A (totally unofficial) Conversation about Relative ZPool Performance
DISCLAIMER:
I am not an authority figure on ZFS. I’ve made several generalizations and assumptions here that may not be accurate. Please, if you find discrepancies, join the conversation and help correct them. This is a collaborative effort for the benefit of all.
Introduction:
Been a member of this community for a while, and often I notice newcomers seeking digestible insights into ZFS. So, here’s my attempt to shed some light. Feedback from forum regulars and ZFS experts would be greatly appreciated! ![image] I’ve standardized everything around 8VDEVs for simplicity, but there’s really no reason why I chose that number.
Assumptions:
Baseline HDD Performance: An 8-drive stripe equals 100% performance, equating to 1,200 MiBps for both read and write. These figures assume sequential operations, averaging ~150 MiBps from a single hard drive.
Baseline HDD IOPS: An 8-drive stripe equals a baseline of 800 IOPS for both read and write. Averaging ~100 IOPS from a single hard drive.
Baseline SSD Performance: An 8-drive stripe equals 100% performance, equating to 4,000 MiBps for both read and write. These figures assume sequential operations, averaging ~500 MiBps from a single Solid State Drive.
Baseline SSD IOPS: An 8-drive stripe equals a baseline of 400,000 IOPS for both read and write. Averaging ~50,000 IOPS from a single Solid State Drive.
RAIDZ3 Assumptions:
- Sequential Read: 90% of an 8-drive stripe.
- Sequential Write: 60% due to three parity calculations.
- Random Write: 50%.
- Random IOPS: 50%.
RAIDZ2 Assumptions:
- Sequential Read: 90% of stripe (rounded down from 92%).
- Sequential Write: 65%.
- Random Write: 55%.
- Random IOPS: 55%.
RAIDZ1 Assumptions:
- Sequential Read: 95% of stripe.
- Sequential Write: 75%.
- Random Write: 65%.
- Random IOPS: 65%.
Mirroring Assumptions:
- Read: 100% (same as stripe).
- Sequential Write: 90%.
- Random Write: 80%.
- Random IOPS: 80%.
Sequential Write Performance (MiBps) - Total Disks:
ZFS HDD Performance Comparison:
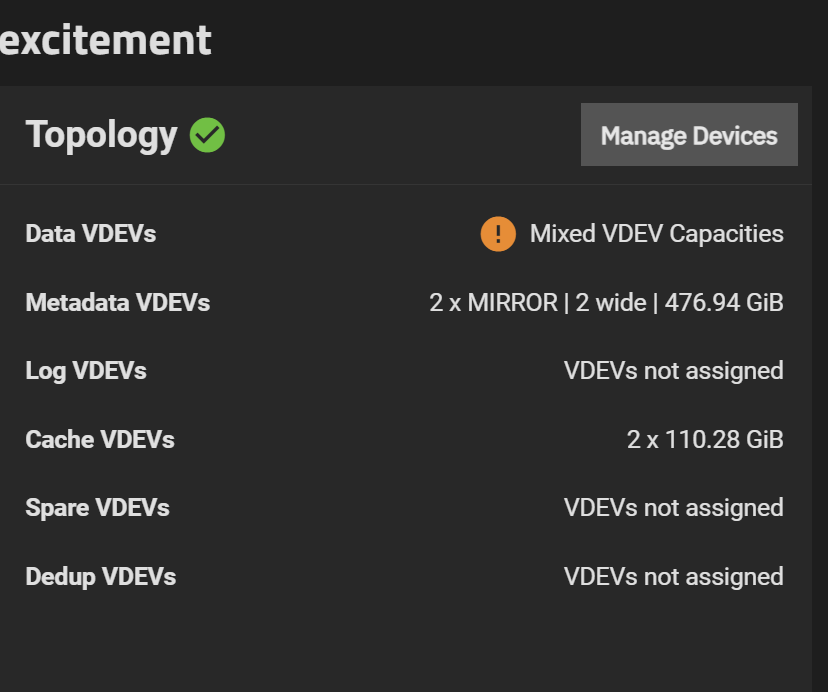
ZFS Performance and capacity is d ependent each VDEV, not of each disk
This represntation is designed to more clearly show that the number of disks required to maintain baseline performance grows quickly
Read Performance (MiBps) - Total Disks:
|------------------ 100% (600 MiBps)
|█████████████████████████ 4 Drive Stripe (4 disks)
|███████████████████████ 4 vdev Mirror (8 disks)
|██████████████████████ 4 vdev RAIDZ1 (12 disks)
|█████████████████████ 4 vdev RAIDZ2 (16 disks)
|████████████████████ 4 vdev RAIDZ3 (20 disks)
Sequential Write Performance (MiBps) - Total Disks:
|------------------ 100% (600 MiBps)
|█████████████████████████ 4 Drive Stripe (4 disks)
|███████████████████████ 4 vdev Mirror (8 disks)
|██████████████████████ 4 vdev RAIDZ1 (12 disks)
|█████████████████████ 4 vdev RAIDZ2 (16 disks)
|████████████████████ 4 vdev RAIDZ3 (20 disks)
Random Write Performance (MiBps) - Total Disks:
|------------------ 100% (600 MiBps)
|█████████████████████████ 4 Drive Stripe (4 disks)
|███████████████████████ 4 vdev Mirror (8 disks)
|██████████████████████ 4 vdev RAIDZ1 (12 disks)
|█████████████████████ 4 vdev RAIDZ2 (16 disks)
|████████████████████ 4 vdev RAIDZ3 (20 disks)
Read IOPS - Total Disks:
|------------------ 100% (400 IOPS)
|█████████████████████████ 4 Drive Stripe (4 disks)
|███████████████████████ 4 vdev Mirror (8 disks)
|██████████████████████ 4 vdev RAIDZ1 (12 disks)
|█████████████████████ 4 vdev RAIDZ2 (16 disks)
|████████████████████ 4 vdev RAIDZ3 (20 disks)
Sequential Write IOPS - Total Disks:
