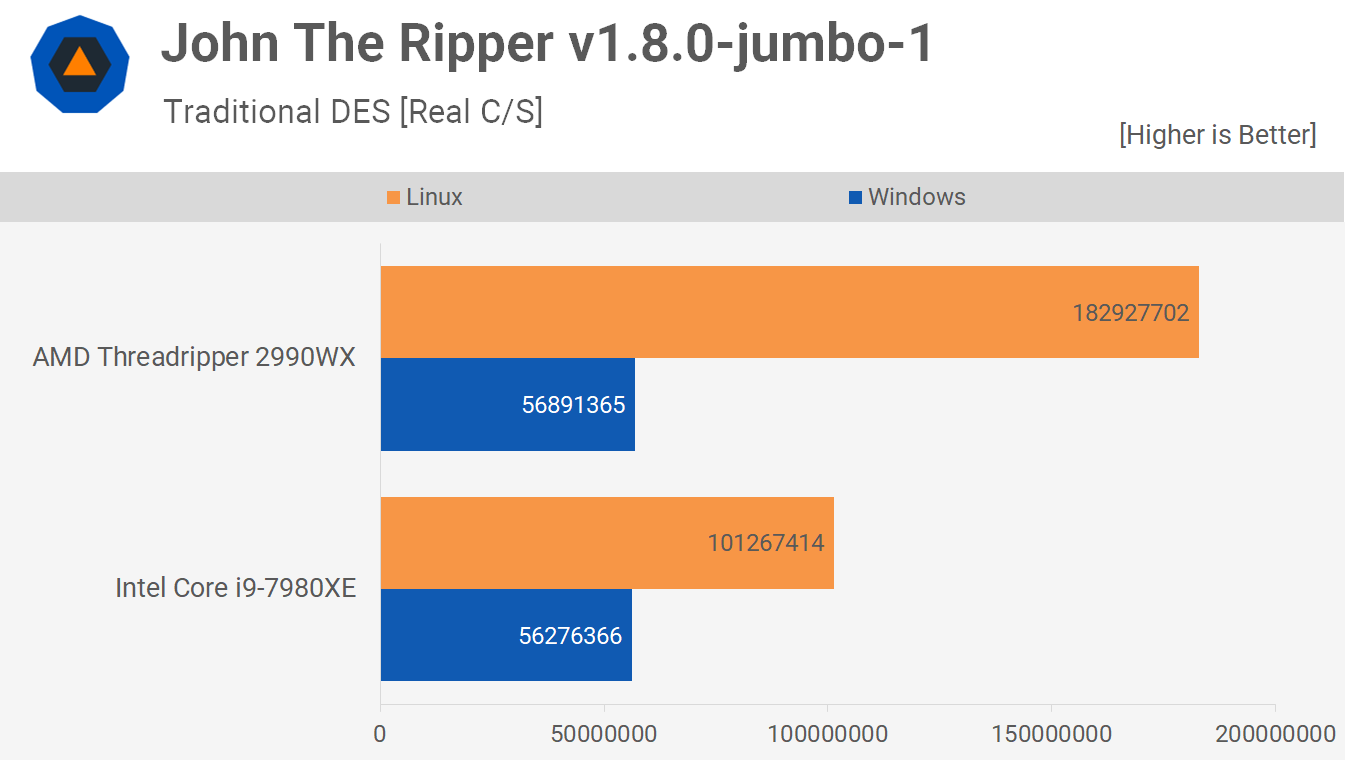
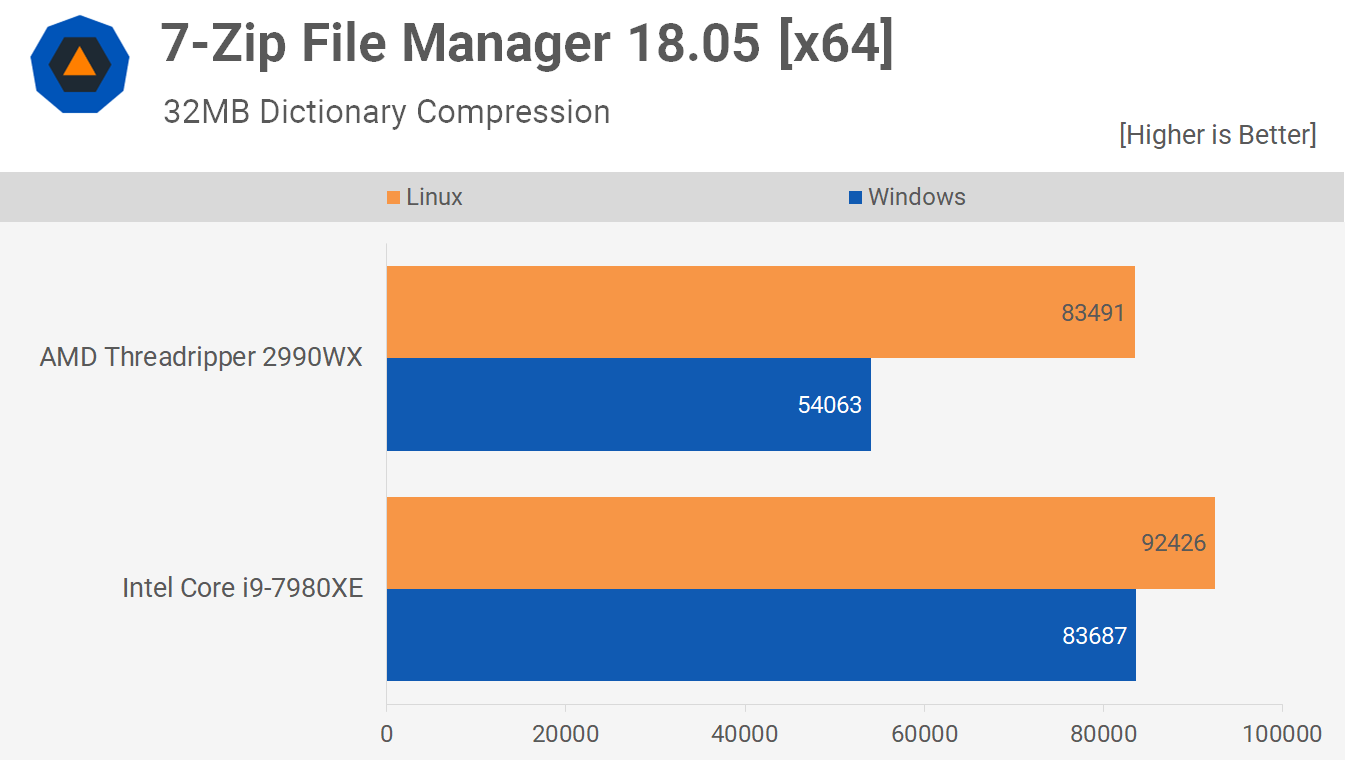
Bonnie++
4100:
Version 1.97 ------Sequential Output------ --Sequential Input- --Random-
Concurrency 1 -Per Chr- --Block-- -Rewrite- -Per Chr- --Block-- --Seeks--
Machine Size K/sec %CP K/sec %CP K/sec %CP K/sec %CP K/sec %CP /sec %CP
xxxxxxxxxxxxxx 126G 1198 99 1782750 94 936796 54 3533 99 2579093 83 2384 106
Latency 7216us 39860us 511ms 2360us 3259us 5657us
Version 1.97 ------Sequential Create------ --------Random Create--------
xxxxxxxxxxxxxxxxxxx -Create-- --Read--- -Delete-- -Create-- --Read--- -Delete--
files /sec %CP /sec %CP /sec %CP /sec %CP /sec %CP /sec %CP
16 20720 39 +++++ +++ +++++ +++ 22853 43 +++++ +++ +++++ +++
Latency 139us 252us 322us 89us 6us 317us
1.97,1.97,xxxxxxxxxxxxxxxxxxxxxx,1,1535687781,126G,,1198,99,1782750,94,936796,54,3533,99,2579093,83,2384,106,16,,,,,20720,39,+++++,+++,+++++,+++,22853,43,+++++,+++,+++++,+++,7216us,39860us,511ms,2360us,3259us,5657us,139us,252us,322us,89us,6us,317us
