This is a bit of a long story to get to the point, which is probably buried somewhere in all this rambling, but it was a long and weird way to get to where I am here today.
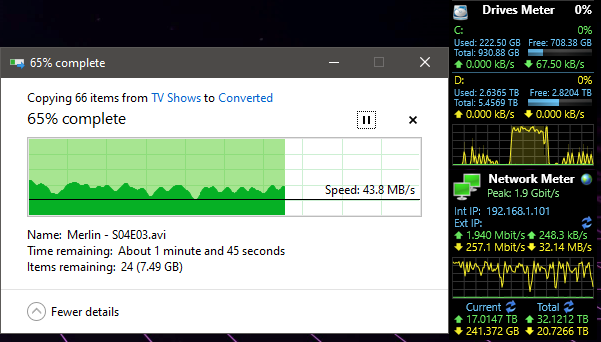
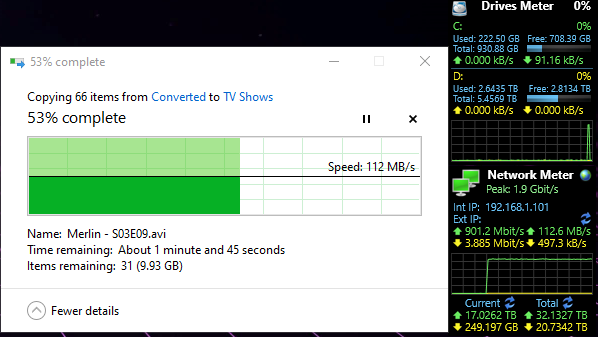
So the other week, I went to move files to a server I’ve been running since 2012 as a home server and noticed my write speeds from another computer to the server to be utterly unacceptable garbage. Thankfully I take screenshots, because I was asking a friend if it was weird, though we both concluded at the time it might just be a dying drive. It was an ooold setup, talking a copy of windows server 2008 R2, an actual Areca 1220 or whatever the 8 port raid card was called, /and in raid off the card itself/ old, so there could have been anything wrong with it(You can’t get SMART off raided drives, though Areca’s little web interface did give /their/ idea of SMART from all those years ago, I can give you a hint, it’s shite). Wven if all it did was sit in a corner, suck, and spit files out, or be used via video files being played over the network(Not over Plex, just purely MPC/VLC → the file itself.mp4). I was doing some h265 encodes with handbrake, pulling from the server to my computer, then deleting what was on the server, and moving the converted, and usually far smaller for the same quality files(talking xvid to h265, and in most cases it shrank it by half or more, yay.) Anyways, this was the result that had me alarmed.
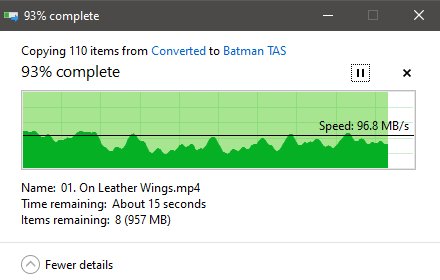
It’s just sort of grown over the years, and because I never had enough spare ‘extra’ space, I was never able to do what I really wanted and tear it down to rebuild it properly. So I had to take the 'patch it with scotch tape and prayers to the digital gods approach. I went to debugging what could possibly be wonky on it with what I could reasonably do to an outdated way of hording data. Decided out of all the things I’d never actually done to the raid, and I do mean since it’s build and many replaced drives later… was run a defrag on it. I honestly did it more as a laugh you know? To punish the drives for causing problems at a time when I just can’t afford things, make them take all the data and like it. The results were shocking. But in the time it was going to take to defrag 60TB of drive space, even if only a third of it was being used, I pulled the trigger on other plans.
