Jan 4th 2022 - Retrospective
In short: It’s been fun and I learned a lot.
The goal of this project was to build a mobile-friendly web app for myself to help me track how I spend my spare time and in particular how I’m meeting my reading goals.
The secondary goals were to improve my skills in frontend development, and to gain some experience with running a webservice in a less comprehensively managed environment (linode as opposed to heroku / gcp+kubernetes which I’ve worked with in the past).
In those terms, I consider the project successful:
- I got to know the
htmx library, and I believe I’m now capable of discussing its pros and cons compared to other frontend technologies;
- I’ve learned a lot of things about building a backend service in
clojure with reitit to construct the app, hugSQL or HoneySQL to manage postgres queries, malli for data validation and hiccup for html templating;
- I’ve learned how to setup
nginx (with Let’s encrypt certificates) and postgresql on an Ubuntu box running on Linode and how to setup the DNS records to expose it to the internet ;
- I’ve gained insights into how to manage my workload on a solo project spanning multiple months without burning out on it;
And most important of all, I’ve built a webapp which is useful to me daily and this makes me very happy.
Commentary on acceptance criteria
This is the acceptance criteria as I’ve stated them in the original project plan:
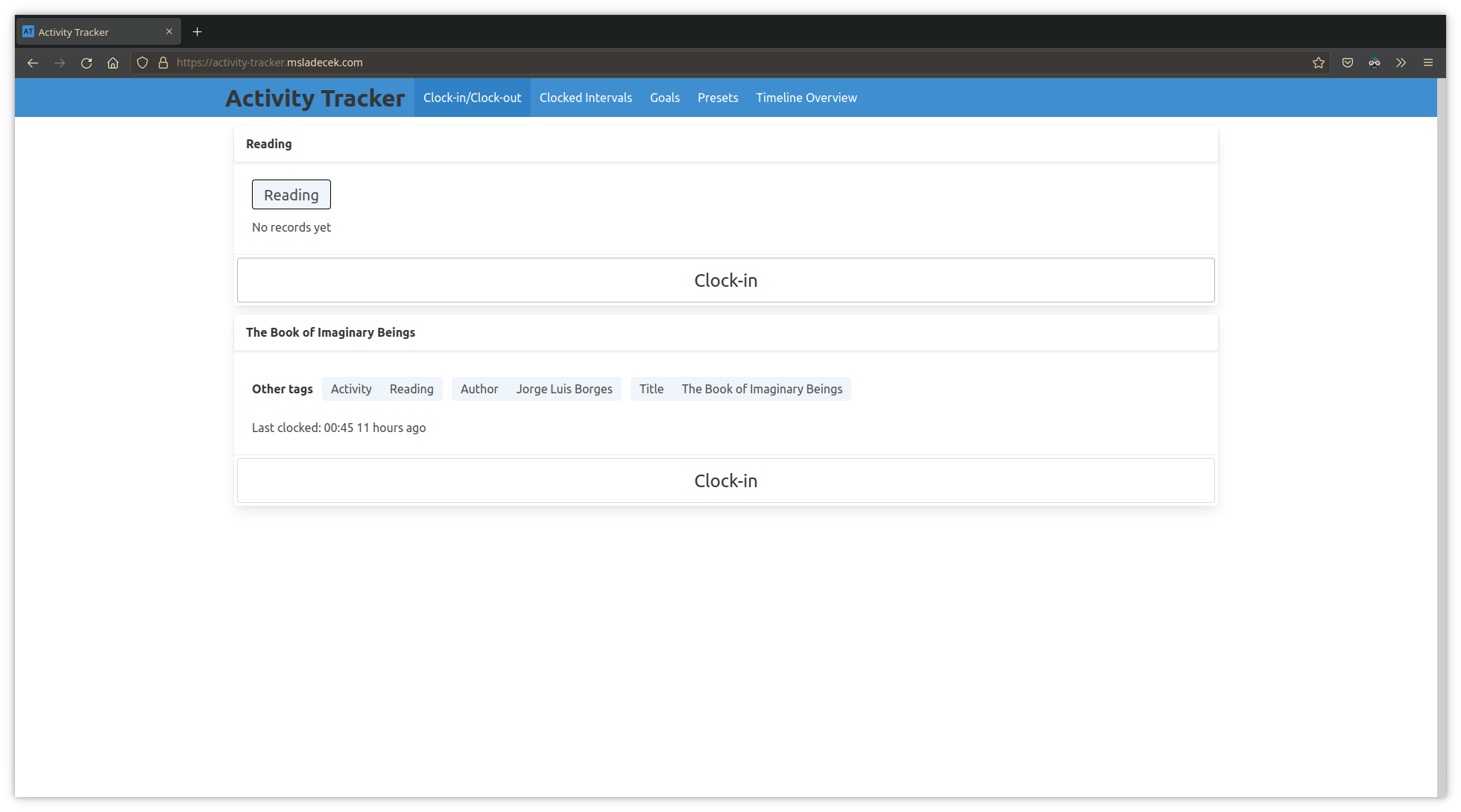
The user is able to access the application through web browser on their computer and on their phone.
With the app deployed on linode and linked to my personal web domain, I can get to it from any device with internet access.
The big useful trick related to this is this one magical html directive which makes is usable on a mobile screen:
<meta name="viewport" content="width=device-width, initial-scale=1">
The user can only access their own data.
Success by default - only one user has access to the app.
Throughout the project’s lifetime, I’ve been toying with the idea of turning it into a publicly available service, where anyone can setup an account and track whatever activities they wish. I never got around to implementing it though.
The primary goal was always to build a tool for myself and my own needs.
I still might add support for additional users later, but probably only as an exercise / proof-of-concept. I’m not really loving the idea of maintaining a features for other people and worrying about breaking it for them.
