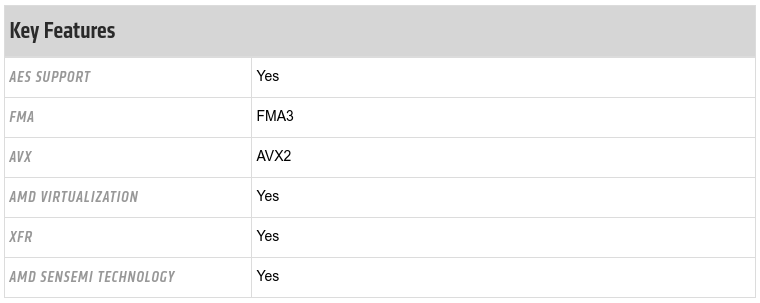
I’ve had a chance to compare the results of couple different BLAS libraries when tested in the Phoronix HPC Challenge test. I had planned to test more but found a couple rabbit holes along the way that needed exploring.
I compared the Intel MKL with a Zen optimized ATLAS, the results are interesting.
https://openbenchmarking.org/result/1809087-RA-2990WXBLA90
What about the Zen optimized ATLAS?
ATLAS stands for “Automatically Tuned Linear Algebra Software” and it lives up to it’s name. At compile time, it finds and exercises all the available instruction set extensions, performing hours worth of precision tests to inch out every little bit of performance.
Interestingly, the ATLAS tuning routines found the presence of the FMA4, which passed sanity check and was included as one of the codepath choices for later tests. In some of performance tests, the FMA4 codepath won by a huge percentage and was selected.
If you want to build ATLAS for yourself, I’d suggest setting the Threadripper to single die / sixteen threads to remove timing variance introduced by NUMA when jumping from die to die. You’ll also need to disable everything related to AMD’s “catch me if you can” clock scaling mechanism, you need a fixed CPU clockspeed for the ATLAS tests to make sense.
I came across FMA4 again, this time in some OpenBLAS github chatter. The ZEN target in OpenBLAS has never worked, it currently cheats a bit by aliasing ZEN to HASWELL and setting NO_AVX2=1. Much of this particular rabbit hole is covered here:
One of the more interesting comments (down the bottom) on that github page is:
For future reference: it turns out that Ryzen does support FMA4, it just does not document this through CPUID flags. That’s why the Excavator kernels didn’t crash with SIGILL.
Wikipedia sheds some more light on ZEN and FMA4, though the refferenced AMD pages are “down for maintenance” which was not the case earlier today, perhaps they’re adding the newest Threadripper series, previously missing.
When the AMD pages were up I saw that FMA4 is the first item listed under “Features” for the 2400G and some other ZEN based chips. It was not however listed on the Threadripper 1950X ( latest listed model at the time) page.
So what’s the go? Political decision? Business decision? Either way, I don’t think I care for it, my fix, patch the kernel. I quickly came up with this:
--- a/arch/x86/kernel/cpu/amd.c 2018-08-28 18:07:45.148373843 +1000
+++ b/arch/x86/kernel/cpu/amd.c 2018-09-08 20:40:52.820838835 +1000
@@ -821,9 +821,13 @@
/*
* Fix erratum 1076: CPB feature bit not being set in CPUID. It affects
* all up to and including B1.
+ *
+ * FMA4, while present and working on Zen up to and including B1, is not
+ * exposed by the CPUID instruction, let's fix that here.
*/
if (c->x86_model <= 1 && c->x86_stepping <= 1)
set_cpu_cap(c, X86_FEATURE_CPB);
+ set_cpu_cap(c, X86_FEATURE_FMA4);
}
static void init_amd(struct cpuinfo_x86 *c)Patch is attached below (you don’t need it for ATLAS, which just ignores CPUID alltogether).
With that fixed:
cat /proc/cpuinfo
processor : 0
vendor_id : AuthenticAMD
cpu family : 23
model : 8
model name : AMD Ryzen Threadripper 2990WX 32-Core Processor
stepping : 2
microcode : 0x800820b
cpu MHz : 1878.563
cache size : 512 KB
physical id : 0
siblings : 64
core id : 0
cpu cores : 32
apicid : 0
initial apicid : 0
fpu : yes
fpu_exception : yes
cpuid level : 13
wp : yes
flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ht syscall nx mmxext fxsr_opt pdpe1gb rdtscp lm constant_tsc rep_good nopl nonstop_tsc cpuid extd_apicid amd_dcm aperfmperf pni pclmulqdq monitor ssse3 fma cx16 sse4_1 sse4_2 movbe popcnt aes xsave avx f16c rdrand lahf_lm cmp_legacy svm extapic cr8_legacy abm sse4a misalignsse 3dnowprefetch osvw skinit wdt fma4 tce topoext perfctr_core perfctr_nb bpext perfctr_llc mwaitx cpb hw_pstate sme ssbd sev ibpb vmmcall fsgsbase bmi1 avx2 smep bmi2 rdseed adx smap clflushopt sha_ni xsaveopt xsavec xgetbv1 xsaves clzero irperf xsaveerptr arat npt lbrv svm_lock nrip_save tsc_scale vmcb_clean flushbyasid decodeassists pausefilter pfthreshold avic v_vmsave_vmload vgif overflow_recov succor smca
bugs : sysret_ss_attrs null_seg spectre_v1 spectre_v2 spec_store_bypass
bogomips : 5999.20
TLB size : 2560 4K pages
clflush size : 64
cache_alignment : 64
address sizes : 43 bits physical, 48 bits virtual
power management: ts ttp tm hwpstate cpb eff_freq_ro [13] [14]
Now, back to the BLAS comparison.
Something interesting is shown in the results, the optimized BLAS really grows wings when the CPU is let loose, while the other seems held back somewhat, not scaling as well. The optimized BLAS actually runs colder, Zen notices this and bumps up the CPU frequency to use up some of the headroom, and actually still manages to run cooler.
On Zen, the thermal output of any CPU instruction really is related to the top boost frequency the CPU will do at the time. Thermally optimized code is an interesting prospect. I wonder if gcc will ever get a -Ot switch 
enable_fma4_on_zen.patch (587 Bytes)