Correct, for ECC on TR you need to use Udimms. Capacity maxes out at 256GB on that platform though, so …
It’s probably worth noting that ECC memory runs slower. That means you have a higher performance ceiling on non-ecc memory.
Just an aside.
1 Like
Here’s the results
sha256-allcore-speed.txt (13.6 KB)
tldr: almost 2 gigabytes/sec per core (1.85-ish to 1.95-ish)
Zen2 clocks 10-15% higher and has better IPC in general…
I’m not sure if you’d get even more throughput using 16 threads to take advantage of SMT, but I’ll leave that as an exercise for somebody else 
Oh yeah…that’s right. I had forgotten about that detail.
Thank you.
Yeah, I’m currently using non-ECC, unbuffered RAM in my cluster headnode right now.
But yes, that will also add additional variables which makes it more and more difficult to do a 1:1 speed comparison between systems/processors/architectures/platforms.
Thanks.
Thank you for running that for me.
Yeah…so it would appear that AMD is DEFINITELY the way to go with this.
I am still holding out to see if there is someone who has access to a Treadripper 3970X and/or an AMD EPYC 16 cores or 32 core processor that they would be able to run this test for me as well.
If the Threadripper is able to supply 64 PCIe 4.0 lanes, maybe that can work for my headnode, although it’s running very close to what my PCIe demands are going to be.
Thank you.
Not sure if it’s been asked/said before.
But what sort of data do you want to hash?
Large files with variable size or strings with relatively well defined length?
If you want to process well defined strings of data, use a GPU.
If you want to deal with variable length file streams, use an Intel CPU with AVX512 and SHA extensions.
That thing will rip along at over 3.5GB/s per core.
Check out the block size!!!
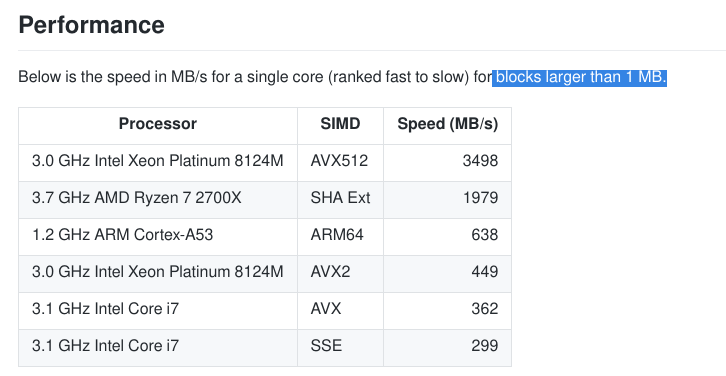
1 Like
Just the ease of keeping packages compiled with custom flags up to date, also since the question implies you’re really worried about the performance, so compiling everything with -march native could help you a bit.
It’s a 7-zip archive that was compressed using LZMA2 algorithm, with maximum compression settings.
The Intel Core i7 AVX results is actually really close to what I’m already currently able to get with my Core i7-3930K.
And yes, the Xeon Platinum 8124M (no price listed as it is an OEM processor, but the cheapest one out of that bunch is the Xeon Platinum 8153 at $3115) is certainly the fastest for that as listed there.
I’ll have to read the openssl/gcc documentation to find out what’s the flag to compile using AVX extensions.
Thank you.
Yeah, again, unfortunately, my CAE applications is not certified to run on gentoo, and that, also, further, unfortunately, rules it out.
Plus, I’m not sure if there’s that much support for Infiniband on gentoo, especially NFSoRDMA.
So you’re actually specifically worried that intelligent actors are trying to compromise you?
Because really, like others have said, if it’s just pure random chance you’re trying to work against, something non cryptographic would be way faster from the start.
Hope this helps.
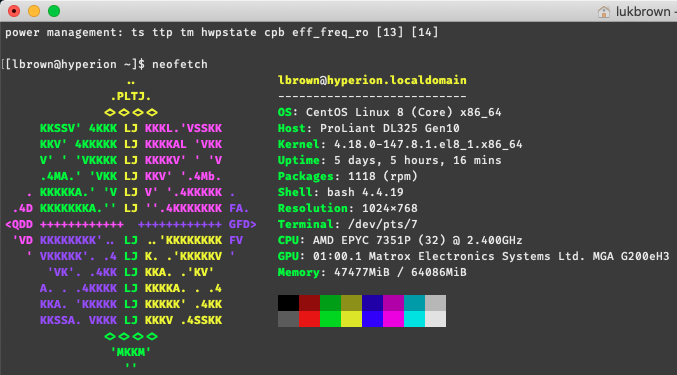
Note: it says 2.4 GHz but the all core boost turbo is actually 2.9 GHz as long as thermals are good (which mine are <= 60C max load all cores).
The RAM is 2666 MHz and is registered ECC.