|------------------ 100% (400 IOPS)
|█████████████████████████ 4 Drive Stripe (4 disks)
|███████████████████████ 4 vdev Mirror (8 disks)
|██████████████████████ 4 vdev RAIDZ1 (12 disks)
|█████████████████████ 4 vdev RAIDZ2 (16 disks)
|████████████████████ 4 vdev RAIDZ3 (20 disks)
Random Write IOPS - Total Disks:
|------------------ 100% (400 IOPS)
|█████████████████████████ 4 Drive Stripe (4 disks)
|███████████████████████ 4 vdev Mirror (8 disks)
|██████████████████████ 4 vdev RAIDZ1 (12 disks)
|█████████████████████ 4 vdev RAIDZ2 (16 disks)
|████████████████████ 4 vdev RAIDZ3 (20 disks)
ZFS HDD Performance Comparison for 12 Disks (Logarithmic Scale):
***** Normalized to 12 disks instead of to a VDEV layout*
Using a Logarithmic Scale to emphasize the performance dropoff for different topologies
Read Performance (Logarithmic Scale):
|------------------ 100% Baseline
|█████████████████████████ 12 Drive Stripe
|███████████████████████▒ 6 vdev Mirror
|█████████████████████▒▒ RAIDZ1 (3 vdevs of 4 drives each)
|███████████████████▒▒▒ RAIDZ2 (3 vdevs of 4 drives each)
|█████████████████▒▒▒▒ RAIDZ3 (3 vdevs of 4 drives each)
Sequential Write Performance (Logarithmic Scale):
|------------------ 100% Baseline
|█████████████████████████ 12 Drive Stripe
|███████████████████████▒ 6 vdev Mirror
|████████████████████▒▒▒ RAIDZ1 (3 vdevs of 4 drives each)
|██████████████████▒▒▒▒ RAIDZ2 (3 vdevs of 4 drives each)
|████████████████▒▒▒▒▒ RAIDZ3 (3 vdevs of 4 drives each)
Random Write Performance (Logarithmic Scale):
|------------------ 100% Baseline
|█████████████████████████ 12 Drive Stripe
|████████████████████▒▒▒ 6 vdev Mirror
|██████████████████▒▒▒▒ RAIDZ1 (3 vdevs of 4 drives each)
|████████████████▒▒▒▒▒ RAIDZ2 (3 vdevs of 4 drives each)
|██████████████▒▒▒▒▒▒ RAIDZ3 (3 vdevs of 4 drives each)
IOPS (Logarithmic Scale):
|------------------ 100% Baseline
|█████████████████████████ 12 Drive Stripe
|█████████████████████▒▒ 6 vdev Mirror
|███████████████████▒▒▒ RAIDZ1 (3 vdevs of 4 drives each)
|██████████████████▒▒▒▒ RAIDZ2 (3 vdevs of 4 drives each)
|████████████████▒▒▒▒▒ RAIDZ3 (3 vdevs of 4 drives each)
ZFS Topologies Visualization 
ZFS Topologies Visualization
Legend:
![]()
![]() = Disk
= Disk
![]()
![]() = Parity/Mirror
= Parity/Mirror
─────────────────────────────────────────────────────────────────────────────
Striping (4 Drives)
| ![]() |
| ![]() |
| ![]() |
| ![]() |
|
Total Drives: 4
Pool Size: 4TB
Raw Size: 4TB
─────────────────────────────────────────────────────────────────────────────
Mirroring (4 vdevs of 2 drives each)
| ![]()
![]() |
| ![]()
![]() |
| ![]()
![]() |
| ![]()
![]() |
|
Total Drives: 8
Pool Size: 4TB
Raw Size: 8TB
─────────────────────────────────────────────────────────────────────────────
RAIDZ1 (3 Disks per vdev, 4 vdevs wide)
| ![]()
![]()
![]() |
| ![]()
![]()
![]() |
| ![]()
![]()
![]() |
| ![]()
![]()
![]() |
|
Total Drives: 12
Pool Size: 8TB
Raw Size: 12TB
─────────────────────────────────────────────────────────────────────────────
RAIDZ2 (4 Disks per vdev, 4 vdevs wide)
| ![]()
![]()
![]()
![]() |
| ![]()
![]()
![]()
![]() |
| ![]()
![]()
![]()
![]() |
| ![]()
![]()
![]()
![]() |
|
Total Drives: 16
Pool Size: 8TB
Raw Size: 16TB
─────────────────────────────────────────────────────────────────────────────
RAIDZ3 (5 Disks per vdev, 4 vdevs wide)
| ![]()
![]()
![]()
![]()
![]()
![]() |
| ![]()
![]()
![]()
![]()
![]()
![]() |
| ![]()
![]()
![]()
![]()
![]()
![]() |
| ![]()
![]()
![]()
![]()
![]()
![]() |
|
Total Drives: 20
Pool Size: 8TB
Raw Size: 20TB
─────────────────────────────────────────────────────────────────────────────