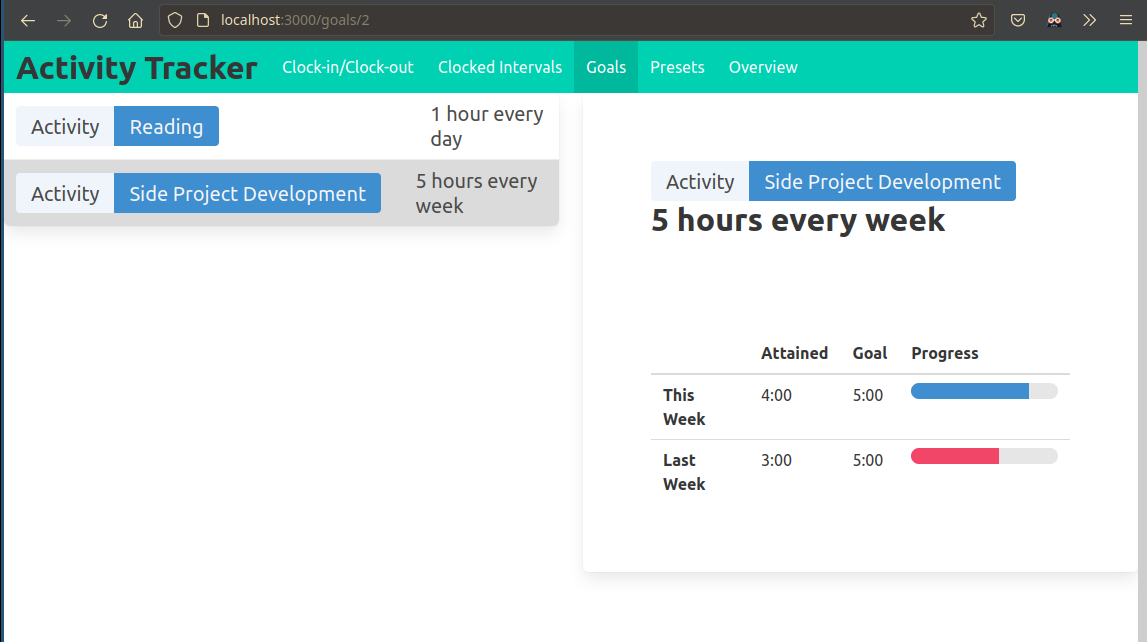
Progress 25 Oct to 31 Oct
I am happy to report that I’ve made a lot of progress this week.
At this point I have nearly achieved feature parity with my previous reading tracker application, so starting next week, I will begin testing the new activity tracker in daily use.
Only thing left for that is to install postgres and spin up the application in my linode box but I don’t anticipate trouble on that front.
I did a complete rebuild of the internals and some of the ui elements based on the change in the tagging system I wrote about last time.
At this point I feel pretty comfortable working with htmx, and I am very confident that the new data model will fit my use cases well, so instead of continuing with the mock data approach I setup a local db and began implementing the model in postgres.
As I intend to host the application on a public domain, and I don’t want randos messing up my data, I setup a cookie-based auth system.
There is not really any good reason for the app to have its own database of users, so I store the necessary secrets in the deployment environment.
Because it was a pretty major rebuild and there was lots of small back-and-forth changes, I have most of them squashed in one big commit (I know it’s not best practice in the long term, but it doesn’t really matter in a hobby project, especially pre-v1.0).
Dev notes
Integrating PostgreSQL
Tooling
From my dayjob I’m used to managing postgresql schema from an external specification (such as sqlalchemy ORM definitions & the alembic tool).
I don’t have any experience with similar tooling in the clojure/jvm ecosystem, and I didn’t want to spend a lot of time manually crafting schema altering commands, so chose to try out pgAdmin.
My experience with pgAdmin has so far been entirely positive.
It makes it easy to setup initial schema as well as altering it later, it has great GUI for viewing the data as if it were spreadsheet and it also makes it easy to do small updates in the data itself with just a few click without destroying the whole table because of a bad update command.
There is also a pretty nice GUI for query profiling and explain analyze.
I don’t expect I’ll have a good opportunity to use it in this project because I will never have a large amount of data, but it is certainly someting I will be keeping in my toolbelt from now on.
Clojure-side
I originally thought my SQL queries would be so simple that I could get away with just having them embedded as string directly in my clojure app code.
However, I very quickly reached the point where it became really clumsy and annoying.
I chose to go with the HugSQL library to make things a bit more organized it let’s me store my queries in separate files (so I get editor support for editing the SQL code), and treats them as templates which can be pulled into the clojure application.
The execution itself is handled by the next.jdbc driver.
I chose the next.jdbc driver over clojure.java.jdbc because it has nicer options for results processing (it’s very easy to declare if the resultset should be vector of vectors, namespace-qualified maps or other stuff).
At this point, I’m not super happy with the sql setup, I have a lot of repetition in the way the queries are defined now which means that small change in the data model would need small changes in lots of queries.
I haven’t yet decided what I’m going to do about it, but the snippets feature of HugSQL seems like a good place to start.
