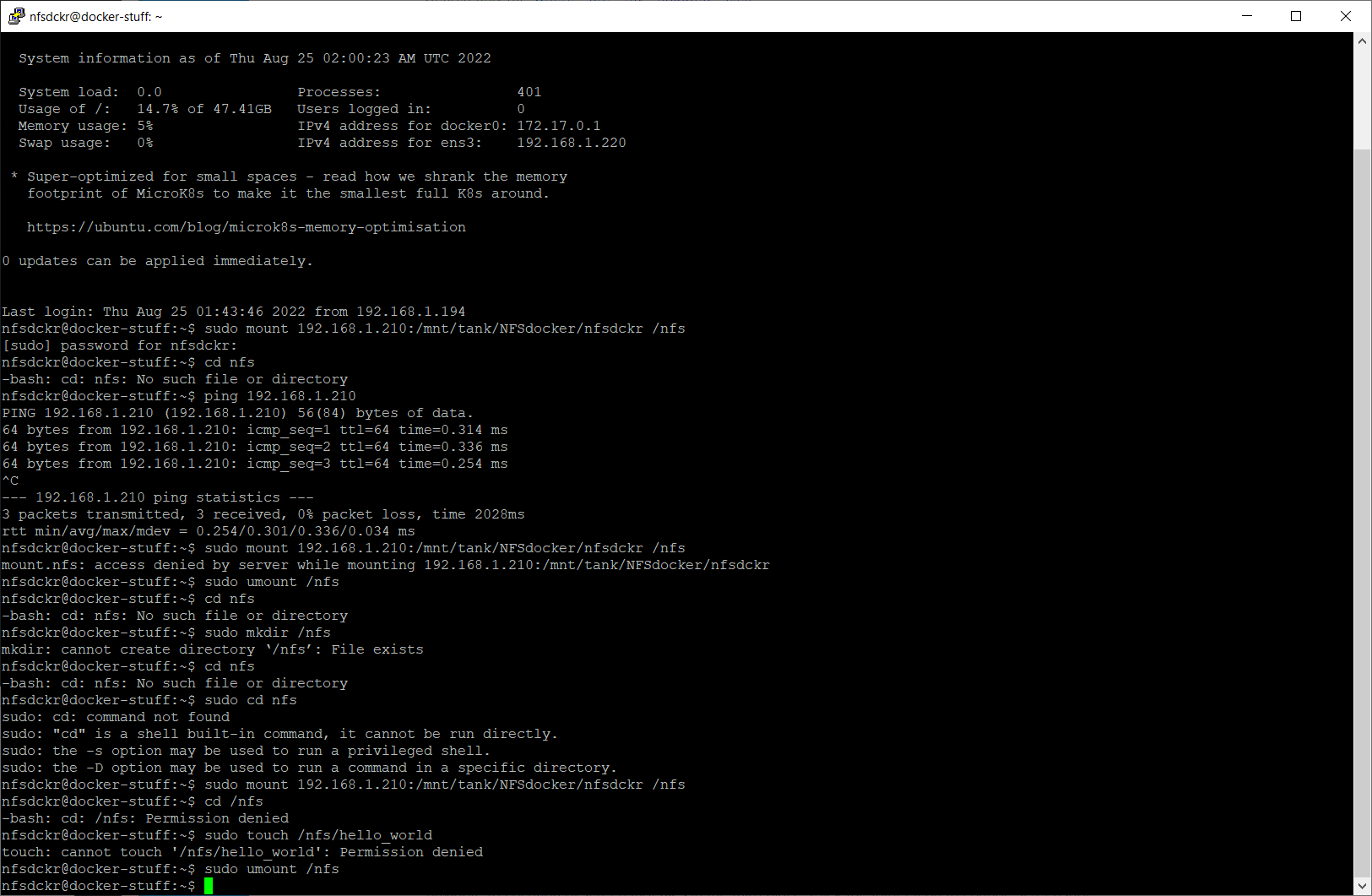
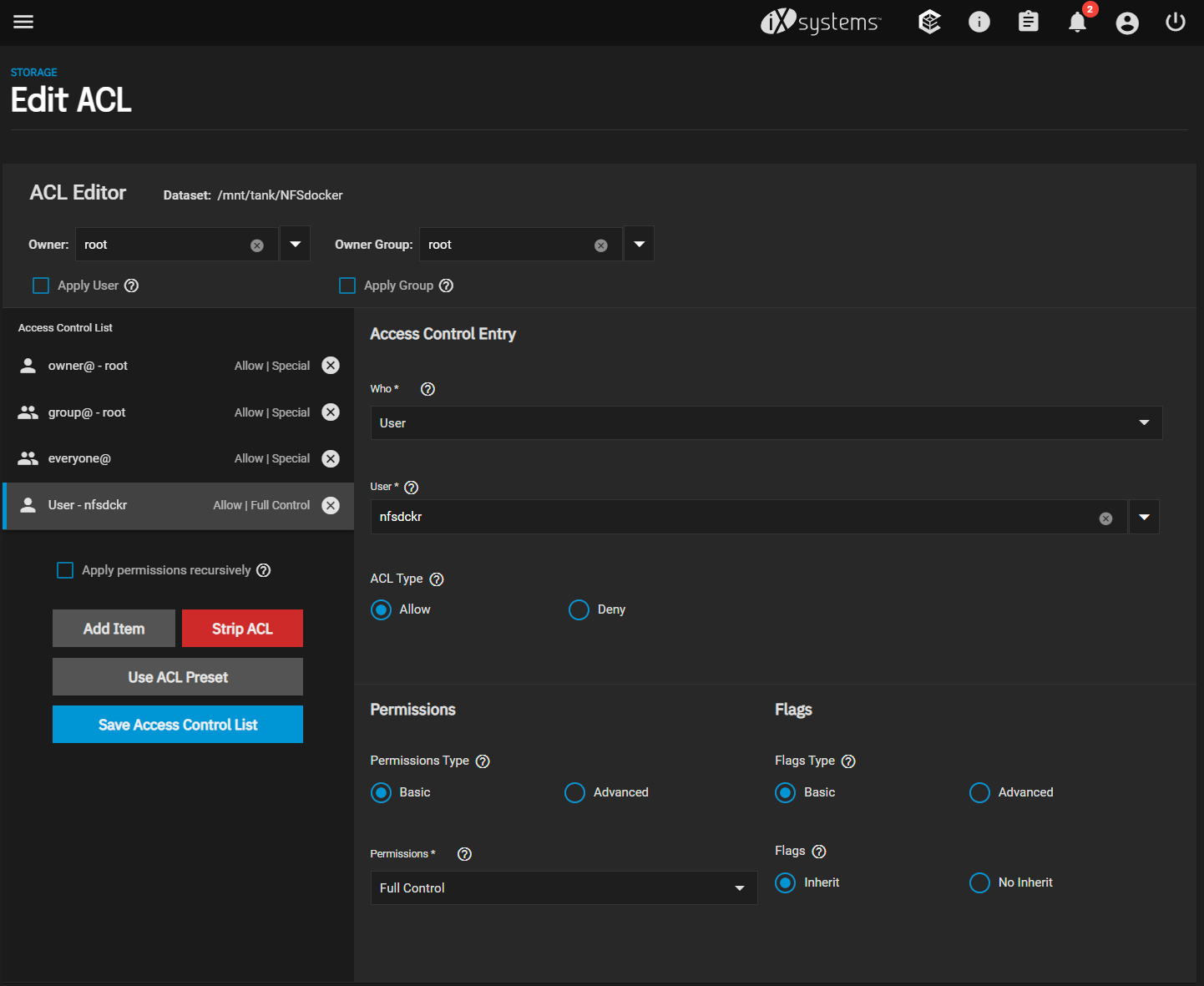
Can anyone elaborate on Wendell’s choice to use NFSv4 ACL type when configuring the NFS dataset? The scale docs seem to suggest that it’s only required if you want interoperability with ZFS systems created or used outside of the linux world. That sorta makes sense to me as a default but I don’t want to make permissions more complicated than they need to be, and my homelab and requirements are entirely linux-based, so I’m considering using POSIX instead.
If NFSv4 ACL type is actually a hard requirement for Docker storage, then my next question would be if it’s specifically a Docker-only requirement, and if child datasets of the docker NFS dataset should also be set to NFSv4, or if I can use POSIX for those. Typically I would have a child dataset for the persistent storage of each docker container.
EDIT: Also, as an aside, I had trouble getting the NFS mounts on the docker VM to mount reliably on boot. There was a systemctl command mentioned somewhere else in this thread which seemed to help but ended up not totally solving my problem. I added the bg option to each NFS share entry in /etc/fstab which completely solved my problem. The description of this option:
Specify bg for mounting directories that are not necessary for the client to boot or operate correctly. Background mounts that fail are re-tried in the background, allowing the mount process to consider the mount complete and go on to the next one. If you have two machines configured to mount directories from each other, configure the mounts on one of the machines as background mounts. That way, if both systems try to boot at once, they will not become deadlocked, each waiting to mount directories from the other. The bg option cannot be used with automounted directories.
