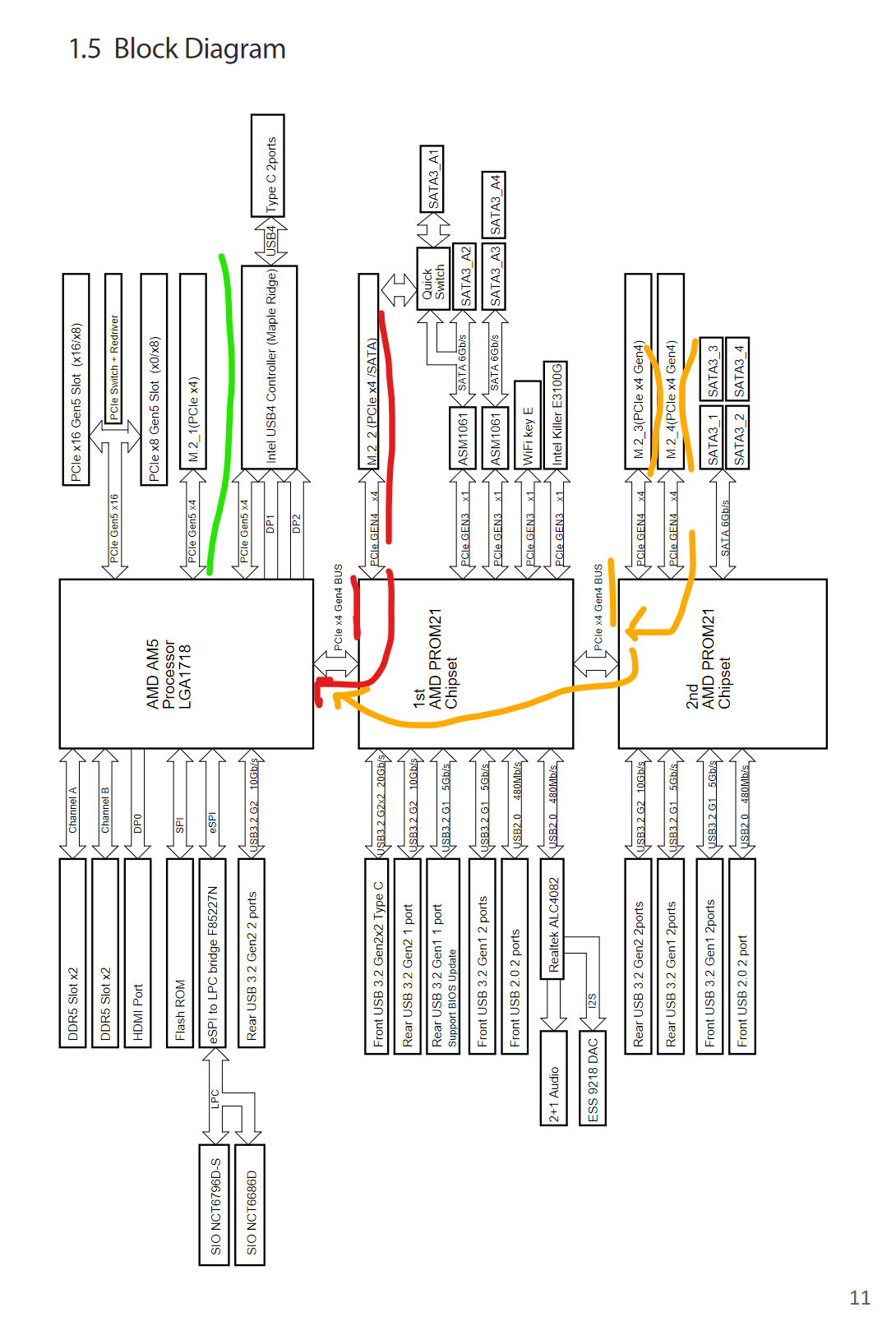
I have a weird issue with using NVMe SSDs on Asrock X670E Taichi.
I have two identical drives: SK Hynix P41 Platinum 2 TB.
One in slot M2_1 and another in slot M2_3 (though same issue is happening with M2_2 too).
One in M2_3 is significantly slower. fio shows consistently lower write speeds for it.
I dug into sudo lspci -vv, and I see this difference.
