So this is where it’s tough. If you imaged /dev/nvmeXnY, that includes all the partitions.
You did well with your first action being a copy image. At this point, you’re going to be using a lot of disk space. What I do is I take a copy of that image on an external and unplug that disk, so I always have an offline copy.
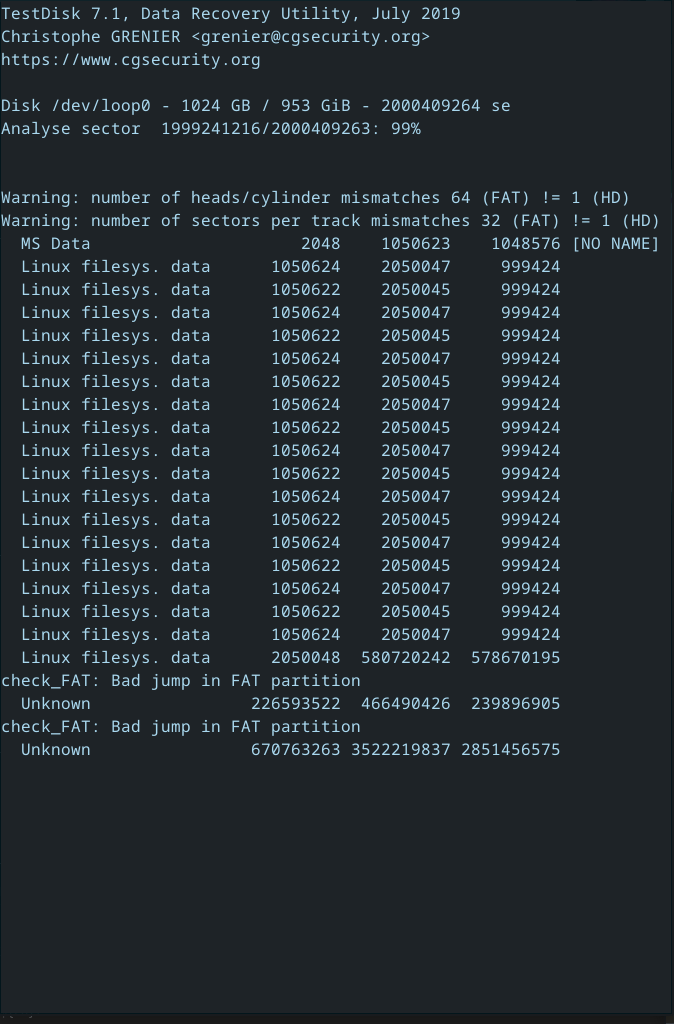
This is where testdisk comes in. You can use testdisk to see if it can find the partitions and recover the partition table. However, you’ll need to loopmount the filesystem.
First, make a copy that you won’t write to:
cp ~/disk_image ~/disk_image_NOWRITE
As root:
losetup -f
losetup /dev/loop1 ~/disk_image # Replace /dev/loop1 with the output of "losetup -f"
losetup /dev/loop1 # Replace /dev/loop1 with the output of "losetup -f"
This will create a loop device at /dev/loop1 which pretends to be a block device. You’ll be using the initial image, and this file will be modified, which is why it’s important to have another backup.
Next, you can use testdisk: sudo testdisk
In there, the first thing it’ll ask for is if you want a log. That’s not necessary here.
Next screen will be the disk selection. Make sure you choose the loop disk you just created. After you select your loop disk, choose proceed.
It will then ask the partition table type. Yours is most likely EFI GPT.
Once you select the partition table type, testdisk is configured. It’ll ask you what you want to do. The first step is “Analyze”, then “Quick Search”. testdisk will then do what it can to find all the partitions on the disk.
If you had an EFI boot partition, it’s gone. If you had a /boot before your /, it’s gone. The important thing is that hopefully it can recover a lot from your main data partition.
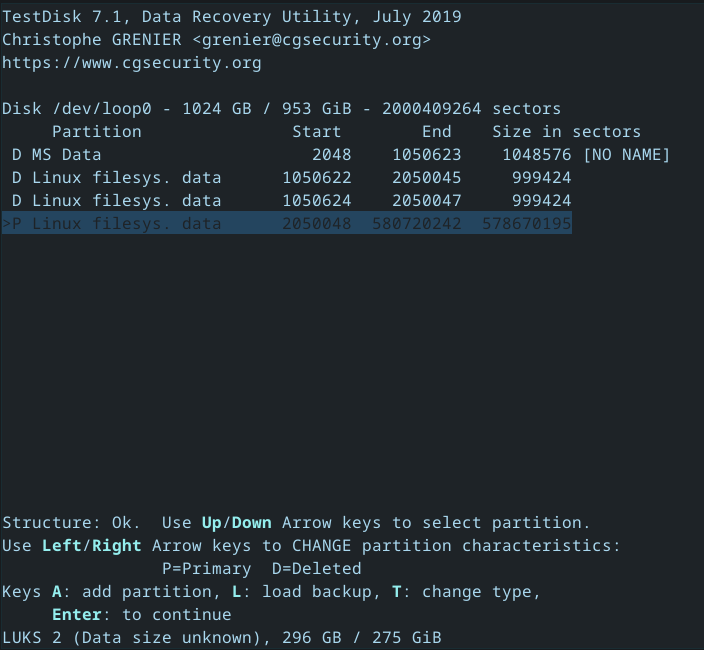
Once the analysis is done, you have the option to reconfigure the partition boundaries. I wouldn’t, unless you know what you want. Testdisk is pretty smart here.
If it all looks good, you can write the new partition table to the image with “write”. If not, run a deeper search. This will take a lot of time, go get lunch or watch a movie, kind of long.
Once you’ve finished writing the partition table, you can quit out and that’s where FSCK comes in.
If FSCK still can’t help you, take yet another backup, and we’re going to do a hail mary.
Since this is sort of black magic and can be pretty sketch, let me know if FSCK doesn’t help you here, and I’ll write about the hail-mary then.
If FSCK does recover the partition, you’re probably going to see a lot of stuff in Lost+Found