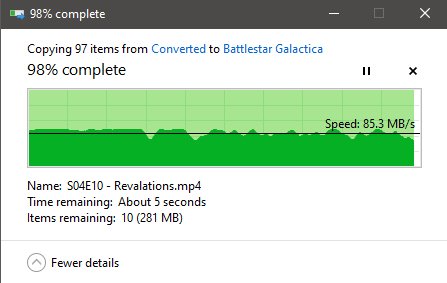
That was the result! After the windows based defrag, it seemed to really help. Unfortunately that was only temporary, and it was still wonky, and as annoying as it all was, we’re talking 8 drives in a raid-6 configuration, the baseline sequential write and read of an array like that should have been /far/ above what lame ass 2001 T1000 home networking can do. So again, I’m scratching my head on why throughput wasn’t capped to 120MB/s like always when pushing data to the server. The trigger I ended up pulling caused some headache, as I bought two referbished drives, 10TB HGST drives, I’d done so originally to update the server to all 10TB drives. At that point, the only thing that was going to slow me down was leeching all the data off the server, it was time to get all the data off, backed up on 2 spare drives, and tear it apart.
The server went from:
Old i7-920
Old x58 msi motherboard
Old DDR3 that totaled up to 24gb(six sticks on those old boards)
Old Kingston SSD for boot, previously mirrored straight from an 80gb WD platter drive
Old Areca 8 port sata card
Old PCI fanless GPU, literally so it would boot, and I could debug it.
8 HGST 10tb drives, the super cheap HUH721010ALE600 ones you can get referbished
The replacement from parts in the garage
Ryzen r7-1700 non-x(I actually had both, decided non-x for power saving, and turned the eco stuff on)
x370 msi pro carbon red LED barf from back when I pre-ordered ryzen(yup, I was one of the crazy people)
32GB DD4 3600mhz g.skill
Nvidia GTX560, non-Ti, there wasn’t much to pick from that didn’t have multiple PCIe power connectors, it had a single six pin. I was kicking myself for forgetting I was using a PCI gpu, so now that adds one more fan to clean! FFFS!
LSI Logic SAS 9207-8i Storage Controller LSI00301
8 HGST 10tb drives, the same ones, because I’m mentally deficient, and the spare two I bought were holding everything on them I’d taken off the previous build, just waiting to be put back on.