Faster one:
5c:00.0 Non-Volatile memory controller: SK hynix Platinum P41/PC801 NVMe Solid State Drive (prog-if 02 [NVM Express])
Subsystem: SK hynix Platinum P41/PC801 NVMe Solid State Drive
Control: I/O+ Mem+ BusMaster+ SpecCycle- MemWINV- VGASnoop- ParErr- Stepping- SERR- FastB2B- DisINTx+
Status: Cap+ 66MHz- UDF- FastB2B- ParErr- DEVSEL=fast >TAbort- <TAbort- <MAbort- >SERR- <PERR- INTx-
Latency: 0, Cache Line Size: 64 bytes
Interrupt: pin A routed to IRQ 26
IOMMU group: 33
Region 0: Memory at df500000 (64-bit, non-prefetchable) [size=16K]
Capabilities: [80] Power Management version 3
Flags: PMEClk- DSI- D1- D2- AuxCurrent=0mA PME(D0-,D1-,D2-,D3hot-,D3cold-)
Status: D0 NoSoftRst+ PME-Enable- DSel=0 DScale=0 PME-
Capabilities: [90] MSI: Enable- Count=1/32 Maskable- 64bit+
Address: 0000000000000000 Data: 0000
Capabilities: [b0] MSI-X: Enable+ Count=33 Masked-
Vector table: BAR=0 offset=00002000
PBA: BAR=0 offset=00003000
Capabilities: [c0] Express (v2) Endpoint, MSI 00
DevCap: MaxPayload 512 bytes, PhantFunc 0, Latency L0s unlimited, L1 unlimited
ExtTag+ AttnBtn- AttnInd- PwrInd- RBE+ FLReset+ SlotPowerLimit 75W
DevCtl: CorrErr+ NonFatalErr+ FatalErr+ UnsupReq+
RlxdOrd- ExtTag+ PhantFunc- AuxPwr- NoSnoop+ FLReset-
MaxPayload 512 bytes, MaxReadReq 512 bytes
DevSta: CorrErr+ NonFatalErr- FatalErr- UnsupReq+ AuxPwr- TransPend-
LnkCap: Port #0, Speed 16GT/s, Width x4, ASPM L1, Exit Latency L1 <64us
ClockPM+ Surprise- LLActRep- BwNot- ASPMOptComp+
LnkCtl: ASPM Disabled; RCB 64 bytes, Disabled- CommClk+
ExtSynch- ClockPM- AutWidDis- BWInt- AutBWInt-
LnkSta: Speed 16GT/s, Width x4
Slower one:
57:00.0 Non-Volatile memory controller: SK hynix Platinum P41/PC801 NVMe Solid State Drive (prog-if 02 [NVM Express])
Subsystem: SK hynix Platinum P41/PC801 NVMe Solid State Drive
Control: I/O+ Mem+ BusMaster+ SpecCycle- MemWINV- VGASnoop- ParErr- Stepping- SERR- FastB2B- DisINTx+
Status: Cap+ 66MHz- UDF- FastB2B- ParErr- DEVSEL=fast >TAbort- <TAbort- <MAbort- >SERR- <PERR- INTx-
Latency: 0, Cache Line Size: 64 bytes
Interrupt: pin A routed to IRQ 26
IOMMU group: 30
Region 0: Memory at a0400000 (64-bit, non-prefetchable) [size=16K]
Capabilities: [80] Power Management version 3
Flags: PMEClk- DSI- D1- D2- AuxCurrent=0mA PME(D0-,D1-,D2-,D3hot-,D3cold-)
Status: D0 NoSoftRst+ PME-Enable- DSel=0 DScale=0 PME-
Capabilities: [90] MSI: Enable- Count=1/32 Maskable- 64bit+
Address: 0000000000000000 Data: 0000
Capabilities: [b0] MSI-X: Enable+ Count=33 Masked-
Vector table: BAR=0 offset=00002000
PBA: BAR=0 offset=00003000
Capabilities: [c0] Express (v2) Endpoint, MSI 00
DevCap: MaxPayload 512 bytes, PhantFunc 0, Latency L0s unlimited, L1 unlimited
ExtTag+ AttnBtn- AttnInd- PwrInd- RBE+ FLReset+ SlotPowerLimit 26W
DevCtl: CorrErr+ NonFatalErr+ FatalErr+ UnsupReq+
RlxdOrd- ExtTag+ PhantFunc- AuxPwr- NoSnoop+ FLReset-
MaxPayload 128 bytes, MaxReadReq 512 bytes
DevSta: CorrErr- NonFatalErr- FatalErr- UnsupReq- AuxPwr- TransPend-
LnkCap: Port #0, Speed 16GT/s, Width x4, ASPM L1, Exit Latency L1 <64us
ClockPM+ Surprise- LLActRep- BwNot- ASPMOptComp+
LnkCtl: ASPM Disabled; RCB 64 bytes, Disabled- CommClk+
ExtSynch- ClockPM- AutWidDis- BWInt- AutBWInt-
LnkSta: Speed 16GT/s, Width x4
Note how faster one has
ExtTag+ AttnBtn- AttnInd- PwrInd- RBE+ FLReset+ SlotPowerLimit 75W
...
MaxPayload 512 bytes, MaxReadReq 512 bytes
And slower has:
ExtTag+ AttnBtn- AttnInd- PwrInd- RBE+ FLReset+ SlotPowerLimit 26W
...
MaxPayload 128 bytes, MaxReadReq 512 bytes
Can anyone please explain is the issue with the slot or SSDs are somehow different? Why does one has lower power limit and lower MaxPayload and can anything be done about it?
Thanks!