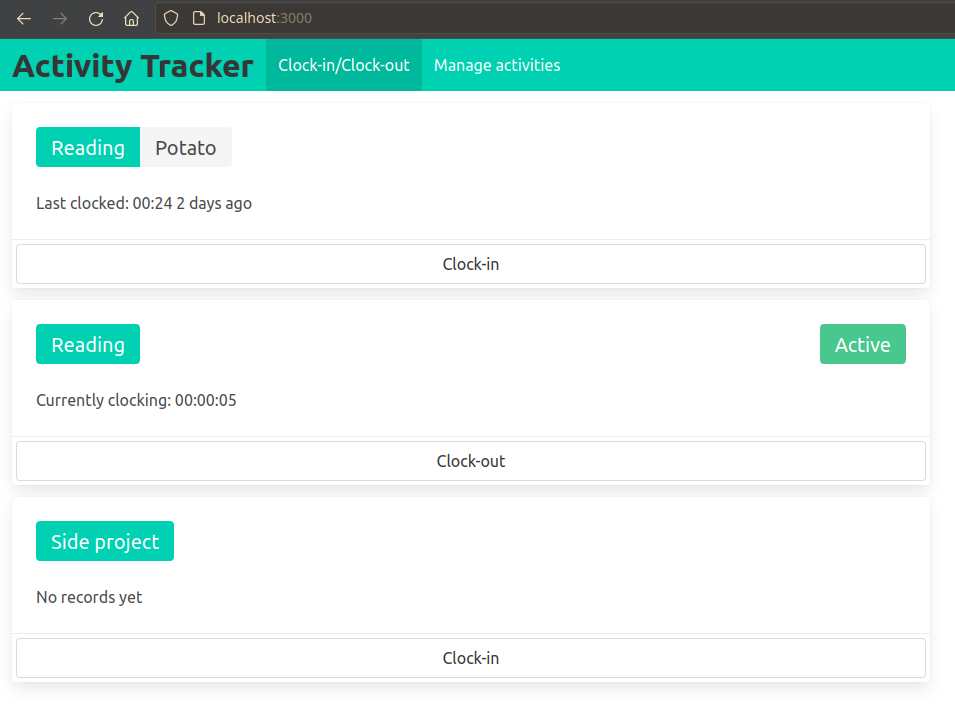
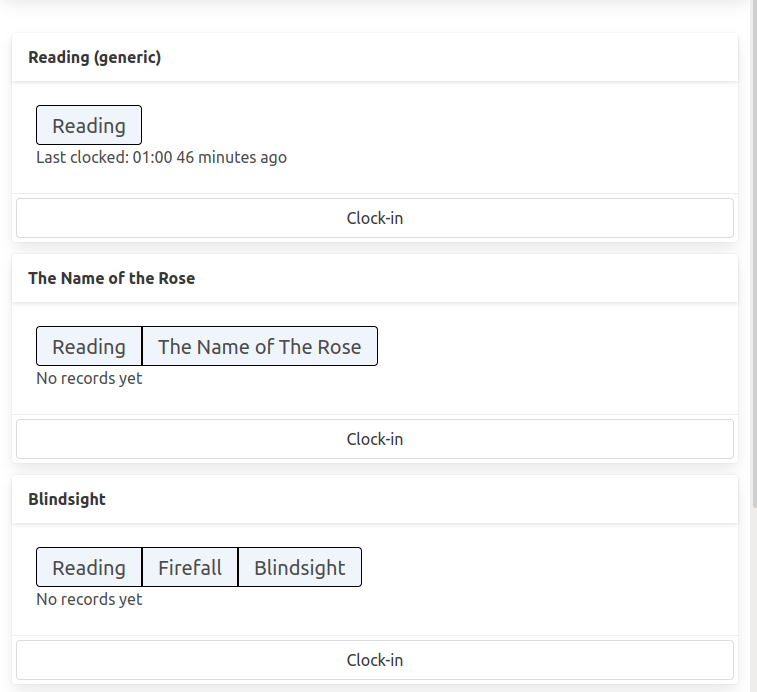
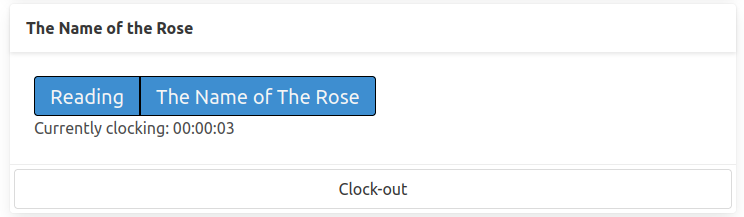
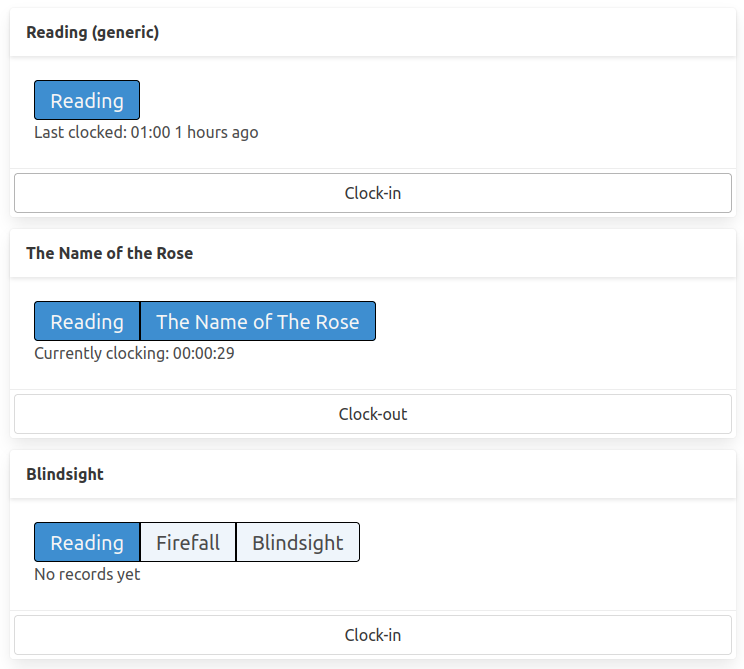
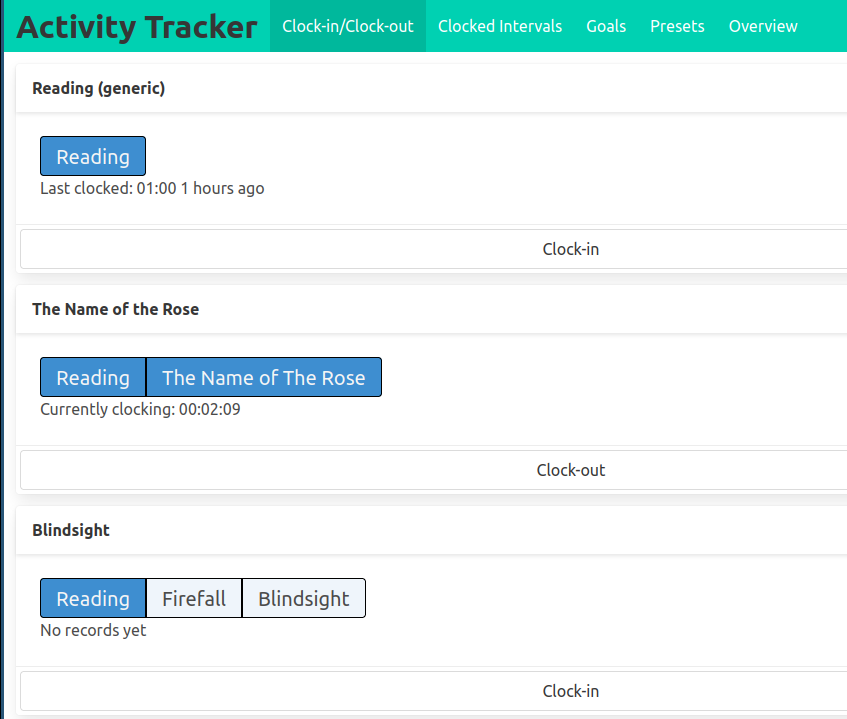
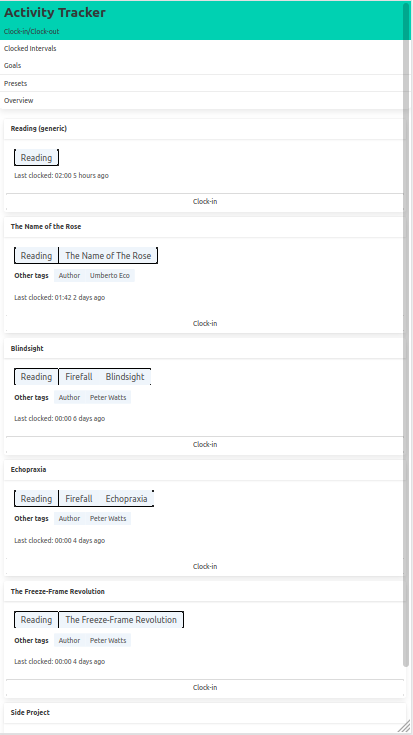
The user is able to clock-into an activity and clock-out-of an activity, the service tracks the time spent in between.
The clock-in button triggers a http request, which begins a new clocked