I’m thinking about whether I should use separated VFIO(PCIe-passthroughed) NIC/SSD/USB Controller/Soundchip for my GPU-passthroughed Windows VM or not. But whether I do that or not, since I’m lack of native PCIe lane, I have to connect those peripherals to PCH PCIe lanes if I’m willing to. I have seen horrible performance of SSD attached to X470 PCH and such, I’m concerning that it’s possibly even worse than using Virtio drivers with peripherals connected to native lanes.
What do you guys think about this?
Only tested with native Windows 10 1903 with an Optane 905P 480 GB and an ASRock X570 Taichi/3700X/64 GB RAM - no differences in performance between CPU- or chipset-supplied PCIe and M.2 slots.
The Optanes are only PCIe 3.0 x4 with 2700 MB/s read and 2400 MB/s write so I don’t know if SSDs that really saturate PCIe 3.0 x4 would show more performance degredation.
(the chipset temperature rose about 10 K during longer loads to mid 60s (°C))
@aBav.Normie-Pleb Which benchmark tool has been used for the test?
Just CrystalDiskMark - changes in random 4K results should indicate latency impacts or do I have a brain fart there?
If you are using multiple NVMe drives you run a little into a CPU load bottleneck in certain scenarios during benchmarking but that happened with CPU-only PCIe lanes in exactly the same way.
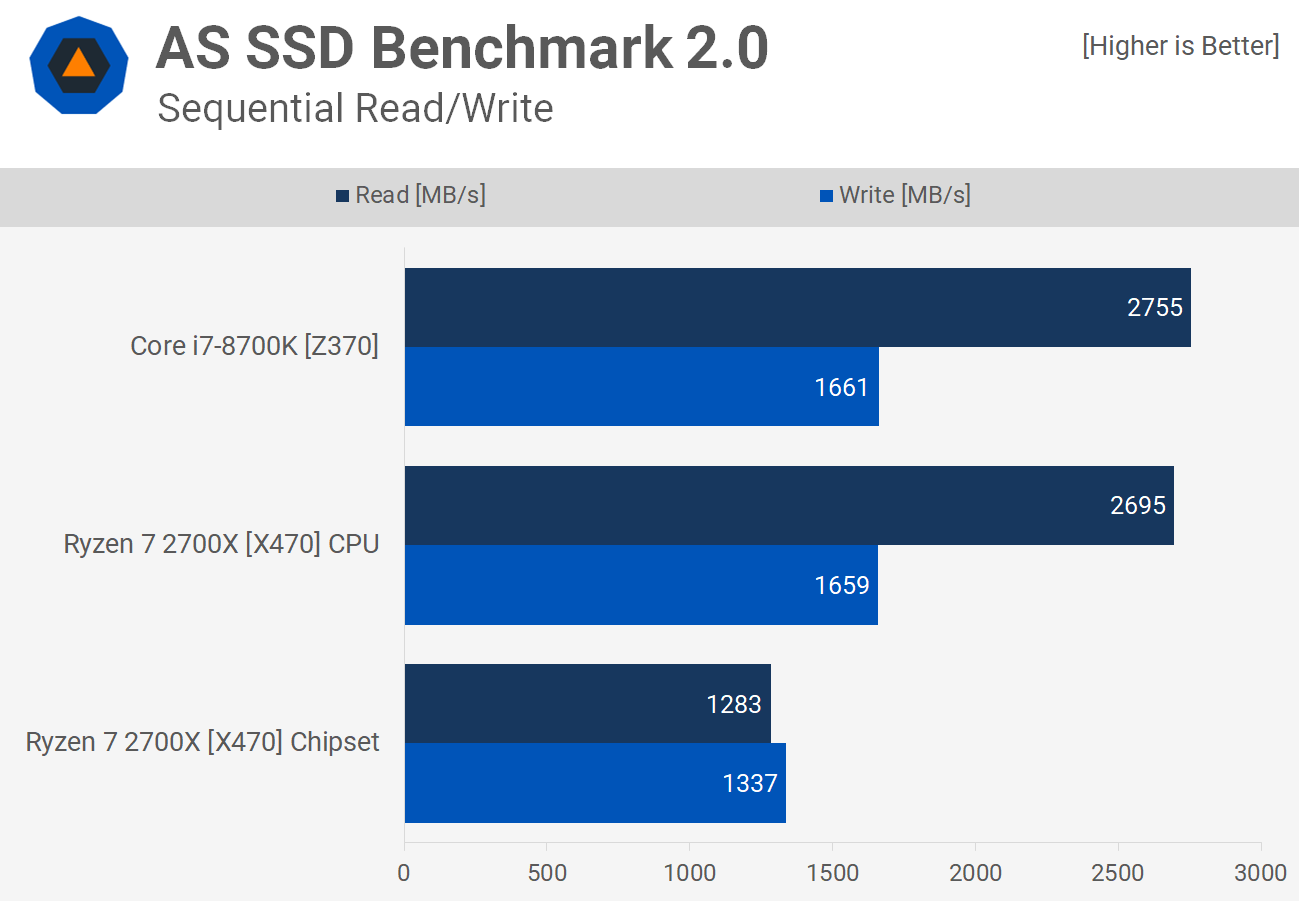
@aBav.Normie-Pleb Well… for the latency it’s good to run AS-SSD benchmark since they have access time result.
Hasn’t AS SSD been buggy af for years especially when using NVMe drives?
@ aBav.Normie-Pleb Umm… I didn’t know that until now  .
.
Just an example:
I personally stopped using AS SSD a few years ago after it sometimes showed results that weren’t even physically possible with the drive’s interface.
(I never use “RAM caching performance optimizer” et al. tools, bare minimum setup)
@aBav.Normie-Pleb
