This is not 100 % related to knowledge ‘storage’, but perhaps knowledge aquisition…
I have found the most useful purpose of my home server to be an always-on instance of RStudio Server and Jupyter labs. I used it throughout a PhD and now work for myself, doing contract analysis for companies and Universities that want their data to be analysed. The convenience of having a local server that can run whatever analyses I want, with a plentiful ZFS archive behind it, is fantastic.
The crazy thing is, every single bit of analysis-related knowledge I gained during my PhD came from the internet. There is so much information and so many open datasets now that you can learn and do this type of work independently. A friend of mine hasn’t got a PhD and is now doing the same type of contract-based work that I am.
Just thought I would post this in case anyone considers that interesting or useful. If I can offer any other advice, let me know.
I’m really happy to see I’m not the only one who was wanting something like this. I started to mockup what I wanted to make in just basic HTML months ago but just brushed it to the side. I’m a SysAdmin/Network Engineer, not a developer so I’d have no clue what I was doing with proper database stuff. I was trying to base my idea off “Appledor” like the Charles Magnuson from Sherlock.
Came back to mention I’m looking into obsidian and noticed Wendell had an update that talks about it. Haven’t delved into obsidian much yet but it does at least look like a very good base for knowledge management.
The biggest key to success is to keep it simple and low friction. When it’s second nature and your habits are established you can layer on a bit more complexity.
It’s easy to get sucked into a geewihiz thing but actually make it harder to use.
You can start with just a hand full of tags and liberal use of office lens to capture everything and just build on the complexity one you have a good habit. Only them would i recommend looking at what others are doing.
Just 4-5 top level directories and a few tags is all you need to start
I did a quick search in the thread, but I didn’t see anyone mention Dendron. A chat with the Dendron folks can be found on YouTube. It will not fit all requirements, but it’s food for thought and seems to fit the general theme of the conversation.
In the past I was using evernote, then plain org mode, then moved to vimwiki (markdown). I tried some other markdown based solutions like obsidian but nothing was quite able to tick all the boxes I missed from org mode. Eventually I stumbled upon an emacs package called org-roam. I found this package to be extremely powerful for structuring information in a way which is easy to retrieve and retains all of the organisational benefits of org mode. Now I use this to capture all of my information which is synced between all my machines/devices using nextcloud. To access it on my phone I use emacs inside of termux, so the editing experience is practically identical everywhere I need the info. After setting up a few capture templates I can capture and filter new information of many different types in just a couple keystrokes.
One other nice package is org-roam-ui. This provides a nice graphical front end for exploring all the files similar to obsidian.
EDIT: For anyone who is new to emacs but familiar with vim and would like to give it a try, I would recommend taking a look at Doom Emacs. It sets up sensible defaults for vim bindings and some other useful packages without bloating emacs with a thousand packages you will never use. In doom emacs setting up org-roam is as simple as uncommenting the line for that package in init.el and running doom sync
I’ve been working with multi source graph ingestion and traversal. Some interesting problems come up when you try to deal with broken provenance and weird aggregations. My perfect system IS just a filesystem, but with metadata as documents as well.
What I imagine is a system that adds contextual ‘documents’ next to (linked in filename preferably) anything saved. Then a background process extracts and tokenizes files (it’d be great to add metadata scanners and object recognition to images).
I’d then like two interfaces to the files (outside of direct file access). One is an elastic or some fuzzy search with all the texts from metadata and files indexed. The second is a virtual graph overlaid on top of the filenames (requires very smart file naming/renaming).
I think the most important thing about directory structures is reliable, forward compatible, patterning. A folder a day with everything worked on and the metadata/extractions.
Then a UI that lives with me on all my devices with subgraph tracing (follow threads - date filters, related items, etc) or quick full text searches. Frankly, windows search is getting really good at the full text bit, but you’d want to screen metadata and extraction stuff from the response, which file explorer won’t do (looking at the raw files might be nasty).
I’m less interested in a directory structure I can search than a pattern of storage and metadata formatted such that I can build graphs in neo4j or arango or something.
I always go back to OneNote so that is what I currently use. Works across all of my devices, I know others do as well. Definitely open to changing things.
