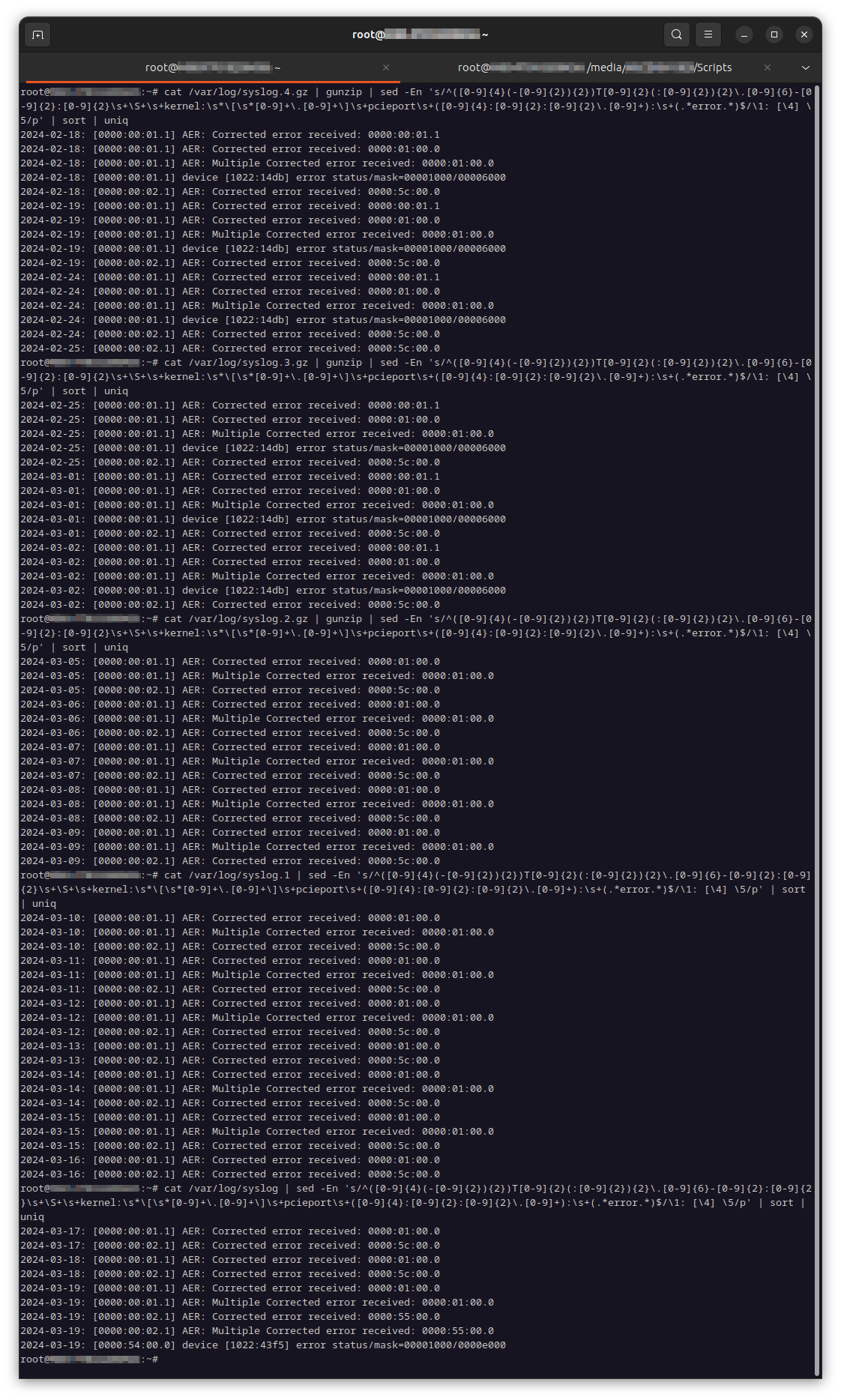
I didn’t think to peek at syslog until the system caught a T10 protection information error. While my main issue was cleared up, there’s been a residual sluggishness with the VMs that I haven’t shaken off. And now that I’ve seen them, I cannot unsee:
The picture doesn’t give the full picture of my situation, but it does show that it’s been going on for a while. These entries have been filling the logs in bursts approximately every 10 seconds or so.
