Hi, this is my first post so sorry if it isn’t the best…
Initial description
So, I setup my linux host (Xubuntu 20.04) to do PCIe passthrough, and it properly passes through all the graphics cards from what I can see in lspci (output below)
lspci output
# lspci -d 10de:
07:00.0 VGA compatible controller: NVIDIA Corporation GM204 [GeForce GTX 980] (rev a1)
08:00.0 Audio device: NVIDIA Corporation GM204 High Definition Audio Controller (rev a1)
09:00.0 VGA compatible controller: NVIDIA Corporation GM204 [GeForce GTX 980] (rev a1)
0a:00.0 Audio device: NVIDIA Corporation GM204 High Definition Audio Controller (rev a1)
0b:00.0 VGA compatible controller: NVIDIA Corporation GM204 [GeForce GTX 980] (rev a1)
0c:00.0 Audio device: NVIDIA Corporation GM204 High Definition Audio Controller (rev a1)
0d:00.0 VGA compatible controller: NVIDIA Corporation GM204 [GeForce GTX 980] (rev a1)
0e:00.0 Audio device: NVIDIA Corporation GM204 High Definition Audio Controller (rev a1)
and all the GPUs appear to be properly running the nvidia kernel driver from lspci output
lspci output
# lspci -kd 10de:13c0
07:00.0 VGA compatible controller: NVIDIA Corporation GM204 [GeForce GTX 980] (rev a1)
Subsystem: PNY GM204 [GeForce GTX 980]
Kernel driver in use: nvidia
Kernel modules: nvidia
09:00.0 VGA compatible controller: NVIDIA Corporation GM204 [GeForce GTX 980] (rev a1)
Subsystem: PNY GM204 [GeForce GTX 980]
Kernel driver in use: nvidia
Kernel modules: nvidia
0b:00.0 VGA compatible controller: NVIDIA Corporation GM204 [GeForce GTX 980] (rev a1)
Subsystem: PNY GM204 [GeForce GTX 980]
Kernel driver in use: nvidia
Kernel modules: nvidia
0d:00.0 VGA compatible controller: NVIDIA Corporation GM204 [GeForce GTX 980] (rev a1)
Subsystem: PNY GM204 [GeForce GTX 980]
Kernel driver in use: nvidia
Kernel modules: nvidia
they are all the exact same card (as you can see), but when I do nvidia-smi to check and make sure the nvidia driver recognizes them all…it only sees 2…
nvidia-smi output
# nvidia-smi
Mon Jun 8 23:31:58 2020
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 440.82 Driver Version: 440.82 CUDA Version: 10.2 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 GeForce GTX 980 Off | 00000000:09:00.0 Off | N/A |
| 23% 38C P0 43W / 180W | 0MiB / 4043MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
| 1 GeForce GTX 980 Off | 00000000:0B:00.0 Off | N/A |
| 22% 37C P0 42W / 180W | 0MiB / 4043MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
Old problem became worse
This was a problem I was trying to debug and I thought it was a PCIe slot issue (because we identified that there was a specific slot that was continually not registering whatever GPU we would put in there), but that was when there was only one card that wasn’t getting recognized…now there are two…
the only thing I did was disable VFIO driver and test to make sure the nvidia card wasn’t showing up on the host OS when I would try and run nvidia-smi on the host (so install the nvidia driver on the host run the command and then revert all changes (I have an ansible playbook I use to provision the host)), and when I went back to the vm only 2 showed up in nvidia-smi, but all 4 were still showing up in lspci…
after I did the above step ( install nvidia on host then re-setup vm ) I did get this message when I ran nvidia-smi -L the first time, but after that it just wouldn’t show anything about the card…
nvidia-smi -L output
# nvidia-smi -L
Unable to determine the device handle for gpu 0000:07:00.0: Unknown Error # <-- this was new, and only happened once...