4 samsung evo 250GB sata drives <— I run supercache(Thanks Linus and Wendle, I’m a firm believer in tiered storage now. I used to run ramdrive programs for games, but then games got too damn big.)
1 intel 512gb nvme drive for its boot/OS
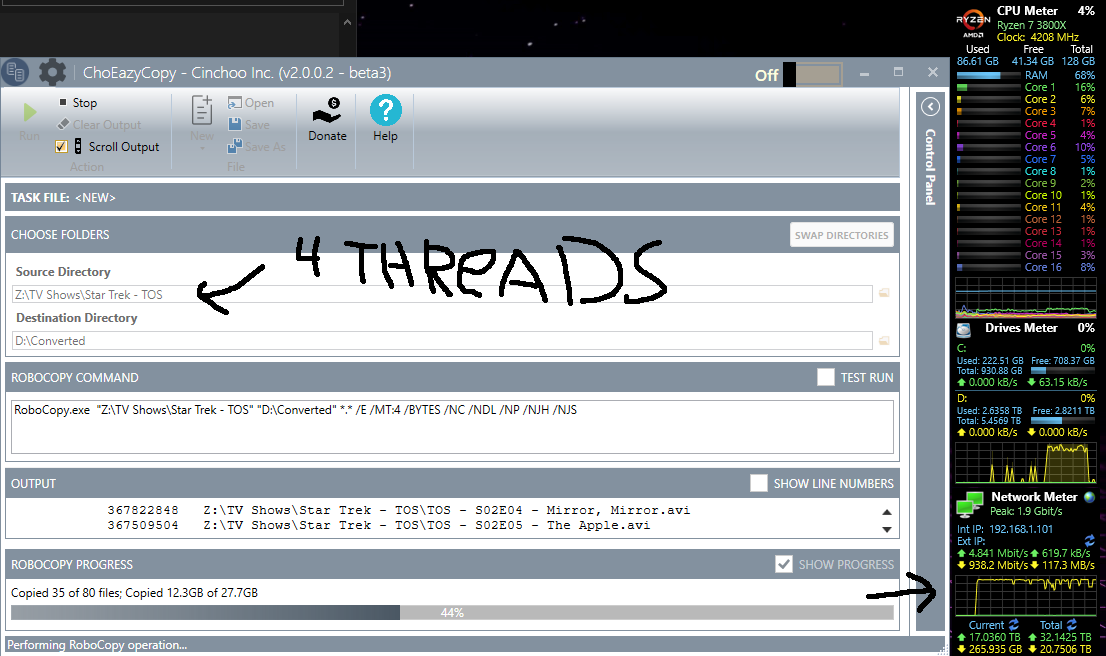
I wanted to move away from windows forever ago with the server. I couldn’t because of the raid card. So long as I didn’t have the areca card in the computer, I could replace motherboards, and cpu’s, and just pop the raidcard back in, and poof, data’s there. So it went from an old tyan K8WE that I got tired of replacing capacitors to an amd phenom x6 capable board(don’t recall, it burnt out on me), and finally the last which was somewhere around 2012 which ended up being its last for a long while. All running windows server 2008, yeah, I can hear the vomiting noises you’re making, it really is that bad. Anyways, I put Truenas core on it after poking it with a stick in a virtual machine and deciding ‘yup, this’ll do’ by making a fk’ load of 20gb drives in VMware, and tied it to the OS, toyed around with how the raid and sharing worked(it was at this point, I wanted to claw my eyes out, forgot how bitchy linux is on permissions, and not like good ol’ windows, like that corner prostitute who will open up to anyone, so long as you got the right password.), and so far as setting the computer, and Truenas up? It was so simple I was done before I knew it, and fighting the linux permissions to let me put the shit where I wanted it so /everyone/ on the lan saw /one/ spot to get their files, and it not have a hissy fit. When /that/ was all said and done; eight HGST 10tb drives in ZFS-2 whatever raid-6 is, and I had turned the 4 seagate Evo’s into 1TB of cache because fk it right? I started moving files!
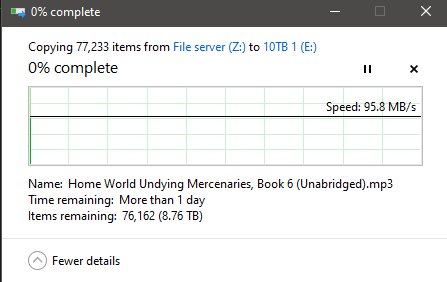
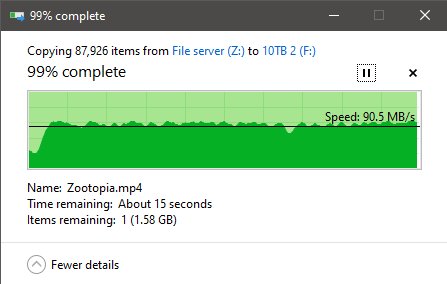
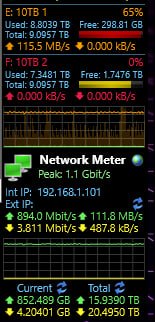
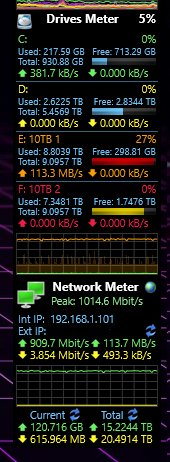
Honestly this was my face seeing all of that.

WORTH IT!