PBO + cpupower performance governor:
Version 1.97 ------Sequential Output------ --Sequential Input- --Random-
Concurrency 1 -Per Chr- --Block-- -Rewrite- -Per Chr- --Block-- --Seeks--
Machine Size K/sec %CP K/sec %CP K/sec %CP K/sec %CP K/sec %CP /sec %CP
xxxxxxxxxxxxxx 126G 1245 99 1806634 91 923144 54 3577 99 2568785 81 2423 107
Latency 7097us 36473us 496ms 2844us 7283us 515us
Version 1.97 ------Sequential Create------ --------Random Create--------
xxxxxxxxxxxxxxxxxxx -Create-- --Read--- -Delete-- -Create-- --Read--- -Delete--
files /sec %CP /sec %CP /sec %CP /sec %CP /sec %CP /sec %CP
16 22707 42 +++++ +++ +++++ +++ 23312 43 +++++ +++ +++++ +++
Latency 202us 505us 292us 257us 10us 1611us
1.97,1.97,xxxxxxxxxxxxxxxxxxxxxx,1,1535681934,126G,,1245,99,1806634,91,923144,54,3577,99,2568785,81,2423,107,16,,,,,22707,42,+++++,+++,+++++,+++,23312,43,+++++,+++,+++++,+++,7097us,36473us,496ms,2844us,7283us,515us,202us,505us,292us,257us,10us,1611us
 )
)