So is it safe to assume that the bad performance on X470 has been fixed now on X570 then?
That there is severe performance hit when using X470-supplied PCIe lanes is quite obvious.
A simplified model how motherboards are constructed:
[Ryzen CPU]—[Interface to Chipset]—[Chipset]—[Chipset PCIe Lanes]—[Your PCIe device]
- When using Ryzen 2000 with X470 it is:
[Ryzen 2000]—[PCIe 3.0 x4]—[Chipset]—[4 PCIe 2.0 lanes]—[Your PCIe device]
- When using Ryzen 2000 with X570 it is:
[Ryzen 2000]—[PCIe 3.0 x4]—[Chipset]—[4 PCIe 4.0 lanes]—[Your PCIe device]
- When using Ryzen 000 with X570 it is:
[Ryzen 3000]—[PCIe 4.0 x4]—[Chipset]—[4 PCIe 4.0 lanes]—[Your PCIe device]
Your performance will always be limited by the weakest link, in case of AMD’s 300/400 chipsets it was the chipset that could only handle PCIe 2.0.
@ aBav.Normie-Pleb I have just realized that X470 only supplies PCIe 2.0 x4 on M.2 now lol. It seems not a general issue with common PCH.
Yes and no:
On Intel since Skylake (2015): The chipset is conntected via PCI 3.0 x4 and can itself supply PCIe 3.0 lanes to devices.
Including X470, AMD was lagging behind, with X570 AMD passed Intel which is still stuck at PCIe 3.0.
Compared to a single PCIe 2.0 lane from X470 the performance per lane with X570 and PCIe 4.0 is almost multiplied by 4.
@aBav.Normie-Pleb What I was concerned most is that, the physical limitation of CPU-PCH-PCIe structure will bring higher latency compared to CPU-PCIe structure. For example, Optane drives like 905P can be used as swap-only devices, functioning like high-capacity intermediate RAM with its low latency compared to NAND-based drive, but it might not work as intended when connected to PCH, because of the higher latency through PCH. That’s the reason why I concerned the access time.
Yes, I got two 905Ps for SLOG/L2ARC purposes, too (although on another system where they’ll have CPU lanes).