interval on the server, the clock-out button appears on currently clocked-in activities and when clicked, it sends out another http request which ends the interval.
The frontend can be kept pretty simple because all of the application state is kept serverside.
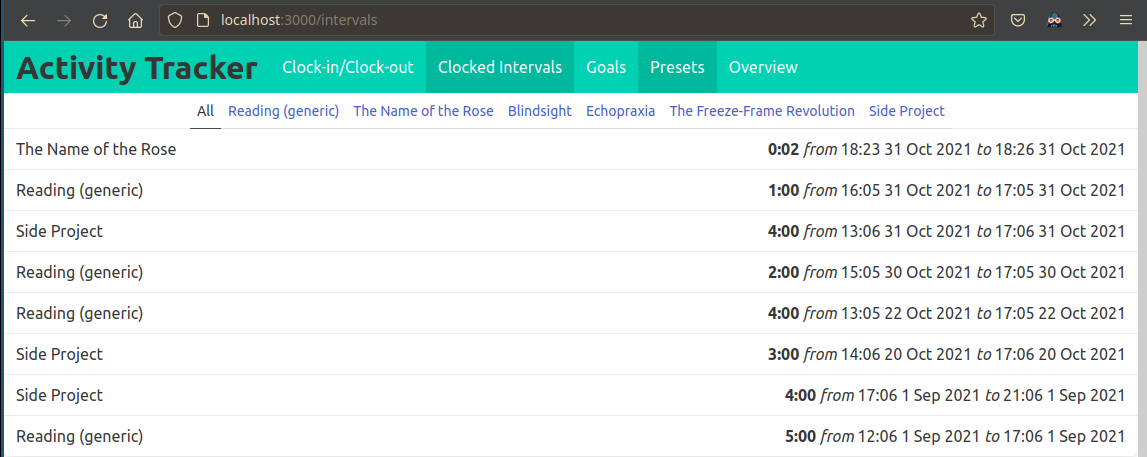
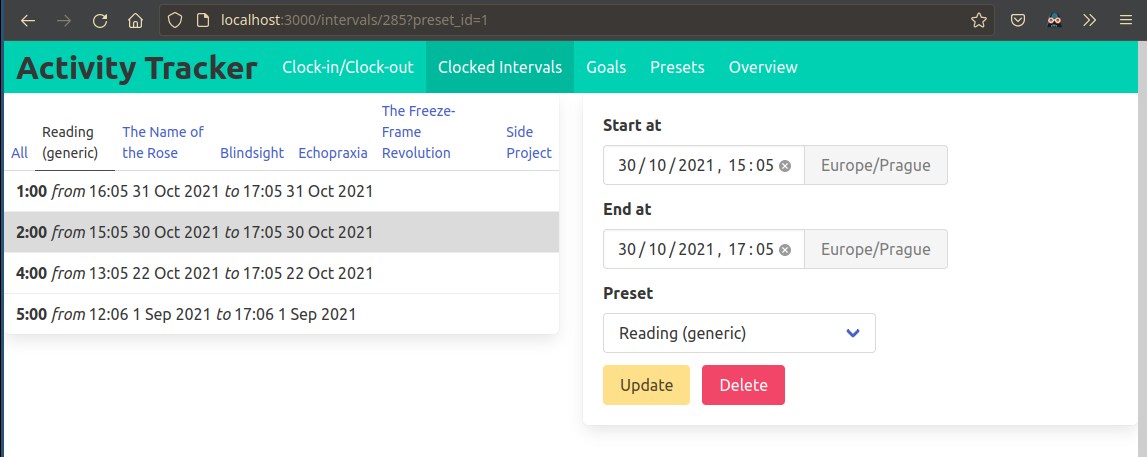
The user is able to retroactively adjust the bounds of a clocked interval or to delete it completely.