GPU 1: GeForce GTX 980 (UUID: GPU-31a5ce5c-3df1-8821-cc7d-8488c05f755c)
GPU 2: GeForce GTX 980 (UUID: GPU-d44ae2e8-271a-5dbb-e7bc-e75413b2a136)
Fruitless research… 
So, I did some more research into it and every card that isn’t showing up in the nvidia-smi is outputting this error message in journalctl
journalctl output
# journalctl -b0 | grep '0d:00.0'
***truncated for brevity***
Jun 08 22:43:06 <server_hostname> kernel: [drm] Initialized nvidia-drm 0.0.0 20160202 for 0000:0d:00.0 on minor 4
Jun 08 22:43:31 <server_hostname> kernel: NVRM: GPU 0000:0d:00.0: RmInitAdapter failed! (0x26:0xffff:1227)
Jun 08 22:43:31 <server_hostname> kernel: NVRM: GPU 0000:0d:00.0: rm_init_adapter failed, device minor number 3
Jun 08 22:43:40 <server_hostname> kernel: NVRM: GPU 0000:0d:00.0: RmInitAdapter failed! (0x26:0xffff:1227)
Jun 08 22:43:40 <server_hostname> kernel: NVRM: GPU 0000:0d:00.0: rm_init_adapter failed, device minor number 3
Jun 08 22:56:32 <server_hostname> kernel: NVRM: GPU 0000:0d:00.0: RmInitAdapter failed! (0x26:0xffff:1227)
Jun 08 22:56:32 <server_hostname> kernel: NVRM: GPU 0000:0d:00.0: rm_init_adapter failed, device minor number 3
Jun 08 22:56:41 <server_hostname> kernel: NVRM: GPU 0000:0d:00.0: RmInitAdapter failed! (0x26:0xffff:1227)
Jun 08 22:56:41 <server_hostname> kernel: NVRM: GPU 0000:0d:00.0: rm_init_adapter failed, device minor number 3
Jun 08 23:31:58 <server_hostname> kernel: NVRM: GPU 0000:0d:00.0: RmInitAdapter failed! (0x26:0xffff:1227)
Jun 08 23:31:58 <server_hostname> kernel: NVRM: GPU 0000:0d:00.0: rm_init_adapter failed, device minor number 3
I tried to google around, but couldn’t find anything on it besides that the driver might be wrong…which I don’t understand that if they are the exact same cards and only 2 of them are having issues…
I checked to make sure nothing was blacklisted (which it shouldn’t this was a fresh install):
nvidia-smi blacklist output
# nvidia-smi -L
GPU 0: GeForce GTX 980 (UUID: GPU-31a5ce5c-3df1-8821-cc7d-8488c05f755c)
GPU 1: GeForce GTX 980 (UUID: GPU-d44ae2e8-271a-5dbb-e7bc-e75413b2a136)
# nvidia-smi -B
No blacklisted devices found.
Last thing I noticed was this from the lspci -kkvvd output (link below) is that for some reason a bad GPU normally has the Current De-emphasis Level to -6dB and has EqualizationPhase2 & EqualizationPhase3 enabled with a Max snoop latency of 3145728. Below is a vimdiff of 2 known good (their names are at the bottom left of the corner) and 1 bad GPU.
