Strangely, my command line C program (it processes two .csv files, no graphics) runs ~25% slower on my just-built Ryzen 7950x3d system than on my older and much-lower-spec Intel i7-12700T system. It should run much faster. (details below)
Since I need ECC, I’m considering returning both the 7950x3d CPU and the Asus ProArt X690E Creator motherboard, and building a W680 system, probably with an Intel i9-13900 CPU and an Asus W680-ACE motherboard.
Before doing so, and since the performance difference is a mystery, it would really help to do a remote-access test (max 15 minutes) on an existing W680 system, to confirm that running on a W680 system will be an improvement.
So any offers would be appreciated!
The test requirements are: a W680 motherboard, 12th or 13th gen Intel CPU (faster than an i7-12700T), 8GB RAM or more, 50MB of disk space on a M.2 Gen4 SSD (or larger/faster) , and Windows 10/11.
The Details
Although the program is simple, it must run fast – because in normal use it processes large files (~150GB). For simply testing speed (in records/second), 50MB is plenty.
As shown below, the i7-12700T (passively cooled) outperforms the 7950x3d.
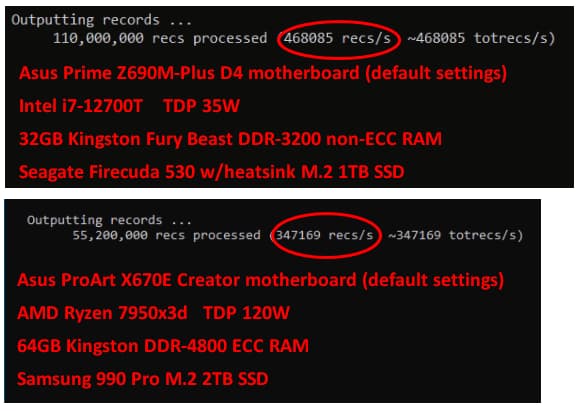
To find out why the 7950x3d is slower, I’ve tried several ideas without success, such as:
- replacing the ECC RAM with non-ECC RAM: hardly noticeable difference
- running Geekbench 6 on both computers: the 7950x3d returns a higher score
- profiling (with Visual Studio’s profiler) the program on both computers (see below)
- overclocking the 7950x3d: a slight improvement, the 17-12700T is still much faster
The profiler shows slight differences in which low-level library functions are called (the same .exe is used on both computers). This is the only clue that might explain the difference. Perhaps the low-level library functions detect which CPU is being used, and execute CPU-specific code. If so, I’m not able to recode those functions.