There is an interval editing form, including input validation.
The Delete button triggers a pop requesting confirmation, so that it’s difficult to destroy records inadvertently.
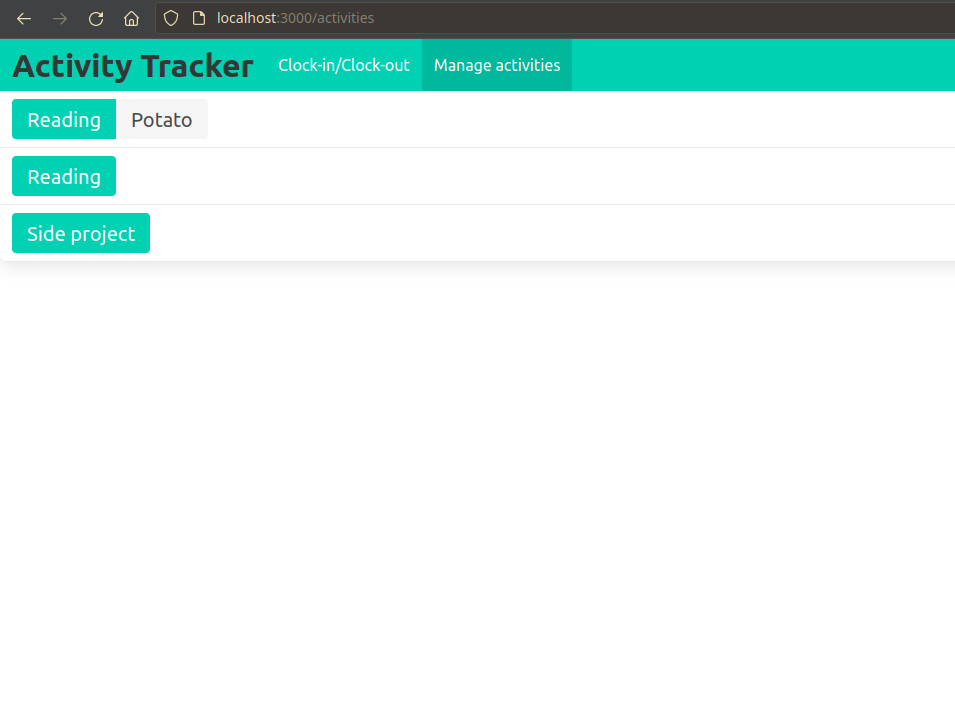
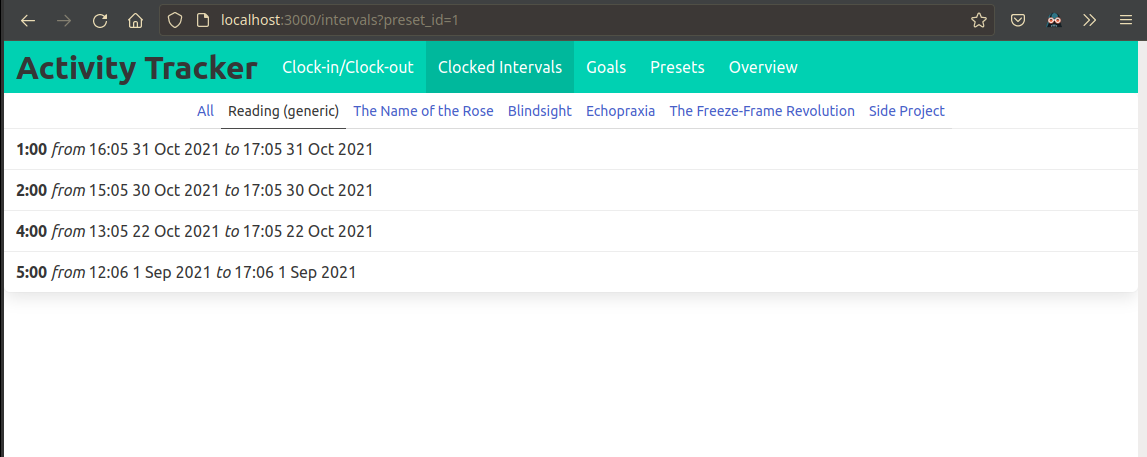
The user is able to track multiple different activities independently.
The activities/presets are individually addressable in the API, so the user can treat them as independent entities.
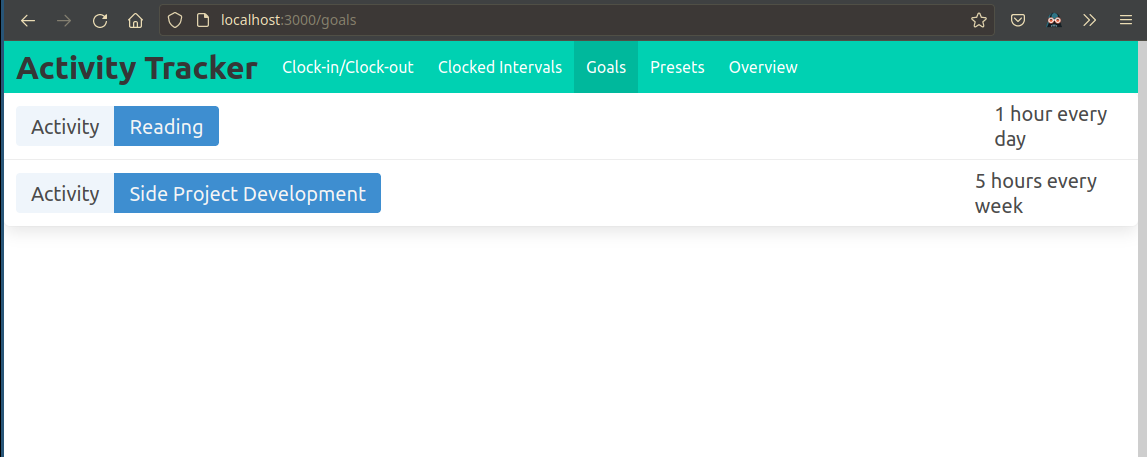
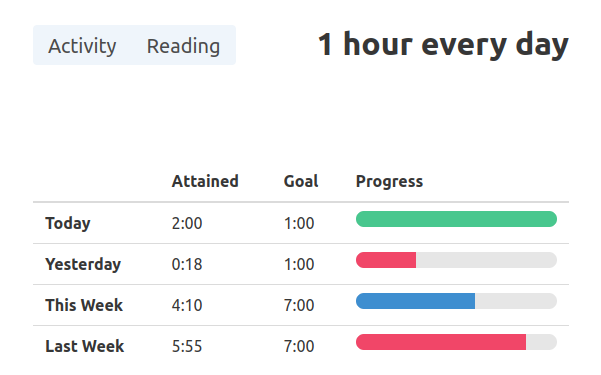
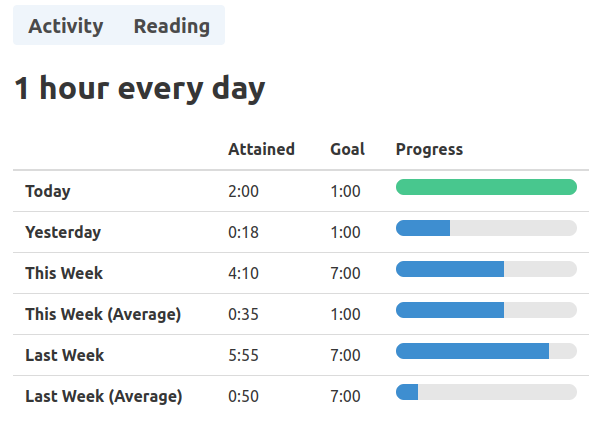
The user is able to define time-spent based goals for each activity.