This is no OneNote (though the icon designs for Notebooks and Section Groups are based on it) but i have worked on a note organizing application (still a WIP) that can launch other applications and organize files from them. I got it working with Xournal++ and Kate as far as applications go.
My ideal knowledge repository would in theory be able to link to my media files : like my videos served by Jellyfin or my ebooks managed by Calibre (I also discovered that Calibre has a server mode and Obsidian has a Calibre plugin). My school stuff can stay in its own directory for now; most of my school notes are made on paper with digital files used for programming, forms, documents, Latex docs and presentation slides. I am also in the process of scanning all my physical books into a book cataloging app on my phone called MyLibrary which can scan book barcodes and fetch metadata automatically.
Once that’s done I would like to back up the catalog but somehow also be able to use it to find where my books are on their shelves physically. Perhaps some AR / SLAM location method or even just a rough 2D map. Actually, after thinking a bit, a way to detect which book is in which position in real time would be a cool project to work on, a la Amazon Go stores.
As Obsidian supports Markdown and my personal blog (work in progress) is based in Hugo (https://gohugo.io/) I would also ideally have a way to convert notes or use notes to serve blog posts to my hugo repository. Though right now I want to keep my hugo workflow separate, by writing posts for my blog entirely separate from my Obsidian notes vault.
I’ve been struggling a bit with understanding the Zettalkasten method (and it IS a methodology not a specific implementation). I figure it will take a bit to tailor a workflow that works for me. I’m excited to find out a bit more about how my brain works by seeing my notes laid out in graph view.
Before considering zettalkasten, I was thinking of trying to dump all the knowledge I could think of into a self-managed private wiki. The drawback with DocuWiki is that I would have to manage a database as well, which is something I don’t want. I want to just have to deal with text files, images, and hyperlinks. I might check out BookStack (https://www.bookstackapp.com/) for fun, but
Obsidian’s help/documentation is built within their own software using markdown. As such, it doubles as a great demo/exploration to see what can be done both with the Obsidian software and by extension, markdown files.
So if you install Obsidian, and hit F1 within the program, a new “Vault” launches with all the help info and is a fully functional demo of their tech.
Though of note, as I have been exploring markdown files and editors, there is not a single unified way that all programs treat markdown. The text will be there always, but some of the extra features like linking or embedding may vary.
As I have been exploring Markdown files and a personal knowledge base I have been using Visual Studio Code with markdown extensions and/or Obsidian. If you like the idea of bouncing between both, make sure to dig into the Obsidian settings of how the program format things such as links (defaults to wiki style links, which VS Code doesn’t support to my knowledge).
I tried setting something like this up in Notion a while back using their built in databases… Mostly fell apart because I do a lot of note taking on my phone, and their app is awful.
Ingestion was just a tedious process.
How do you guys handle that sort of thing? I just end up dumping everything into Google Keep on my phone and forgetting it’s there. I’ve tried physical notebooks and it just doesn’t work for me.
I had been using obsidian for about the past year. I did really like everything except the closed source nature of it. I recently started using logseq which is free and open source. I then use Syncthing to sync my notes folder across devices (via my home nas). Logseq seems to be on parity with most of obsidian’s main features. One feature I really like though is that is has this idea of a journal which is single doc which automatically adds a new section at the top for each day. That way I can easily scroll down to a particular day. The todo list feature is also really nice for task tracking.
I’ve been building an open source documentation platform (BookStack) for the last 6 years. I’d be happy to provide any insight from that perspective if it could help. Am new to the forums but have been following L1 on YouTube for few years now and just watched the “Second Brain” video so thought I’d offer input where possible.
I’ve come to learn that a person’s use-case, requirements & expectations in this area can vary wildly. With managing BookStack I often find myself in a position of needing to defend the original use-case (Mixed-skill team environments) since many people requesting features are very technical (Swayed by the fact issues are logged via GitHub and the project has primarily spread via Reddit). It’d be very easy for the platform to be stretch to an amorphous blob which barely suits any use-case.