I was searching for a method how to benchmark this and a few times during Google-ing sites/blogs said the random 4K numbers could be used to indirectly look at a drive’s latency (if it has a higher latency for some reason, it cannot perform as many random 4K reads per second, for example so it sounds kind of logical even though you don’t get a nice result in micro seconds).
@aBav.Normie-Pleb 4K throughput cannot represent the latency, since throughput achieved by pipelining. See NVMe queuing. Even if the latency is high, it will be hidden by pieplining since each part of NVMe read/write operation executes each different requests so only initial latency will impact the total throughput.
The throughput is not quite important as latency in the situation like you have(optane as a cache drive).
I’m not quite sure I understand it completely (how can random reads be queued?) but then again if I knew exactly how to check on this I wouldn’t have had the issues finding a reliable benchmarking tool.
I’ll get another X570 Taichi within the next few weeks where all PCIe/M.2 slots will be checked with the Optanes.
If you or someone else has a “proper” way to look at the latency (that isn’t AS SSD) I’m happy to help out and deliver the results for each configuration.
@aBav.Normie-Pleb For example, if you are finding 8 4KB block in SSD, with 8-Channel NANDs, and all blocks are distributed in the nand of each channel.
The process will be like this:
- Host CPU issues PCIe messages(NVMe read commands) through NVMe driver, to NVMe drive controller. I/O message will take some clocks to be handed over so I/O message will be queued, and after each message has been sent the interrupt will occured to send another message to the controller. PCIe is bus-based topology with 100MHz base clock sync, so each message would have to wait previous message to be transmitted, but queueing will be done asynchronously.
- The NVMe controller will take each PCIe messages one at a time, then read the content from one of its NAND channel. This will have some times too. Each channel can operate separately, so the controller will issue read command to each channel without waiting previous channel read.
- After getting the result of reading one channel by the controller, it will send content via PCIe DMA to host system main memory. This will be synced to PCIe base clock 100MHz, but queuing of each command to send result to main memory from the drive will be done.
So in this case, the throughput of reading total 8 blocks will be something like 1/(time of reads commands + time of DMA access + time of “one” channel read time + alpha(delayed by command waiting/channel response waiting)).
I don’t know the benchmark tool except ASSSD to check access time. Anyone who knows?
I’m not contesting anything you wrote but have a question:
How likely is it that 4K random reads are spread evenly over all 8 channels so that the drive can work on them simultaneously?
I don’t know if it helps - here is an example of Crystal Disk Mark results with 905P 480 GB and a 3700X’s CPU lanes:
CrystalDiskMark 6.0.2 x64 © 2007-2018 hiyohiyo
Crystal Dew World : https://crystalmark.info/
-
MB/s = 1,000,000 bytes/s [SATA/600 = 600,000,000 bytes/s]
-
KB = 1000 bytes, KiB = 1024 bytes
Sequential Read (Q= 32,T= 1) : 2765.506 MB/s
Sequential Write (Q= 32,T= 1) : 2441.255 MB/s
Random Read 4KiB (Q= 8,T= 8) : 2423.971 MB/s [ 591789.8 IOPS]
Random Write 4KiB (Q= 8,T= 8) : 2455.971 MB/s [ 599602.3 IOPS]
Random Read 4KiB (Q= 32,T= 1) : 514.951 MB/s [ 125720.5 IOPS]
Random Write 4KiB (Q= 32,T= 1) : 463.977 MB/s [ 113275.6 IOPS]
Random Read 4KiB (Q= 1,T= 1) : 253.809 MB/s [ 61965.1 IOPS]
Random Write 4KiB (Q= 1,T= 1) : 235.069 MB/s [ 57389.9 IOPS]
Test : 1024 MiB [D: 0.0% (0.1/447.1 GiB)] (x5) [Interval=5 sec]
Date : 2019/07/29 20:43:33
OS : Windows 10 [10.0 Build 18362] (x64)
It’s just assumption, in real life queue/thread/distribution of block in the nands will be varying. But all I want is that even 4KQ1T1 throughput will not represent the latency because I don’t think CDM is desigened to wait each 4K block to be round-triped.