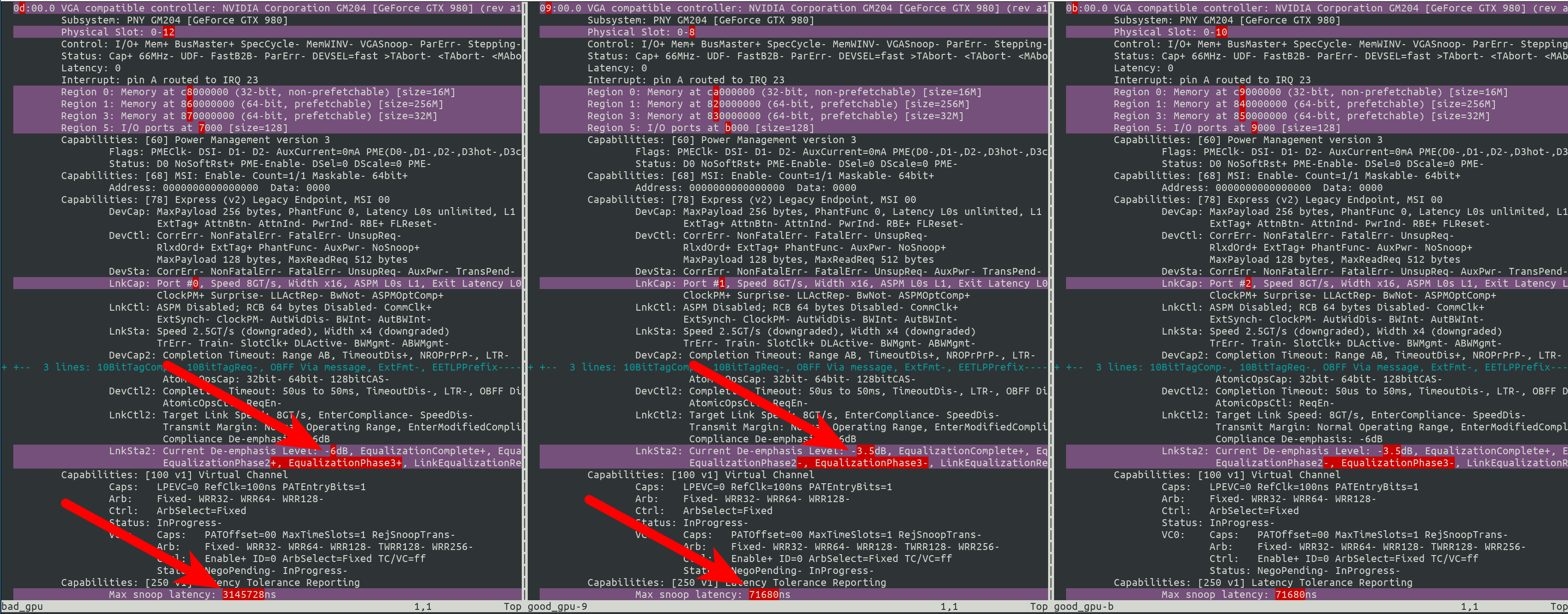
while posting ![]() I noticed that the second GPU that went bad has a
I noticed that the second GPU that went bad has a Max snoop latency of 0…so I might try and check with my co-worker tomorrow to make sure no cables came loose for that one, but the other bad one is still the same.
Wrap up
So, I am at a loss for words…I am going to update this post with some links for more debug logs (i.e. known good journalctl of initialized cards, lspci detailed output (-kkvvvd), and more nvidia-smi output), but wanted to post this first so I can link from those logs to this post.
Please let me know if there is anything else I can put in the post to help with debugging/more info… thank you in advance 
Links
lspci -kkvvvd log
journalctl logs
nvidia-smi query output
NOTE: I am remote from the machine and am working with a co-worker that is running through all my suggestions/tasks, so it might be a little bit before I come back with an answer for a suggestion, but I will do it as soon as possible and will also reply to let you know I saw your question/comment and we are in process of trying it.
Backstory on machine
(put this down here , so those who aren’t curious didn’t have to worry about it and could ignore it)
backstory
We initially had Ubuntu 14.04 running on this machine with the nvidia driver being used on the base host, and knew we needed to do an upgrade so I convinced my boss that we should do PCIe passthrough (because I had done it at home with my windows gaming vm). The reason why I recommended that is because we had connectivity issues and lots of instability issues with how the drivers and stuff were configured before. So, I figured we should install the latest LTS and everything should just work.
First off we had an issue with enabling the iGPU for the intel cpu we had, so we did some bios upgrades (because we were 11 versions behind on the bios), so we got updated completely to the most recent version of the BIOS and then the iGPU worked. So, now I could do the PCIe passthrough configuration. So, I got that all setup and didn’t have any issues (or so I thought…), and that is when this issue happened…
UPDATE: I found out that the last thing I was talking about right before the wrap up (about the new card not registering a Max snoop latency and not showing in the nvidia-smi output for the vm) , that when I undo the PCIe passthrough and load the nvidia drivers for the host. That the host machine actually sees that 3rd card, but I still don’t see that last GPU even on the host.