Originally, I planned to have a goal editor directly in the application itself, but it was always low on the list of priorities because goals change the least often out of all of the entities.
The goals are defined as database records, so when I want to edit them, I can do it without having to release a new version of the backend.
For now, whenever I’m defining a new goal or editing an old one, I do it directly in the database.
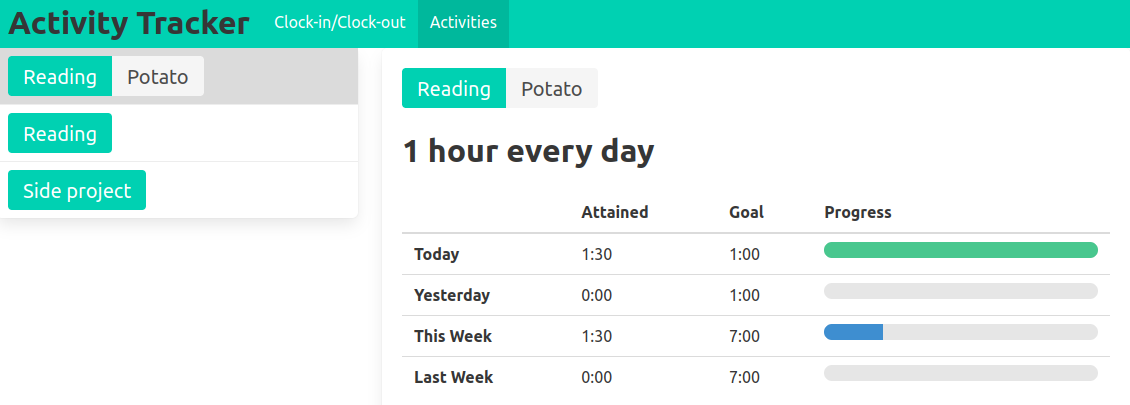
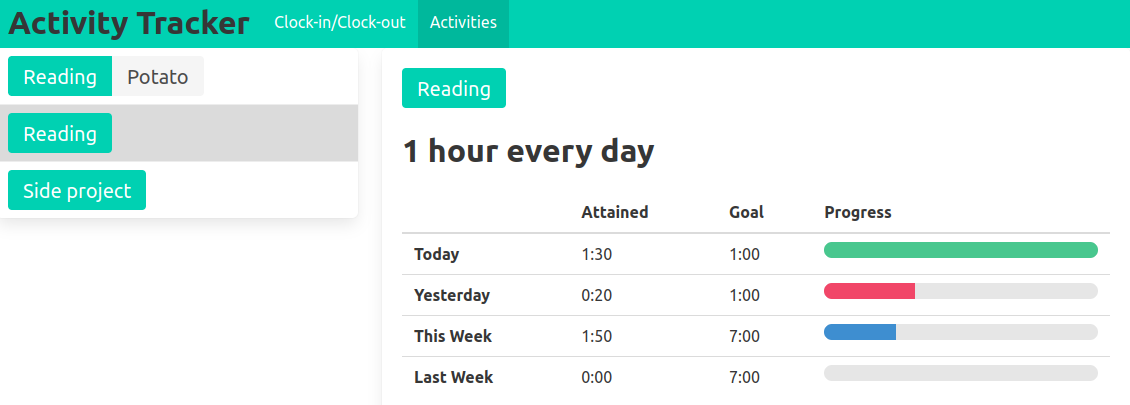
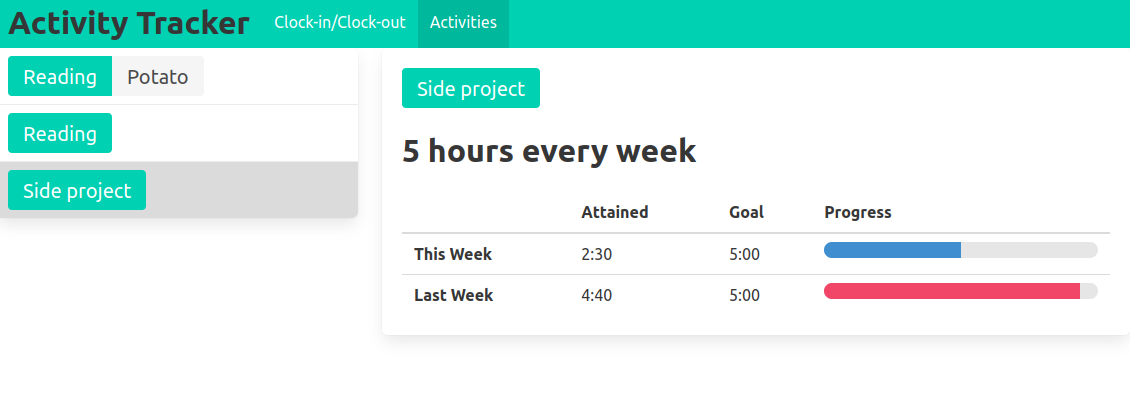
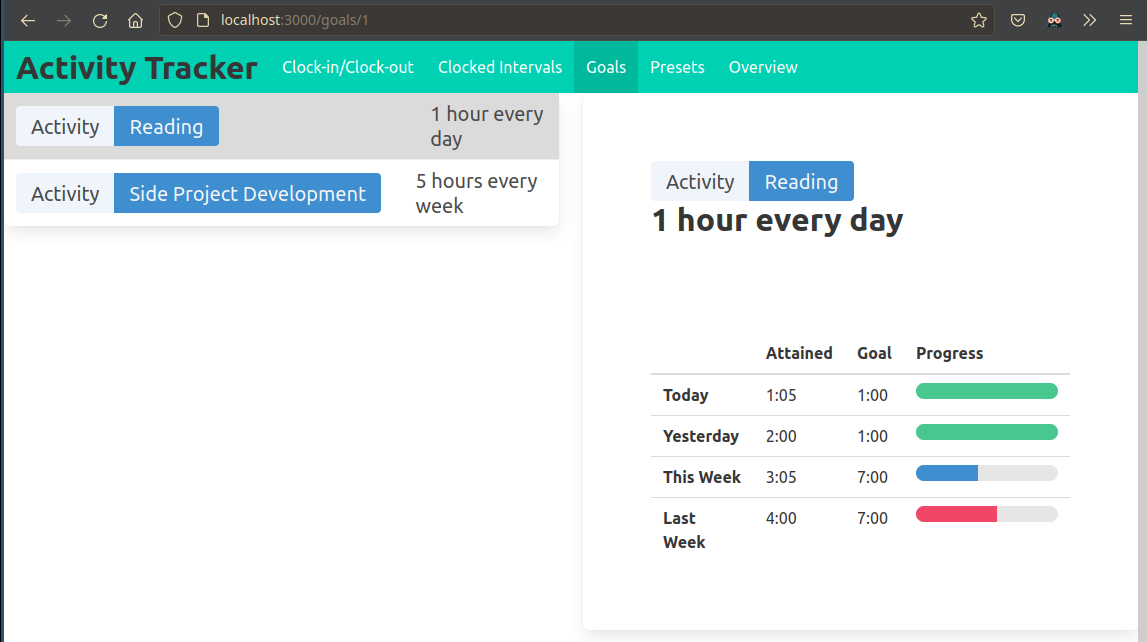
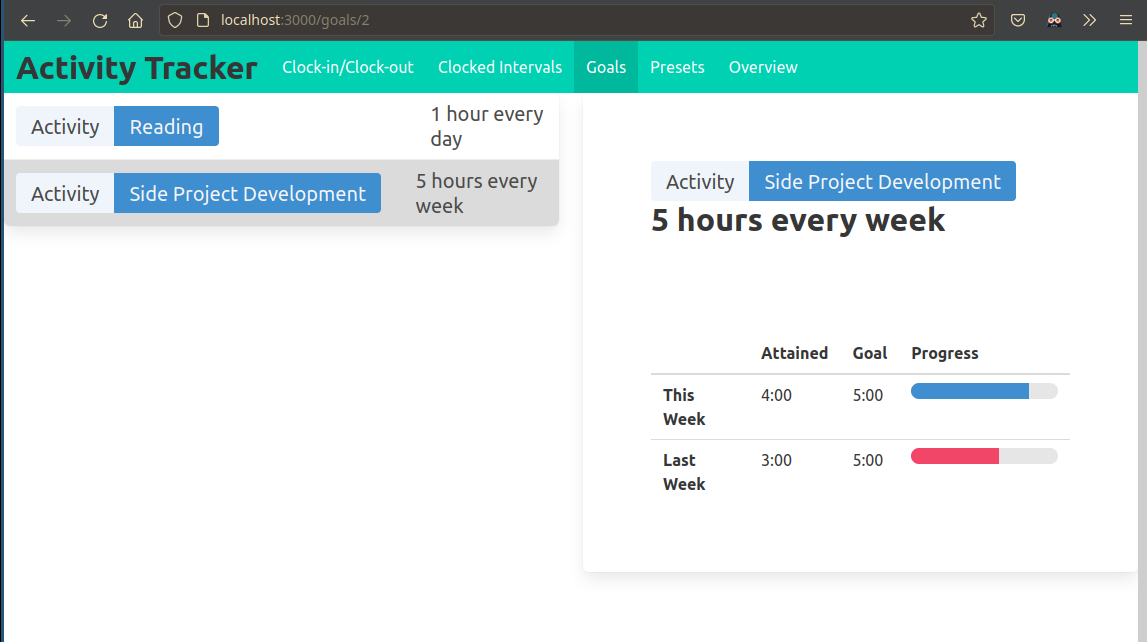
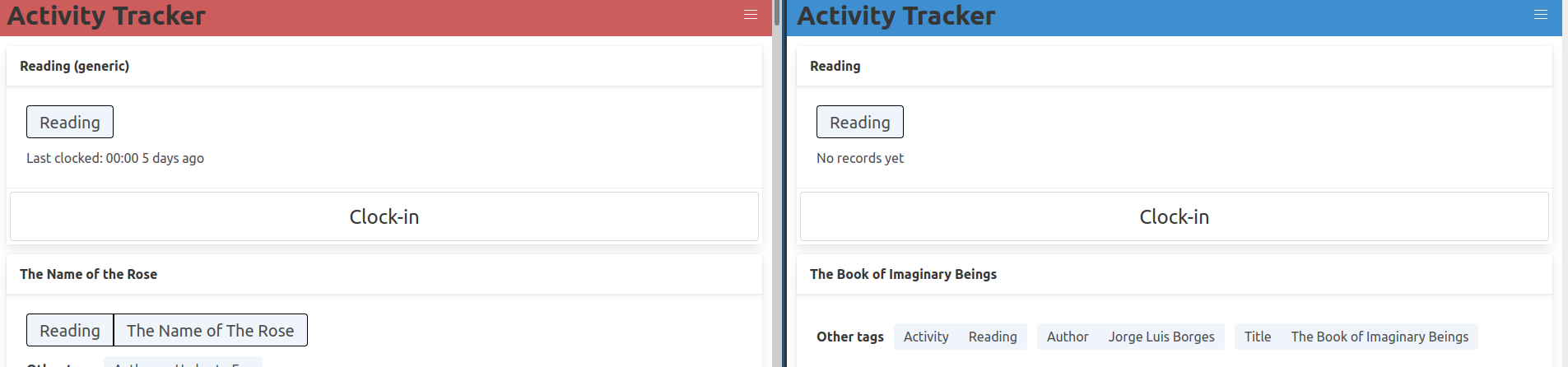
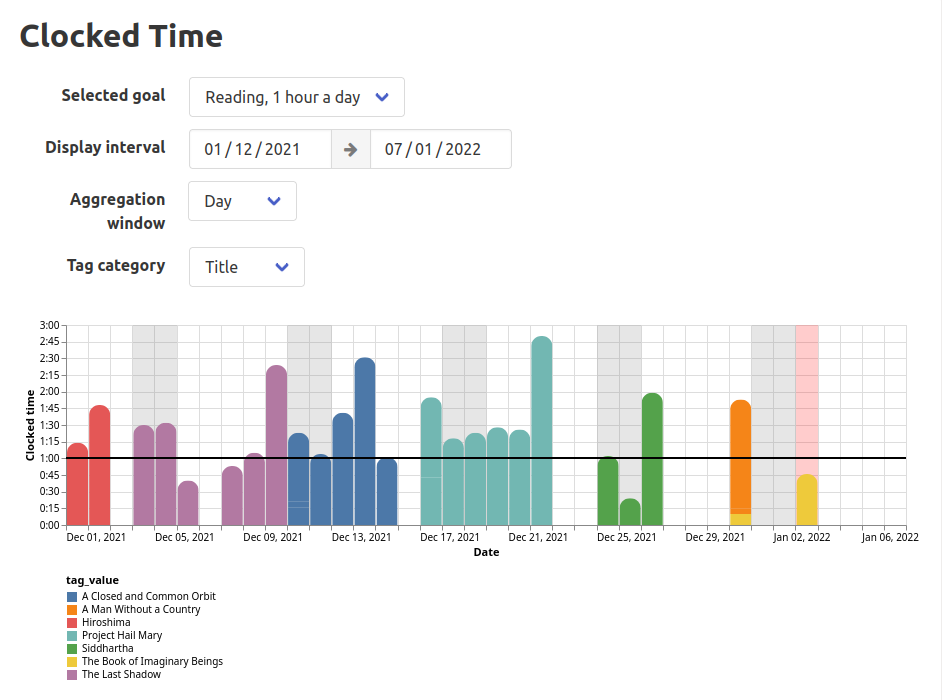
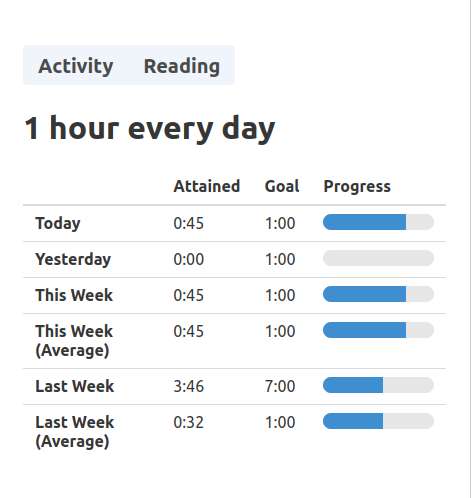
