So I was reading Anandtech’s AMD 4900 HS CPU review.
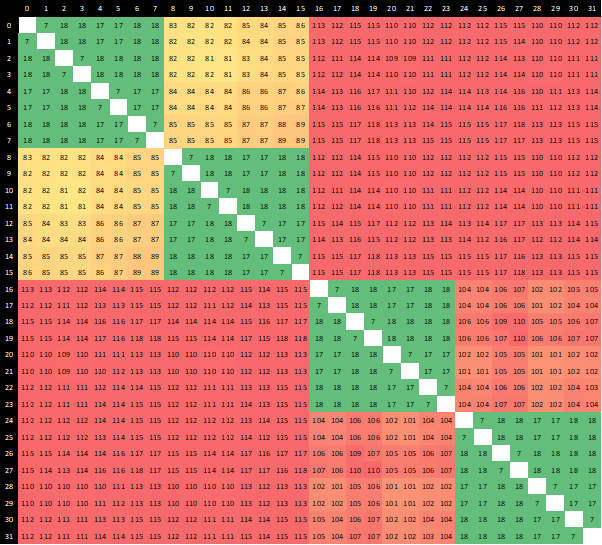
And Dr. Ian Cutress’ Inter-Core Latency Chart doesn’t make any sense.
I was under the impression that once you reach out to any CCX outside of your own, they would have about the same latency like it is shown here for Zen 2 based CPU’s like the (Ryzen 9 3900X)
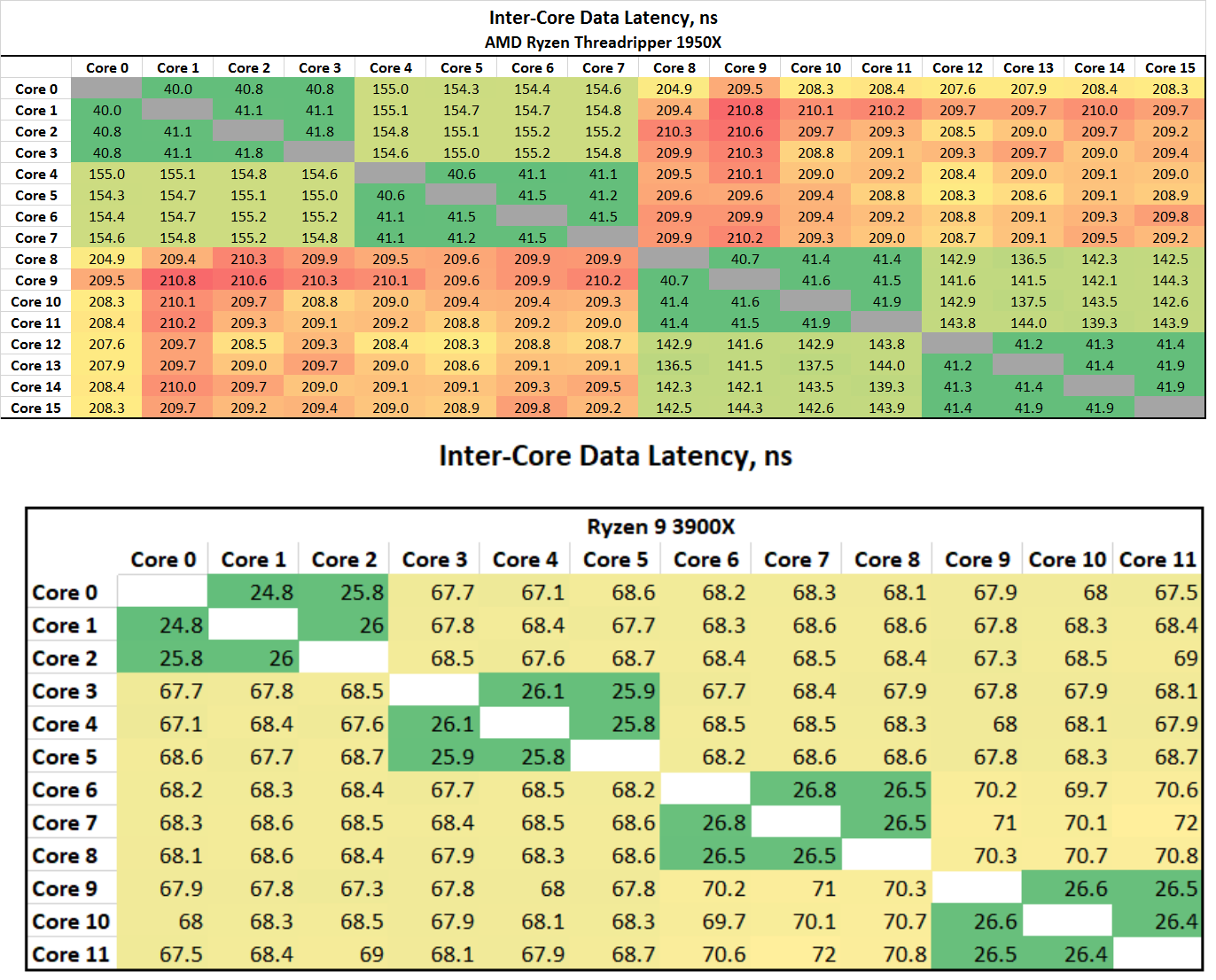
Does Wendell or anybody else have the ability to test Inter-Core latency across all the cores, especially on Many CCD / CCX Ryzen/ThreadRippers/EPYC chips.
Theoretically, I was lead to believe that all CCX -> CCX communication for Zen 2 should have similar latency once it passes through the IO Die and onto another CCX within another CCD.
The Latency should be similar even, if it’s 16 core Zen 2 CPU or 64 core Zen 2 CPU, given identical IF (Infinity Fabric) Speed, the latency’s between cores should be similar, no matter the positioning of the CCX on another CCD, right?
Or is Dr. Ian Cutress correct in that there is an extra domain of penalty for trying to access the CCX that is on another CCD? and you only get less of a penalty for accessing the CCX that is on same CCD?
I wonder if Wendell could test this on his 64 Core ThreadRipper/EPYC CPU?
I am not familiar with the x86 assembler language but pretty sure that a direct inter-core communication don’t exist in real world software. I am under the impression that communication is always indirect via variables stored on memory and that latency is minimized by the caches.
I think it would be a very weird program running on one core trying to access register values on another core. And far less common a core waiting for the output directly for an instruction executed on another core (this shouldn’t even exist).
So I believe that those latencies probably are cache or memory. Not true inter-core communication. That would explain that for cores in the same CCX / CCD latency it is for their local cache. And inter CCX/CCD cache access would take the infinity fabric plus cache latency.
I thought it was threads on one core communicating with threads on another core. The latency between that is what they were testing to probe the latency’s across actual cores?