I was finally able to get relatively good performance out of my xeon max system… however I don’t completely understand why the configuration is working well.
I used numactl to control which CPUs and which NUMA nodes the application ran on rather than relying on the kernel to automatically schedule it or the userspace arguments to dictate the NUMA configuration. The most optimal configuration turned out to be running all compute on all the CPUs in 1 socket but letting it access the NUMA memory nodes both on the local socket and the remote socket.
I understand that a lot of the performance problems were caused by cross socket latency from the VTune profiler’s report, so it makes some sense that constricting the workload down to a single socket with relatively good latency improved performance, but I don’t understand how remote socket HBM improves the situation; there must be some kind of hardware-level cache coherency scheme going on that I don’t understand. This also explains why AMD Epycs don’t perform as well as you would expect them to; I’m speaking to the multiphysics benchmark rather than the CFD-only benchmark which the Epyc does very well on.
Here’s what the NUMA configuration of the computer looks like in HBM-only mode:

and this is the command that results in the best results so far numactl -C 0-55 -m 0-7 ./comsol62_benchmark_CFD_EM_60GB_Linux_x86-64.sh -np 56
multiphysics run:

CFD-only run:
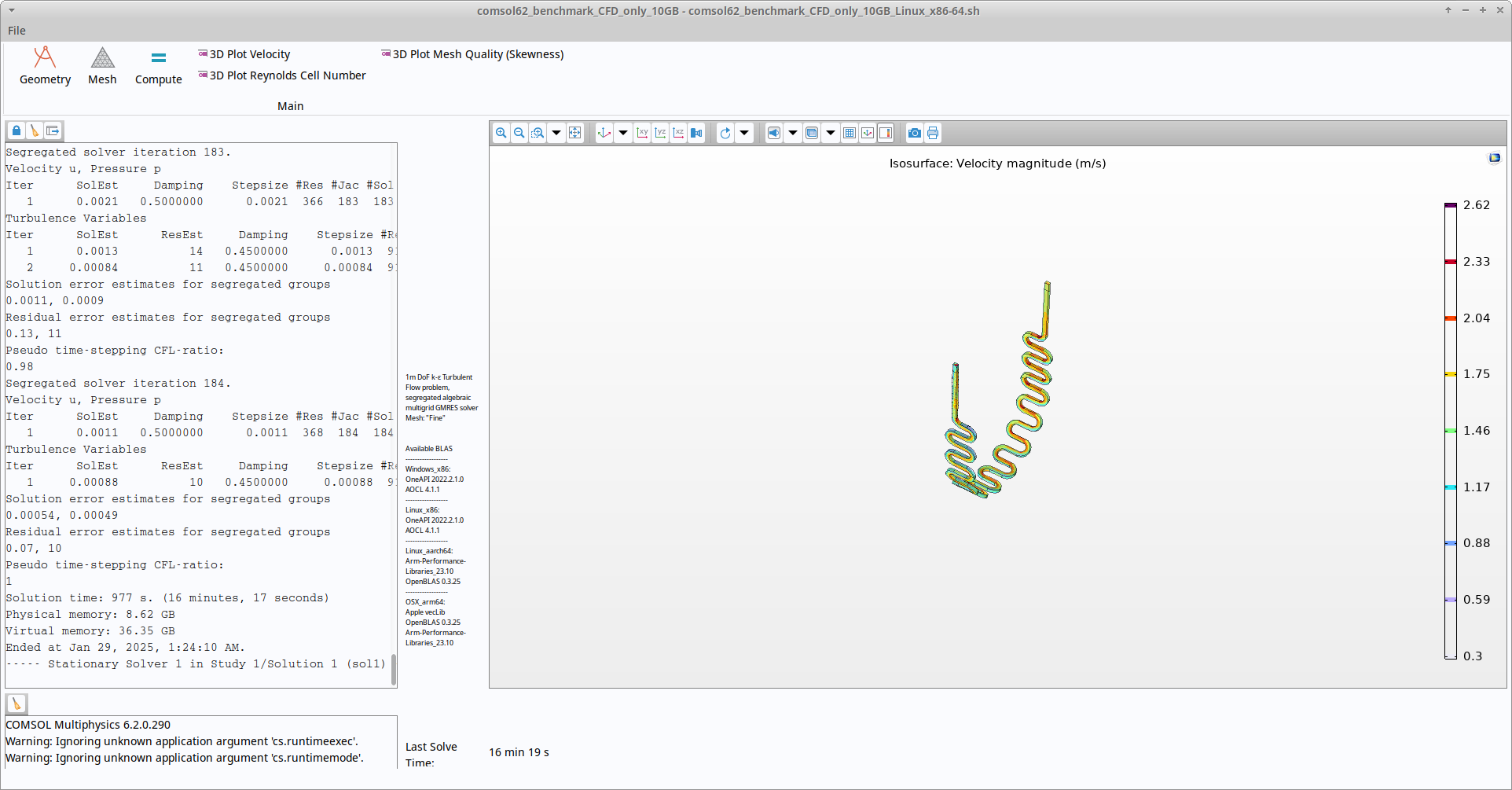
This is a fairly substantial score, beating the current chart topping dual Genoa F-sku CPUs by ~20%, although I’m willing to bet that the Eypc’s performance could have been improved by not letting Linux schedule process threads on laggy cores.