tl;dr;
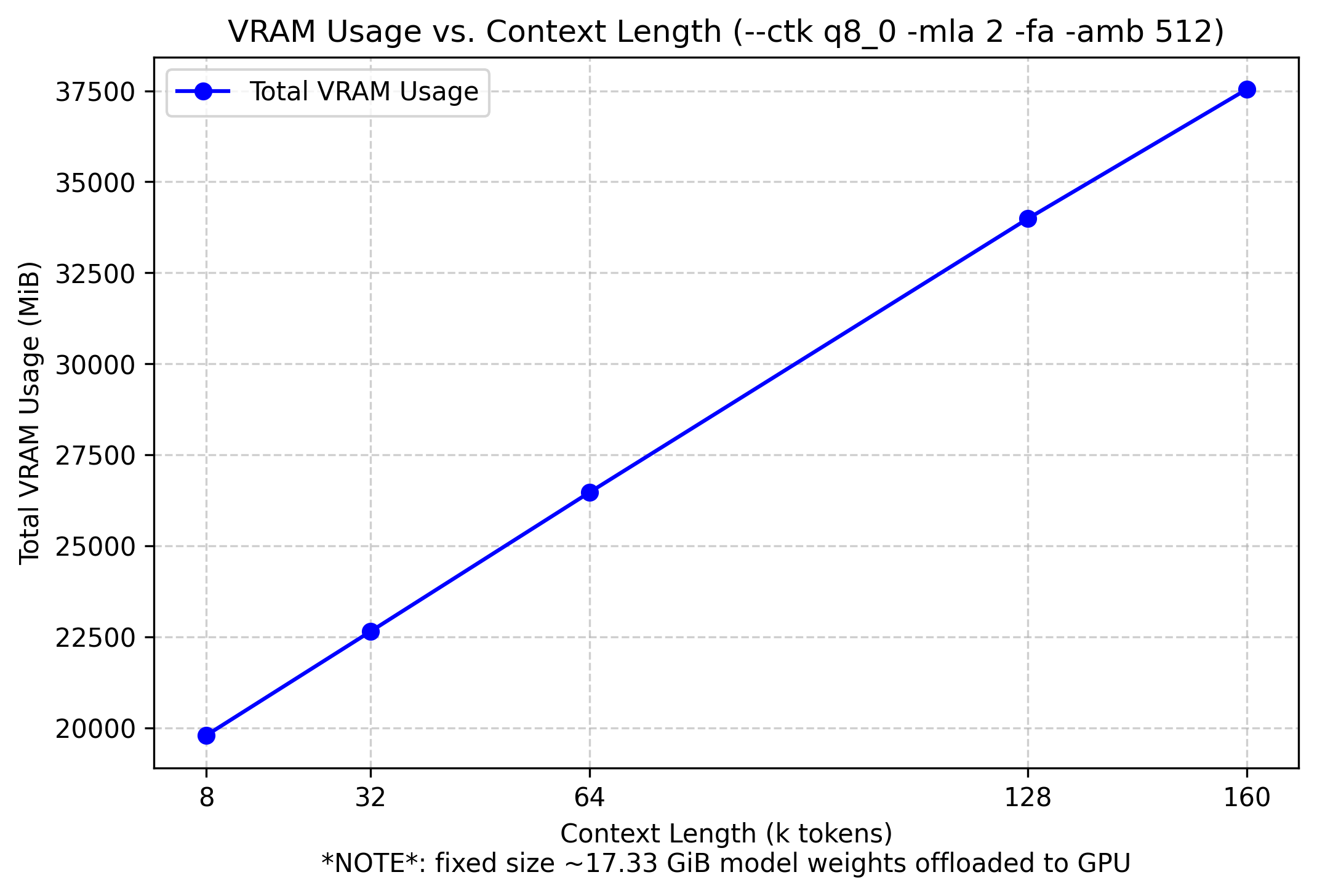
For deepseek specifically, the VRAM usage will be the amount due to offloaded tensor weights plus KV-cache that grows linearly due to MLA. For most LLMs it grows exponentially as they don’t use MLA.
I made this chart when experimenting with
ubergarm/DeepSeek-V3-0324-GGUF
So this chart will vary depending on the exact model and kv-cache quantization you choose. More below.
The Deets
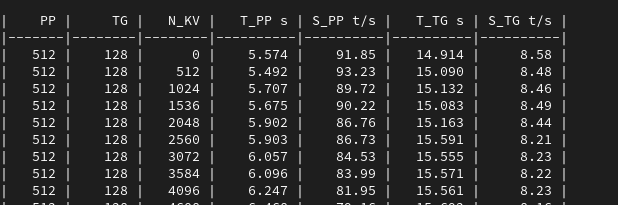
It varies widely by model, and the easiest way is to start up a few times with different settings and note the debug logs that tell you how much VRAM is being used e.g.
- Vary the size of the kv-cache entries e.g.
-ctk f16 -ctv f16 or -ctk q8_0 -ctv q8_0 etc.
- Vary the context length e.g.
-c 8192 and -c 16384 etc.
- Note the logs on startup e.g.
# for deepseek only uses `-ctk` and ignores `-ctv` as it is MLA:
llama_kv_cache_init: CUDA0 KV buffer size = 612.02 MiB
llama_kv_cache_init: CUDA1 KV buffer size = 554.64 MiB
llama_new_context_with_model: KV self size = 1166.62 MiB, c^KV (q8_0): 1166.62 MiB, kv^T: not used
# for a non-MLA you'll see something like
llama_kv_cache_init: CUDA0 KV buffer size = 5120.00 MiB
llama_new_context_with_model: KV self size = 5120.00 MiB, K (f16): 2560.00 MiB, V (f16): 2560.00 MiB
Also is there a llama.cpp flag to tell llama.cpp on which CUDA device is should store the context?
tl;dr; I don’t know.
Notice it tells you which CUDA0/CUDA1 device has how much of the buffer assuming you are using multi-GPU config.
So I’m not sure if that can be adjusted to put all the KV-cache buffer on a single fastest GPU for example. Looking at some of the arguments available in the help:
-sm, --split-mode SPLIT_MODE how to split the model across multiple GPUs, one of:
- none: use one GPU only
- layer (default): split layers and KV across GPUs
- row: split rows across GPUs
-ts, --tensor-split SPLIT fraction of the model to offload to each GPU, comma-separated list of proportions, e.g⟩
-mg, --main-gpu i the GPU to use for the model (with split-mode = none),
or for intermediate results and KV (with split-mode = row) (default: 0)
So I never change these settings, but maybe using -mg would do something? You could try and then observe the output logs. I’d not recommend changing -sm though. And no need to use -ts when using -ot…
I swear I saw an experimental PR on mainline llama.cpp by fairydreaming perhaps to put all the kv-cache on a single GPU or on a single NUMA node or something, but it didn’t yield any gains. Ahh here is that reference
There was some more chatter about cuda device order here but don’t think it answers your question.
What are you trying to achieve by manually placing the kv-cache on one GPU or another?