Another area I find myself defending is the content format for documentation. BookStack stores content in HTML (Primarily) or markdown (Commonmark). It’s super important to me that the format of people’s content remains somewhat portable in case they ever want to leave the platform. Therefore I try to keep to commonmark or relatively simplistic HTML, but this poses a challenge when users request more advanced content formatting or features. I often wonder if some of the similar commercial offerings care about this at all since they may see it in the business’s interest to keep users locked in.
Personally, I use BookStack (Yeah, bit biased) for longer-term docs, Google Keep for very short-term phone based notes, and hugo (Static site generator) for BookStack’s site/docs/blog and my own blog. It annoyed me and felt hypocritical not using BookStack for the BookStack documentation but the reality was that a static site generator was much better suited to that use-case and the process I wanted to achieve.
Haven’t read through the whole thread so maybe this has been mentioned already but Notion is big for knowledge sharing/retention etc.
I’ve not used this but https://www.appflowy.io/ claims to be an open source alternative.
I use Tellico, the KDE collections program, to track my books, video games, and board games and it has worked out well enough for me to share my book list with friends etc.
Similar issue. I like using the diary feature of vimwiki. Rebasing isn’t too big a headache, plus I self-host my git server at home on a raspberry pi 4. I don’t want my private diary leaving my LAN. I just need to setup VPN for remote access.
I made a small set of bash scripts to help write and manage notes. It has an installer and provides commands for journaling, writing down ideas, projects, notes and more. Its 100% text based and uses git to sync & save notes.
I’ve been using it for 4 years and my note repo holds over 1600 commits
I’m at a point where bash limits what I can do with. I would like to read notes on the go and do light editing on mobile.
Also the text only nature of it makes it hard for non tech savvy individual to use it, so I’m making a web based version that I hope I can bring tho the desktop to access the file system.
I’m currently recovering from a burnout so work has been minimal damonpl/text2web - Gogs
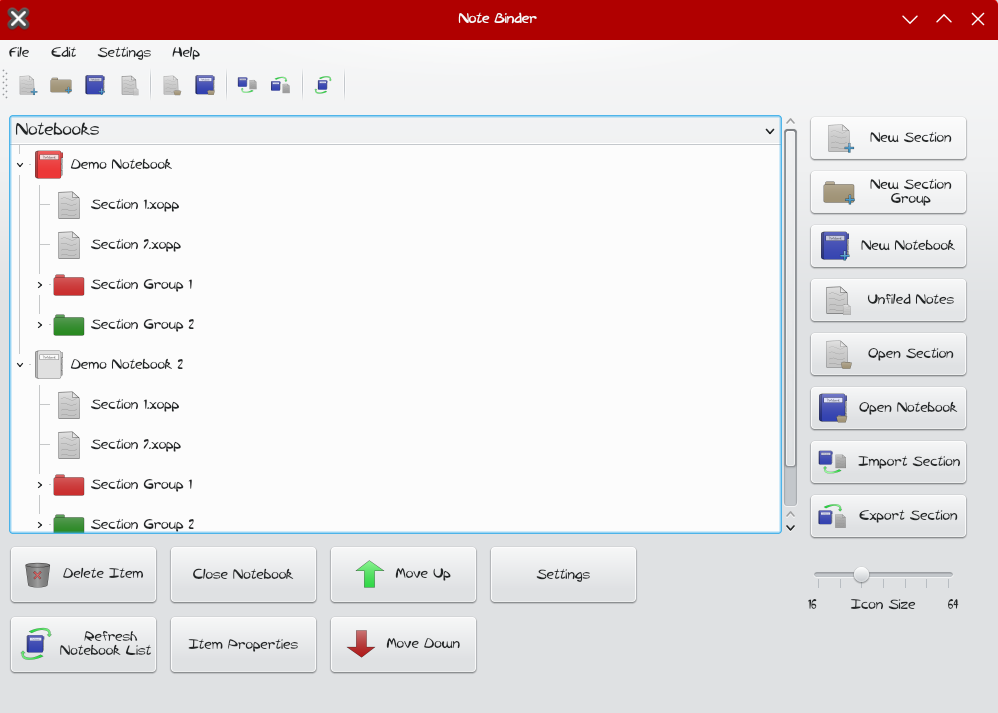
 First time posting, love the channel.
First time posting, love the channel.