01.00.0/00:01.0/00:01.1 can be attributed to the graphics card slot. It was a GeForce GT 1030 until midnight of 2024-13-14. Then it was a RTX 4000 ADA. That the behavior persists across video card changes can only mean that the problem is not card-related.
The remainder of the errors under 00:02.1 are chipset-connected devices. 5c:00.0 corresponded to an Intel Optane P5800X which—until today—remained connected via an M.2-to-OCuLink-to-ICY DOCK path including a redriver. The OCuLink cable is 65 cm, which I purchase from Supermicro. However, I had also inserted it into a different slot connected via a shorter 25 cm cable which I was working perfect on a different motherboard brand with the same setup. Yet, the PCIe AER entries did not abate for the P5800X (seen as AER entries for 55:00.0 after I moved it to a different slot in the ICY DOCK enclosure). The Intel Optane P4800X works fine though.
I’m beginning to suspect the either motherboard or EMI taking a toll on the signal integrity. I’ve also had brief episodes of Linux complaining about possible EMI while initializing USB ports and SATA drives until I moved some cables around. But why would the primary PCIe slot generate so many AER entries? The Broadcom P411W-32P gave no such issues on the secondary slot, and that’s closest to where all the cables and wires run.
Should I panic or is this what a contemporary system is supposed to tolerate?
Motherboard: ASRock X670E Taichi
CPU: AMD Ryzen 7 7700X
PSU: XPG Fusion 1600 Titanium
EDIT: The ones coming from the GPU went away after adding kernel command line option pcie_aspm=off.
The PCIe 4.0 errors over OCuLink, however, are unresolved.
Well, the PCIe errors from the VM went away. I haven’t figured out the PCIe 4.0 instability, but surely a better cable (from a reputable vendor) should do the trick.
On the other hand, I’ve also run into a new issue where the system randomly resets from time to time―sometimes a day or two apart and sometimes merely an hour apart. RAM stress test passed the 40 hour mark, so it’s probably not that. Running the system for over a day so far without starting the Windows VM (host is desktop Ubuntu) and it seems stable. System load seems to be a non-factor as the resets happened simply with only Microsoft Edge running in the guest.
I enabled 1 GiB huge pages, but that was at least a week before the first random reset. So I suspect a change in the VM config to enable nested virtualization, which I did a few days after I enabled huge pages.
Interesting… I got rid of huge pages in my VM configuration (1 GB pages) and switched to host model. The VM has been up for more than 2 days so far. In comparison, it had crashed thrice in one night only on Monday.
I’d experiment further to find out which trick did it, but I need my system for more useful things at the moment than acting as a crash test dummy.
EDIT: Well, I spoke too soon. I left the Windows VM idle and was using the Ubuntu desktop host when random reset struck. 5 days is much better uptime than several hours, but far less than what I need the machine to be capable of.
I’ve just ruled out power quality issues now. But interestingly, whether huge pages are enabled or disabled makes a difference in the rate of resets. The system could crash within minutes of starting the Windows guest in some cases with huge pages enabled, while it might remain stable for a few days with huge pages disabled.
EDIT: turning ASPM back on in the host fixed the problem. In the guest, I believe the conflicting LSPM setting is causing the issue.
EDIT 2: Spoke too soon about the ASPM/LSPM. I still have huge pages turned on and turning ASPM back on made no difference.
I removed pcie_aspm=off and left the PCIe power settings in the BIOS to their defaults after an update last week. So far, the problems have not come back:
Those entries complaining about PCIe AER have been mostly absent for the past month. I might try re-enabling hugepages again and see if that rocks the boat, but it’s ironic that my problems for the past few months stemmed from trying to mitigate the PCIe AER log spam in the first place.