EDIT AGAIN: Alright, well, I spoke too soon, it’s still not working reliably. Relevant syslog section:
Sep 8 18:19:01 docker systemd-timesyncd[421]: Network configuration changed, trying to establish connection.
Sep 8 18:19:01 docker systemd[1]: Finished Wait for Network to be Configured.
Sep 8 18:19:01 docker systemd[1]: Reached target Network is Online.
Sep 8 18:19:01 docker systemd[1]: Mounting /nfs...
Sep 8 18:19:01 docker systemd[1]: Starting Docker Application Container Engine...
Sep 8 18:19:01 docker dhclient[467]: DHCPDISCOVER on ens3 to 255.255.255.255 port 67 interval 4
Sep 8 18:19:01 docker sh[467]: DHCPDISCOVER on ens3 to 255.255.255.255 port 67 interval 4
Sep 8 18:19:01 docker kernel: [ 14.875753] FS-Cache: Loaded
Sep 8 18:19:01 docker kernel: [ 14.961827] FS-Cache: Netfs 'nfs' registered for caching
Sep 8 18:19:01 docker kernel: [ 14.975692] Key type dns_resolver registered
Sep 8 18:19:02 docker kernel: [ 15.147869] NFS: Registering the id_resolver key type
Sep 8 18:19:02 docker kernel: [ 15.147875] Key type id_resolver registered
Sep 8 18:19:02 docker kernel: [ 15.147876] Key type id_legacy registered
Sep 8 18:19:02 docker mount[504]: mount.nfs: Network is unreachable
Sep 8 18:19:02 docker systemd[1]: nfs.mount: Mount process exited, code=exited, status=32/n/a
Sep 8 18:19:02 docker systemd[1]: nfs.mount: Failed with result 'exit-code'.
Sep 8 18:19:02 docker systemd[1]: Failed to mount /nfs.
It seems to think it’s connected already, then proceeds with the NFS mount, and it still fails with “network unreachable”. I don’t have any issues mounting from a shell after boot is complete, so… I’m not sure what the deal is, other than somehow it not waiting long enough.
ANOTHER EDIT: Alright I’ve had either a good string of lucky restarts with functioning mounts, or disabling IPv6 on the entire debian VM (for another unrelated reason) has fixed the problem.