[lbrown@hyperion ~]$ openssl speed sha256
Doing sha256 for 3s on 16 size blocks: 20770026 sha256's in 2.98s
Doing sha256 for 3s on 64 size blocks: 19702971 sha256's in 2.99s
Doing sha256 for 3s on 256 size blocks: 10092732 sha256's in 2.98s
Doing sha256 for 3s on 1024 size blocks: 3652866 sha256's in 2.98s
Doing sha256 for 3s on 8192 size blocks: 512340 sha256's in 2.99s
Doing sha256 for 3s on 16384 size blocks: 257914 sha256's in 2.98s
OpenSSL 1.1.1c FIPS 28 May 2019
built on: Thu Apr 9 19:02:31 2020 UTC
options:bn(64,64) md2(char) rc4(8x,int) des(int) aes(partial) idea(int) blowfish(ptr)
compiler: gcc -fPIC -pthread -m64 -Wa,--noexecstack -Wall -O3 -O2 -g -pipe -Wall -Werror=format-security -Wp,-D_FORTIFY_SOURCE=2 -Wp,-D_GLIBCXX_ASSERTIONS -fexceptions -fstack-protector-strong -grecord-gcc-switches -specs=/usr/lib/rpm/redhat/redhat-hardened-cc1 -specs=/usr/lib/rpm/redhat/redhat-annobin-cc1 -m64 -mtune=generic -fasynchronous-unwind-tables -fstack-clash-protection -fcf-protection -Wa,--noexecstack -Wa,--generate-missing-build-notes=yes -specs=/usr/lib/rpm/redhat/redhat-hardened-ld -DOPENSSL_USE_NODELETE -DL_ENDIAN -DOPENSSL_PIC -DOPENSSL_CPUID_OBJ -DOPENSSL_IA32_SSE2 -DOPENSSL_BN_ASM_MONT -DOPENSSL_BN_ASM_MONT5 -DOPENSSL_BN_ASM_GF2m -DSHA1_ASM -DSHA256_ASM -DSHA512_ASM -DKECCAK1600_ASM -DRC4_ASM -DMD5_ASM -DAES_ASM -DVPAES_ASM -DBSAES_ASM -DGHASH_ASM -DECP_NISTZ256_ASM -DX25519_ASM -DPOLY1305_ASM -DZLIB -DNDEBUG -DPURIFY -DDEVRANDOM="\"/dev/urandom\"" -DSYSTEM_CIPHERS_FILE="/etc/crypto-policies/back-ends/openssl.config"
The 'numbers' are in 1000s of bytes per second processed.
type 16 bytes 64 bytes 256 bytes 1024 bytes 8192 bytes 16384 bytes
sha256 111516.92k 421735.83k 867026.64k 1255213.01k 1403708.79k 1418007.71k
So it looks like my SHA256 8k is ~1.33 GiB/s on my Epyc 7351p. Still lower than @thro’s but hey for 1 Gen it’s not too shabby.
Running your script but its only pegging my CPU at ~35% above my baseline load.
results.txt (13.7 KB)
Still though if you were only getting 350MiB/s then first gen Epyc is roughly 4X faster than your i7.
By my math it looks like it would take my server ~1.5 hours to chew through that 6 TiB file.
Hope this helps.
1 Like
For fun, I just benched my Xeon E5-2650L and it only got ~163 MiB/s for the SHA256 8K.
My Epyc is about 8X faster at it lol. 5 years older than the Xeon by release data, 2012 vs 2017.
Wow.
I do. What am I testing? This is a long thread and I’m not about to go back and read everything lol.
3 Likes
Don’t ask about the disk.
Zen 1 1700X
32GB 2866Mhz tuned (CMK32GX4M4A2666C16)

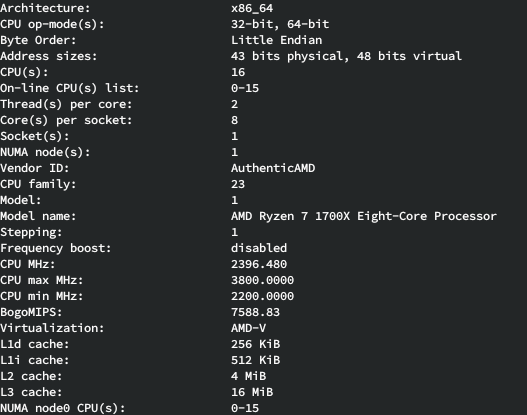
Zen 2 3600
No Screenfetch for the Zen 2 
But Linux 4.15 LTS
64GB 2666Mhz (M378A4G43MB1-CTD)

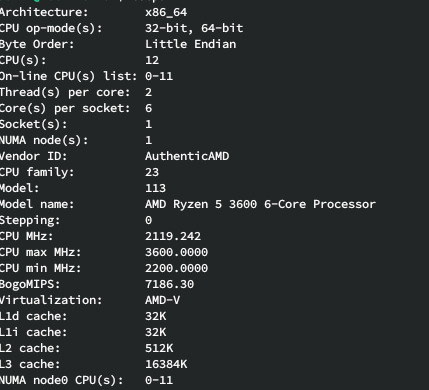
1 Like
That 3600 beats my 2700x per core at much lower clocks.
Guess I need to work on my tuning.
Run openssl speed sha256 on a rig with that installed and post the results please.
1 Like
I guess my X5690s aren’t quite cutting it. 
Doing sha256 for 3s on 16 size blocks: 9363472 sha256's in 3.00s
Doing sha256 for 3s on 64 size blocks: 5054155 sha256's in 3.00s
Doing sha256 for 3s on 256 size blocks: 2107626 sha256's in 3.00s
Doing sha256 for 3s on 1024 size blocks: 634413 sha256's in 3.00s
Doing sha256 for 3s on 8192 size blocks: 84811 sha256's in 3.00s
LibreSSL 2.6.5
built on: date not available
options:bn(64,64) rc4(16x,int) des(idx,cisc,16,int) aes(partial) blowfish(idx)
compiler: information not available
The 'numbers' are in 1000s of bytes per second processed.
type 16 bytes 64 bytes 256 bytes 1024 bytes 8192 bytes
sha256 49938.52k 107821.97k 179850.75k 216546.30k 231590.57k
1 Like
lol
this is clearly one of those edge cases where “there’s been no IPC improvement to speak of in the past 10 years” is very much not the case 
Like the AES-NI instructions. order of magnitude speed-ups for those edge cases where new instructions are put out to do stuff.
1 Like