I know! I know! The terabyte of Tier-2 CACHE drives, and TrueNas’s desire to use any and all ram to act as Tier-1 cache was doing /all/ the work! But hey! I couldn’t have RAM or FOUR random sata drives act as a cache drive in windows 2008 while jamming files into it with a boot! Let me have my poor man’s moment of maximum throughput bliss on crappy gigabit home network! And the fact things were working as advertised! -.- /s
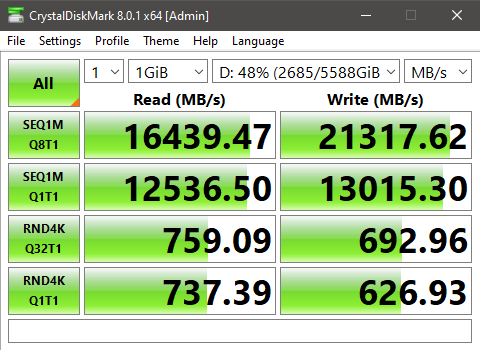
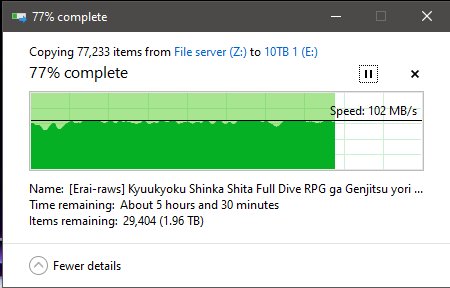
But then… I /knew/ all of that had been cache, and that I was still dealing with a drive that was possibly going bad. So out of morbid curiosity, I grabbed something that wouldn’t be in ram, or cache.
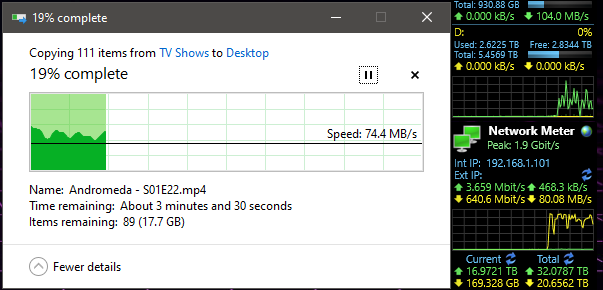
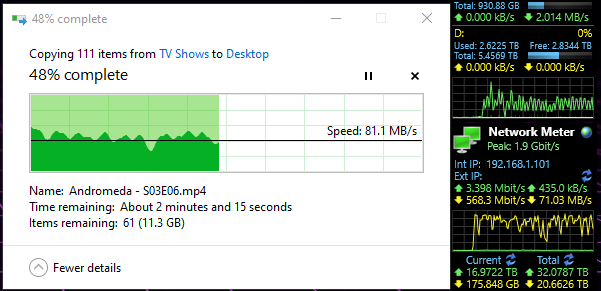
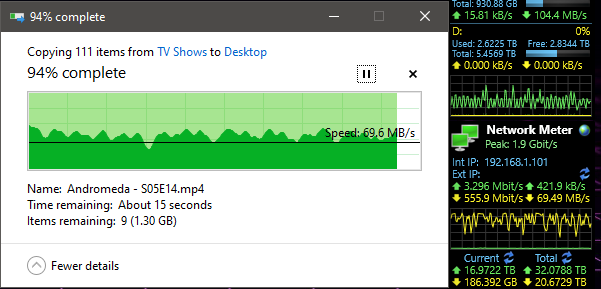
And… wonky when pulling from server to any computer on the network… why can’t I get maximum throughput?! I even performed a smartctl –t long to all of the HDD’s! And I’ve got the logs of those if anyone wants them, however I can tell you right now, smartctl said passed for all eight drives. head desks repeatedly Why can’t I just have maximum throughput both ways? ARG! I’m /PRETTY FREAKING SURE/ I should be slammed to the maximum on my in and outs on that server over a single gigabit connection! So am I just a fk’ing idiot and missing something here? Or after all of this TL;DFR rant, is there actually a problem drive in there hamstringing the group for being ‘a touch slow’??? Arg this is so frustrating!