I would be really curious to see the performance of fake UMA mode in Windows. You can do this by virtualizing windows in KVM, handing the guest all the cores via AMD-V and letting Linux handle affinity and such.
1 Like
@wendell Can you get a trial version of Windows Server 2019 and verify if this performance regression exists there? I have a suspicion Windows Server will not have this regression.
Sure but if 19 doesn’t it will be the first one not to have it.
1 Like
What an awesome video…even a techie wanna be like myself was able to understand a good chunk of it. Having said that, why does this not impact the 1950x? I had thought the design of the gen 2 chips was basically the same, but with improvements. And so the fundamental issue remains?
1 Like
I suspect it does. But it is more subtle. I can run blender on Windows and render a project. Then on linux render the same project and it is a little faster.
I only have a sample size of me and a ryzen 1700 with 2 CCX’s. I think if we crowd sourced data it would start to show.
Not blender per say but how the windows kernel behaves vs linux.
AMD have brought many cores to the desktop. Intel is coming along kicking and screaming. Windows kernel is starting to show some warts that need attention.
1 Like
Yep, and really… I can’t blame Microsoft. Even if you know this issue exists up until a few years ago it was really really really meh. Intel sure as fuck was not going to release this many cores at a reasonable price to the masses so with a multitude of things to accomplish why bother resolving it? Now hopefully someone at Microsoft sees this and investigates because it will need addressing (especially if Ryzen 3XXX rumors are true).
1 Like
This is actually a PROVEN case where too much thread shuffling can actually cause massive performance regression! Great job Wendell!
Now we just need a fix for x264 and x265 massive multithreading performance. That’s still not utilizing the 2950X or 2990WX fully cause there’s so many threads. Once that’s fixed, streamers will buy Threadripper in droves for their 2nd systems in a dual system setup.
Imagine realtime veryslow 1080p60 performance on Threadripper when the thread utilization is fixed for x264…
A real tech site … How novel.
Just have two encoding streams going at the same time? Or 4 or whatever it takes.
No, the point is to have enough utilization to encode 1 veryslow stream/recording in real time with no buffer or latency. Or better, placebo… or veryslow at 144hz.
1 Like
Okay, got you.
But what if AMD teases a 64c/128t part at CES2019?
More the reason to optimize x264 and x265 massive multithreading. More logical threads on the host = diminishing returns on encoding power with the current thread management setup in x264 and x265.
2 Likes
Michael Larabe had already shared Windows server 2019 results and it does appear to have the same issue. Once the threads are over 32 you can clearly see performance degrades in Windows compared to Linux. I would have thought Microsoft would have addressed this already in the server space. This may be a really big find if it forces Microsoft to update its kernel.
https://www.phoronix.com/scan.php?page=article&item=2990wx-linwin-scale&num=4
I wonder if this can be replicated in a 4 node xeon server. The memory timings might be too slow to actually notice.
https://www.indigorenderer.com/benchmark-results?filter=cpu
There’s a 2990 in the top 5 for IndigoBench CPU running Windows 10 all of the sudden .
3 Likes
I think the starting idea is sound - letting high-level set ideal cores for each thread - especially if cores aren’t equal in memory latencies and the scheduler is aware of the CPU topology and the relative requirements of the thread. Where it breaks is when only a portion of cores are ever assigned as ideal cores.
My guess: One part of the scheduler sees some cores underutilized and others loaded with 100% and multiple threads, so moves a thread. Another part of the scheduler sees a thread running in a core that’s not its ideal one and moves it back.
In a truly pathological case the scheduler moves the thread back very quickly, leaving no time for caches to update and provide any data, so the thread doesn’t manage to have any work done during its detour.
I’m curious and probably missing the mark here but while this was specific for the threadripper, but would this tool be of any benefit for those on ryzen?
2 Likes
The system next to the whiteboard at 20:12, looks familiar.
Those heatsink+fan modules and the Supermicro SC732, could that be @wendell’s Talos II?
1 Like
With virtual machines how many processes are running on an actual 32 thread box, in the enterprise, on Windows.
Also this is the first time in quite a while that Intel has had any real competition in the enterprise so its quite possible no one really noticed the degradation.
2 Likes
I have refactored it to now support Ideal CPU allocation and is fully NUMA Node aware.