User Interface
Shared active tags in presets view
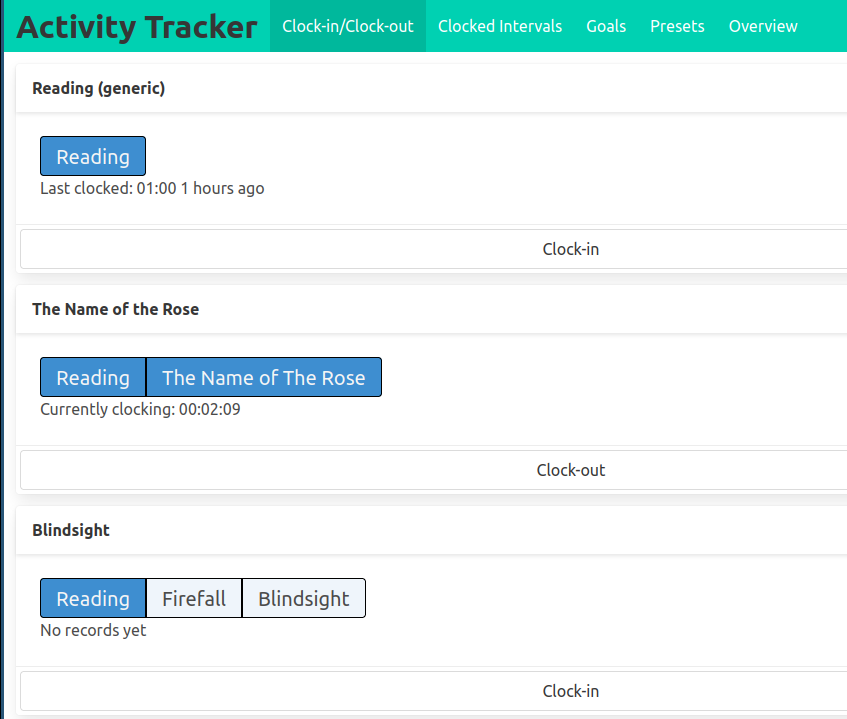
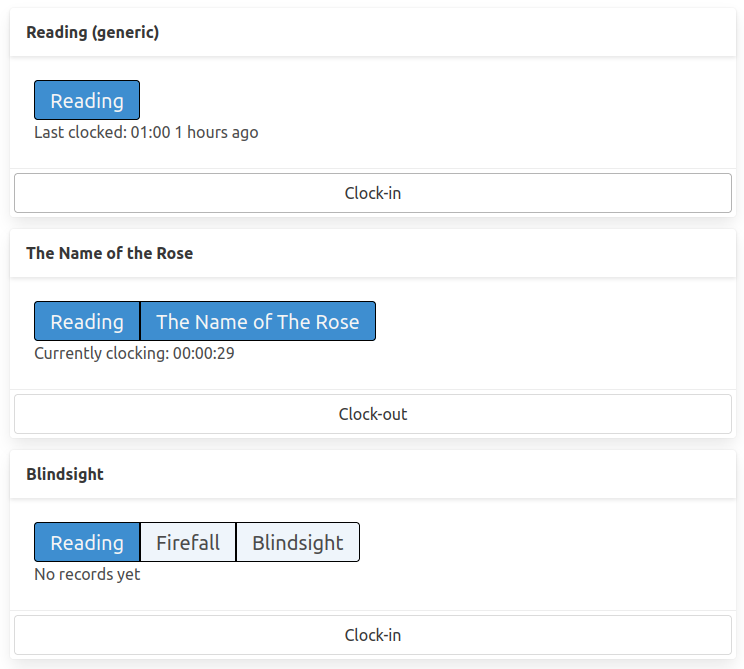
In this new version of the application, I have multiple “clockable” objects called “presets”.
The presets may share tags among them, and I wanted to make this relationship clear in the user interface.
The structure looks like this :
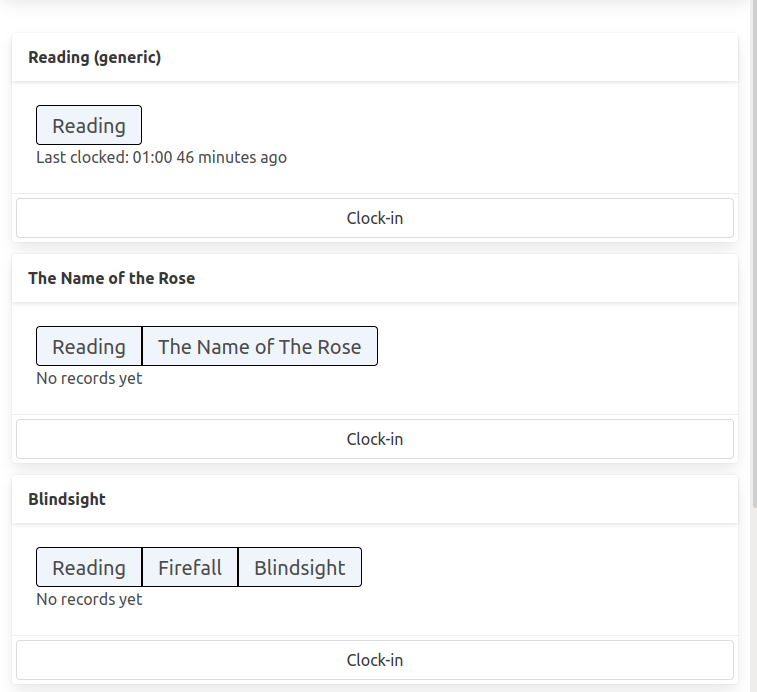
When I press the “Clock-in” button on the “The Name of the Rose”, I issue a request to the server which returns a new version of the preset card and swaps it into the page.
