Hello,
I’ve been asked to design and setup a VM Lab for my team at work. We provide / maintain medical IT solutions in the UK .
This includes: Diagnostic image rendering, DICOM (CT scans etc) study storage, and database systems, such as reception / job tracking systems.
Much of this involves a number of our products being deployed together in a hospital and they all ‘tie’ in the each other in one way or another.
The breif for this project is to be able to provide three people with enough VM provision to create and store test systems for each type of product we work with - and be able to run a number of these concurrently. This will be used for practise / training on these systems in addition to testing new ideas etc.
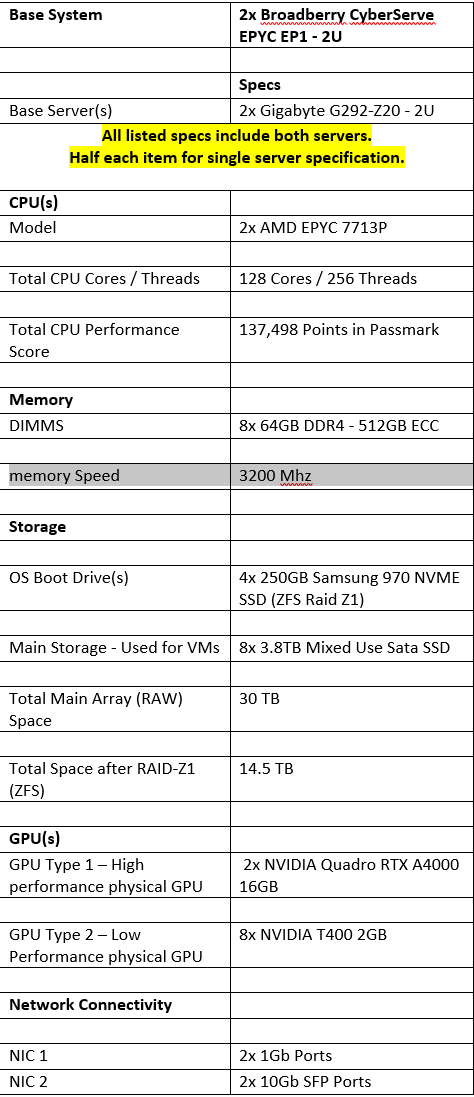
I have worked this out to require:
• Ability to Store and run +/- 50 VMs. At least ⅔ (33) of which are expected to run at any one time.
• Minimum of 10TB, single disk failure tolerant storage for VMs (will be backed up elsewhere)
• This storage solution needs to be quick enough to serve +/- 40 VMs, without undue I/O latency. ( I plan to use proxmox with a ZFS file system).
• High thread count CPU(s). A powerful CPU, with as many threads as is reasonably possible. I beleive this workload is expected to scale / perform better with additional thread count, vs raw computational speed?
• A Minimum of 400GB Memory (RAM).
After coming up with a few ideas, I have put together the following proposal for work. using two servers - attempting to allow for futire extra overhead where possible.
I would really apreciate any input on this - if I’ve got it all wrong, tell me, please!
Approxamate cost of this (ex VAT) will be £32000. - have I got this spent well? - this just goes over the budget I was given.
if there are better ways to get this project done - I’m really keen to find out!
The reasoning for the low power GPUs is, for some test systems, I’m thinking it will be helpful to be able to passthrough a real GPU in some scenorios. The realworld Rendering systems mostly use 3x Quadro RTX 4000’s - however, this is split across a number of users - which we wont be needing in the test lab.
I added 1 RTX 4000 16GB card as a way of playing it safe - should we ever need to run a render VM with the correct ‘Required’ GPU for the applicaiton. This, and I wanted to try and split it up using vGPUs or SR-IOV… (not sure if this’ll work?)
As previous - I plan on using proxmox for this, joining both servers together into a proxmox ‘datacentre’.
The points thing I’m most worried about are:
-
List item
if the CPU in each server will be sufficent to run up to 25 VMs - some of which take a fair bit of ‘umph’. I estimated 260 vCPUs were likely to be allocated between all the VMs for three of us with our own enviroment. The two AMD EPYC 7713P CPUs would give a total of 256 threads. I belive this would overallocate without much issue - sharing threads betwen VMs? -
List item
If the planned SSD storage 4x Micron 5300 PRO 3840GB SSDs in ZFS RAID-Z1 - in two lots of two per server will be able to keep up with a respectable i/O delay in proxmox? (storage isn’t really my thing, so advice especially appreacted here!)
Sorry for the long post - thanks in advance for your advice!