Was able to use bcdedit to emulate NUMA node’s - appears MS supports this for driver development purposes (mostly) … 8700K ends up becoming 2 NUMA nodes, with 4 cores per node (2x HT, 2x Real)
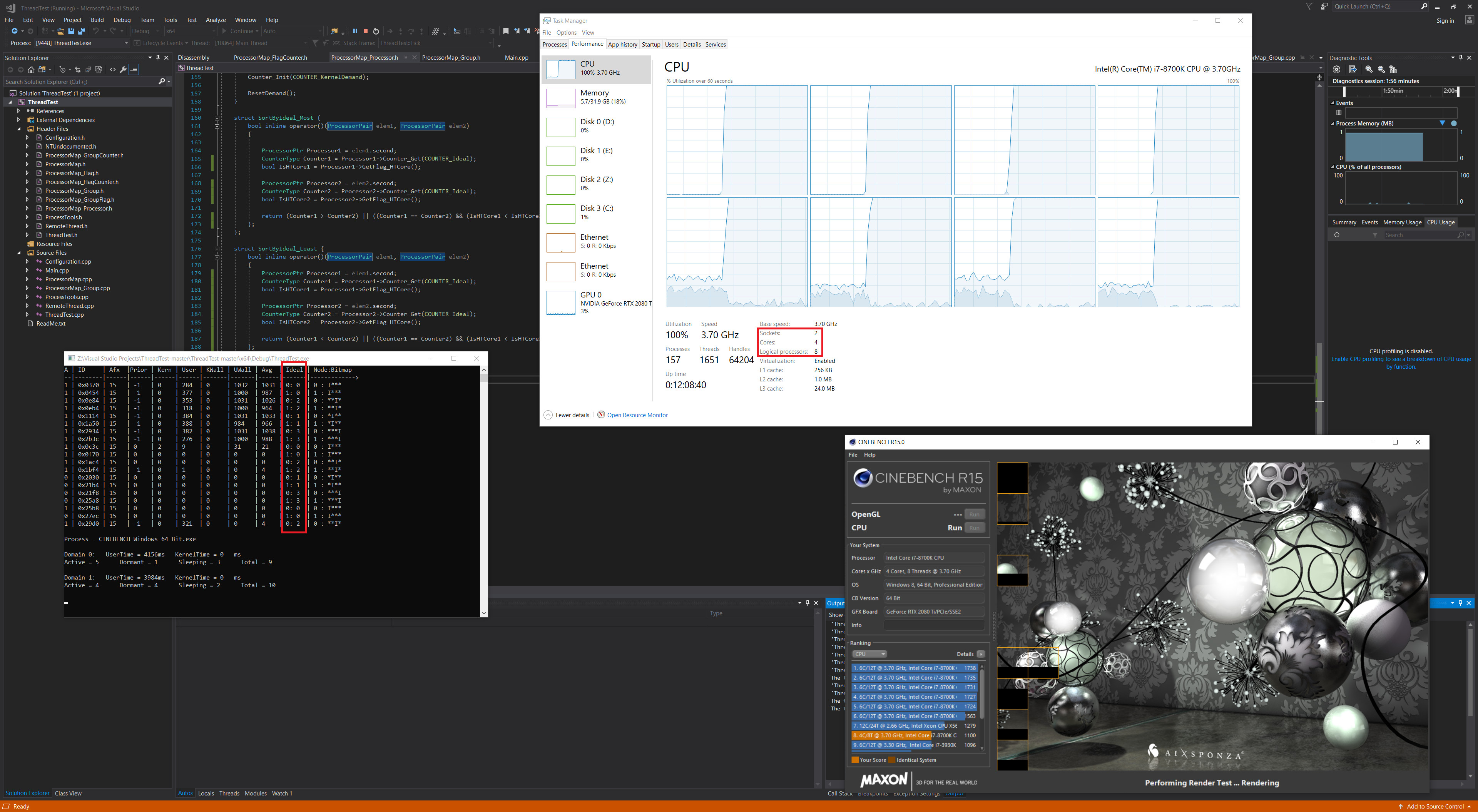
It keeps track of (counters) and allocates in a round robin basis “Ideal” and “threads” against groups, then cores, algorithm is easily changeable … all the cores for a group get thrown into a std::set with a custom comparator on a allocation request.
There is some difficulty in deciding how it should decide which threads effectively have priority during the core allocation routine (currently happening every second)
The final thing to finish is core/thread stickyness so that it attempts to re-allocate the same core(s) to the same thread the next allocation round.
3 Likes