In this new card, all the tags are marked as active (more vibrant color).
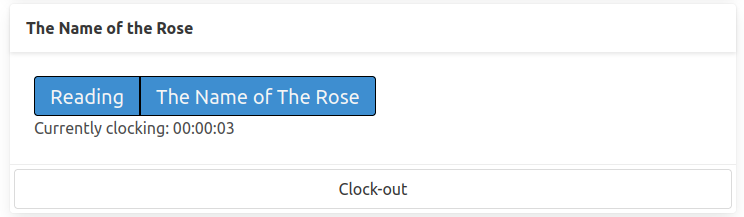
However, this preset contains the “Reading” tag which is also present in other presets, and I want to update them too.
htmx docs describe several ways of achieving this, this is a quick summary of some of the options:
- reload the surrounding component (I don’t like this because it could be unnecessarily running some expensive query on the other presets)
- mark the tag elements in a special way and use the clock-in response to notify the browser that it should refetch the affected tags (I don’t like this because it runs request for the same data multiple times when the tag occurs in multiple presets)
- perform an out-of-band swap - in the response to the “clock-in” request, the server will also return the new definitions for the affected tags outside of the primary preset card, and htmx will swap them into the necessary place
I experimented with each of the methods, and chose to go with the out-of-band swap, there is a minor issue related to the fact that the tags are not necessarily uniqe which I wrote about in this feature request in the htmx project itself.
It is not a blocker for me though, because I can generate tag identifiers by combining preset_id and tag_id.
In general, working with htmx has been amazing, it gives me the means to enable some pretty interesting user-service interactions, while keeping all of the logic serverside.
Interval editing page - redirect after delete
The interval editing page has a panel on the left site which can be filtered by preset_id.
This parameter is passed through a query parameter.
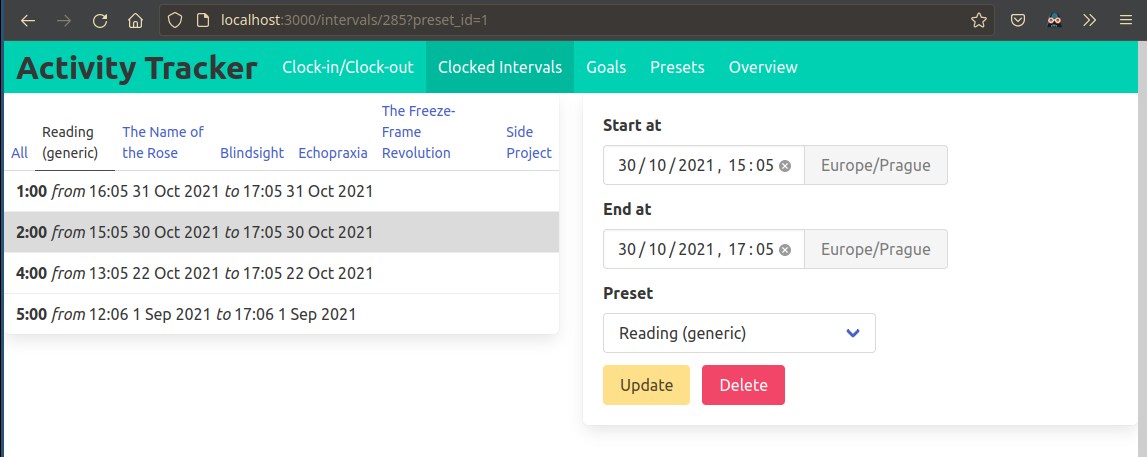
The I delete an interval, the current url (eg. /intervals/5) is no longer valid, so I want to be redirected back to interval selection.
In this redirect I don’t want to lose the preset_id query parameter, so the redirect has to pass it along:
-
/intervals→/intervals/5→ delete interval5→/intervals -
/intervals?preset_id=1→/intervals/5?preset_id=1→ delete interval5→/intervals?preset_id=1
The thing is the redirect happens because the response from the DELETE /intervals/5 contains the hx-redirect <url> header so the server will know what to do after.
At first, I figured I would have to pass the preset_id along with the delete request itself, so that it may build the hx-redirect url with it, but I felt a bit dirty about having a parameter on the delete endpoint which didn’t specifically relate to object in question.
I decided instead to pull the query params from the referer header instead and put them in the redirect url.
Since the referer for DELETE /intervals/5 is /intervals/5?preset_id=1, I get all of the required functionality without polluting the DELETE /intervals/{interval-id} resource path.