The user is able to review their time spent and how it compares to their goals in a visual interface.
I built a simple table to track the progress on each goal, and a timeline chart for aggregating and exploring stored interval data.
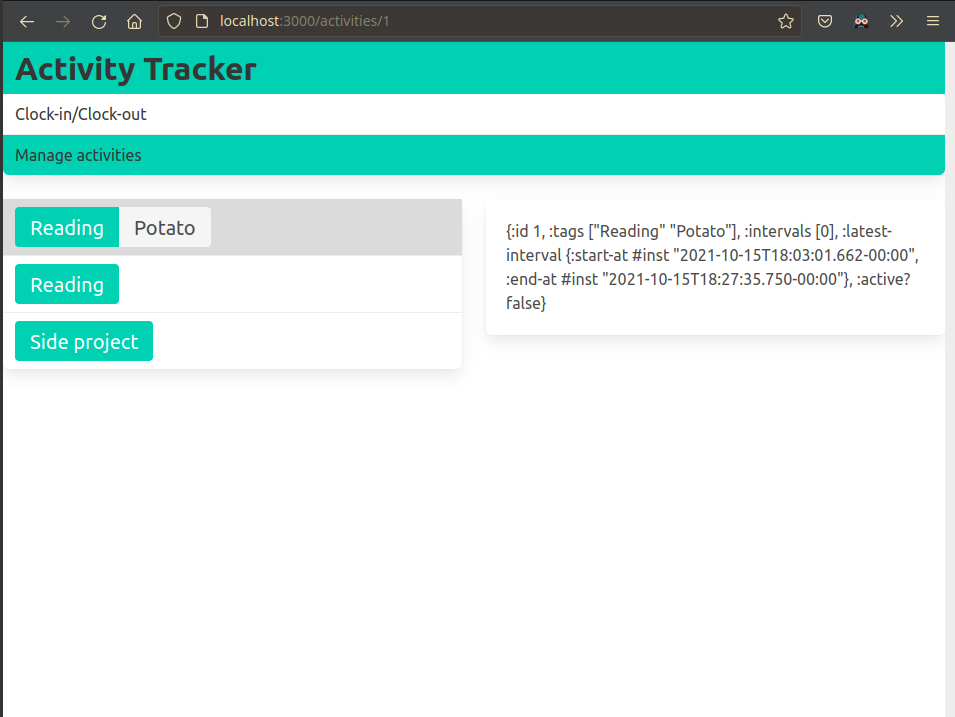
The user is able to retroactively adjust the metadata (such as activity details) associated with a clocked interval.
