Sweet, his stuff is on Kobo or even direct as epub or PDF! Happy I won’t need to go through Amazon
2 Likes
Yes, I bought some of his books via Kobo. The older ones were DRM free so I was able load them into Calibre. His latest FreeBSD Mastery book has DRM on it unfortunately, not the end of the world… but I hate DRM!
Call me when you’re actually using disk space
4 Likes
While I am generally loathe to have anything to do with reddit, I have found the /zfs/ and /datahoarder/ subs are worthwhile non-political communities to keep an eye on if ZFS and storage are a significant part of your technological life.
Jim Salter (mercenary_sysadmin on reddit) is also a fantastic ZFS resource who runs ZFS in production, and routinely tests various aspects of using it in practice:
https://jrs-s.net/author/admin/
Places like those are also where you’ll come across practical and more recent information like
- Don’t use dd (or Bonnie++. Iozone may be ok), use fio for benchmarking because it’s multithreaded and can actually simulate random 4K read/writes”. It’s also nontrivial to use. Things which are trivial to use are probably giving you something weird. See https://linoxide.com/linux-how-to/measure-disk-performance-fio/ https://support.binarylane.com.au/support/solutions/articles/1000055889-how-to-benchmark-disk-i-o
- Don’t benchmark with /dev/zero/ because ZFS by default (lz4) compresses zeros so your typically benchmarking ram instead of the disks.
- Also for benchmarking, write double what your cache is, so you aren’t again just testing ram.
- Also note that Linux has a variety of random number generators, each with limits to how much data per second they can generate.
- Various changes and commits that are difficult to discover if you read through the entire ZOL git repository for fun. ZFS apparently is able to make use of intel’s hardware SIMD called QuickAssistTechnology (QAT). ZFS even has an experimental untested feature that manually checksums ram, potentially allowing ecc capability on non-ecc ram, at the cost of performance.
- Real life examples of others making mistakes so you don’t have to!
3 Likes
Mostly, yeah. They’re the only location I can bear to read through the comments of.
This is all excellent info. It’s surprising how many people forget these things though.
Sad to see my 2 most frequently used filesystems at odds…
Dedupe isn’t always a disaster on ZFS…
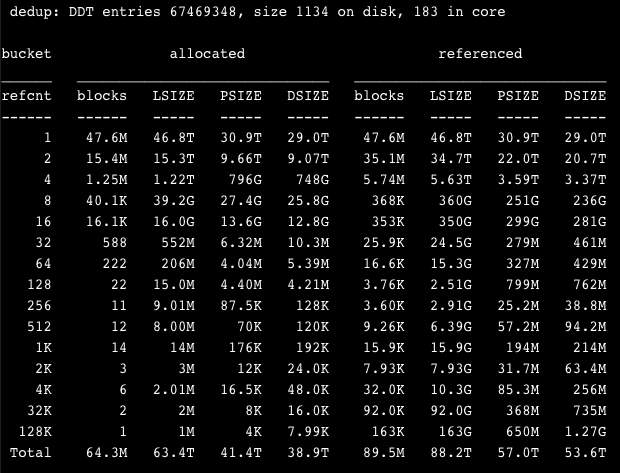
2 Likes
roommate thought it would be a good idea to deduplicate all of his steam games…
He doesn’t use dedup anymore
5 Likes
They’re not really at odds. I like both of them as well.
We’re just discussing the differences, pros and cons of them.
1 Like
Yeah, bad use case. I wouldn’t expect much duplication between games anyway.
1 Like
Is Dedoup mostly for things like office files or will it work alright for media/movies/ISO’s too?
The issue is that is the exception to the current rule that says “dedup fucking sucks”. There are severe performance issues, and also some data loss issues that I’m not too clear on but that I keep seeing brought up as being possible and have happened.
Enterprise users of dedup basically have their own in house customization/fixes (which of course they’ll never ever contribute) in order to get it working.
There are planned fixes, but it’s gonna take time.
If I was looking for deduplication, I’d look for some Linux utility that works on top of whatever filesystem is in use. I think I saw one mentioned somewhere, but can’t remember what it was offhand.
2 Likes
Yeah no kidding.
1 Like
Homelab and selfhost isn’t so bad… or am I that damage haha
1 Like
The seemed fine, but they weren’t really my jam. The guys there tend to be using tech for its own sake or as practice for work .
This may be heretical, but outside of rare infatuations, the older I get the more I find myself avoiding technology unless it concretely solves a problem I have or improved upon a previous solution. Which is why I haven’t even touched things I might have liked as a teenager with infinite free time, like creating my own ISP or home automation. How many google searches does it take to turn on a lightbulb
2 Likes
Not always, but in most cases it is.
1 Like
Snapshots/clones and compression are saner alternatives to dedup in a lot of cases. I have a hard time trying to think of a good excuse for dedup.
3 Likes
It is file-agnostic, so it doesn’t really matter. My understanding is that it hashes records to find duplicates, so any record-sized chunks of your files that are duplicate will be deduped.
In my above example, I hypothesized that setting a large record size would reduce dedupe’s memory usage. I didn’t have the opportunity to test smaller record sizes on the same dataset, but based on dedupe anecdotes, the large records did help. Unless my math is wrong, I spent 11GB of RAM for ~24TB of dedupe which I was happy with.
I don’t think dedupe would be good for media unless you for some reason have duplicate files. I do wonder if dedupe would pick up on things like different cuts of the same film or like the 20th Century Fox intro. I’m not sure if the compression/encoding would introduce any randomness into the raw data. Even if it did dedupe, I don’t think it would be a good use case though. Not enough benefit.
1 Like
My use case was an archive that almost no one will ever access where I knew there was substantial repetition in the data.
Another possible use case that I thought of (but have not fully tested) is hosting a mirror for multiple Linux distributions. I can imagine there’d be a lot of duplication between releases and distros. Might need to set a fairly low record size though, so might not be worth it.
1 Like
Regular compression works incredibly well for text, and lz4 is screaming fast.
I wouldn’t expect compressed archives or video to dedup unless you have exact copies.
ISOs I would expect to compress better than they dedup.
2 Likes