Each interval is linked to an activity preset - this is the entity with the clock-in/clock-out button.
Each preset may have multiple tags which can be edited, and these tags may be shared by multiple presets.
The tags can be used to compute different aggregations of the intervals.
Any interval can also be easily reassigned to another preset
Libraries/tools used
htmx is a clientside library which extends common html elements with additional attributes to open up new possibilities of client-server interactions without leaving behind the hypermedia-centric aproach.
When communicating with the server, the client receives html fragments as response, which are then swapped into the html document without doing a full reload.
This makes for a better user experience than redirecting to a different pages all the time, and substantially simpler UI definition (as opposed to managing clientside state with a js framework).
It can’t do everything, but for most usecases in my project it hits the right balance of power/complexity.
A few highligts:
-
The hx-boost attribute converts all <a href=...> targeting the origin domain to ajax requests, who’s response’s body is swapped into the current page, instead of doing a full reload.
This eliminates the obnoxious short flicker that so often occurs on many pure-html sites.
-
The active search pattern - with just a couple of htmx directives, the client is able to dynamically search and load data from the server.
From the user’s POV, all of the state is represented in the DOM itself, and not in an opaque js application.
I use this pattern in a component which loads book data from openlibrary.org: Devember 2021 - Punch Clock Web App - #17 by msladecek
I also want to mention the progress on the multiple-swap feature request which I wrote about a while ago.
I ended up contributing a PR to the htmx project and it has been merged into the dev branch so it may become part of the next release of htmx.
I like clojure, I think it’s really great.
In this project, the serverside logic isn’t very complex so any other general purpose language with a webserver frameword would probably do just as well.
One think that stands out though is the hiccup library for html templating.
hiccup let’s us build html fragments from clojure data structures, so there is no need for any additional templating language with its own set of expressions (like selmer, mustache.js, jinja2, django templates).
At its core, reitit is a general purpose routing library.
It can parse path and query parameters out or URIs and find the right handler for them according to a specification, and it can also do “reverse routing”, ie. construct a URI for a given handler and parameter set.
The library ships with many utilities for use in the context of a ring-based web service.
The route specification can be augmented with special chains of middleware which will be applied only on certain paths and parameter validation/coercion specs.
Being able to define separate middleware chains is very useful, and I’ve been missing a feature like this in other web frameworks in the past.
malli is library for data validation.
The schema syntax resembles hiccup.
I use it to validate and coerce http request parameters.
I think it’s pretty neat, but my use case is fairly basic, so I didn’t really have an opportunity to dive deeper into some of its more interesting features.
At the same time, I found that some features that I would like were not available in malli.
For example, I have an endpoint which accepts a form with several well known fields, and then several dynamic fields (label and type are known, but tag-$A, tag-$B are dynamically generated).
As far as I can tell, there is no way to easily express this in malli, so I am considering switching to validation based on json schema which supports the additionalProperties field, but if I do switch I would probably have to write some adapter for reitit to make the coercion work.
I’ve used vega-lite in the past, but in this project I’ve discovered some new useful features it has.
I use it to generate the timeline visualization chart: Devember 2021 - Punch Clock Web App - #19 by msladecek.
With vega-lite, you define your visualization as a static json document - you declare where to get the data from, what to draw on the x axis, the y axis, what attribute should decide the color etc…
In this project, I learned about the interactive parametrization features of vega-lite.
It is possible to define a parameter binding pointing to an element outside of the visualization itself.
The library then installs its event handlers on the elements and adjusts the visualization when the parameter values change.
It’s a bit like having a small reactive framework to control the interactivity.
The only downside is that not all fields of the specification can be parameterized this way, so in one case (the time unit selector), I resorted to triggering a reload on the entire chart: Devember 2021 - Punch Clock Web App - #19 by msladecek.
I have nothing but positive things to say about linode.
At this point I’ve only played with the DNS configuration tool, and with some basic stuff related to setting up a small linode instance.
They have pretty good docs, and I’ve learned a lot of when setting up my services.
Particularly interesting to me were the things related to nginx setup and TLS certificates with Let’s Encrypt.
General thoughts on the project
This thread
From the start I’ve been posting weekly updates in this thread.
I tried to pick out some interesting problems I’ve faced and things I’ve learned.
I think the commitment to composing a progress update post (and therefore having to have made some progress) was key in staying on track for 2+ months.
I would wholeheartedly recommend running a similar periodic progress log when working on a solo project like this, even if you decide to keep it private.
I don’t really know how many people have been following the thread, and I expect not many have (in great detail), but even if it were just for myself, it would still be very useful.
Looking at a single snapshot of a project, even your own, it’s really easy to take the single version for granted and to to misunderstand how much effort went into it, how many decisions were made, ideas explored, developed or scrapped. Having a log of some of it helps form a deeper connection and understanding of it all.
It’s also a good opportunity to practice the communication of technical topics, which is in my opinion an often underestimated, but very important skill.
I also want to thank those who have been reading these points and engaged them with likes and comments, it is a nice feeling knowing that I haven’t been talking to myself this whole time. Thanks in particular to @Mastic_Warrior for the kind and encouraging words.
Current status & future
I’m very happy with how it turned out.
The result is still a bit rough in some places and I have ideas for a couple more features, but I’m going to be spending less time on it than I have in the last few months.
I think I’m really onto something with the time tracking idea. (I’m certain I’m not the only one who had it!)
Even though I’ve still been using to only track reading time, the goal from the start was to have something more universal, so I’m going to start tracking other activities to hopefully regain even more control over my spare time.
For those interested in something similar, I have some notes which may be useful:
- Start with small goals that you’re certain you can achieve, stick with them for a while and then reevaluate them.
- Focus on positive reinforcement only, don’t kick yourself when you fall behind on your goals; Don’t implement the concept of “failure” into your system (components which would emphasize the goals which you hadn’t met)
- Consider carefully the time frame for evaluating your goals, use an interval long enough to showcase your consistency, but short enough that if you slip up and your goal becomes unachievable in the time frame, it won’t sit there for too long reminding you of it.
- Build your own stuff. It feels nice. You can shape it into anything your want and you won’t feel trapped by somebody else’s decisions.