Hi all,
I’m hoping someone with a bit more server experience can help me work out what’s going on here. I don’t get my hands on much proper kit so I’ve not much to compare to.
We’ve recently purchased a SuperMicro server with a 32 core EPYC 7452 on a H11SSL-C motherboard, 256GB DDR4 3200MHz, Broadcom MegaRAID 9580-8i8e with 8GB cache and backup battery.
I have 9x Samsung 1.92TB PM1643 SAS SSDs, 8x in a RAID10 and the other as a dedicated hot spare. 2x Samsung 240GB PM883s are running from the onboard MegaRAID 3008 in a RAID1 for OS.
Now, the RAID card is PCIe 4.0 and the motherboard isn’t. I’m aware of that and was told that SM wouldn’t have a PCIe 4.0 board out for a month or so.
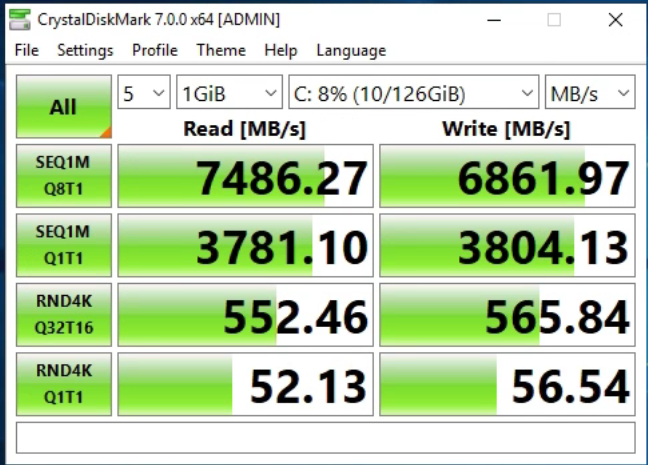
I seem to be getting rather low random 4K performance. I have been testing with CrystalDiskMark 7.0.0 on Server 2019 DC Eval on bare metal and Hyper-V Server 2019 in a VM to find roughly the same results.
I have the latest MR drivers from the Broadcom website installed and LSI Storage Authority to manage the card.
I’ve re-configured the RAID10 a few times, read ahead on/off, write through on/off, disk cache on/off etc.
Stripe size I’ve tried most of them, 64K, 256K, 512K, 1MB etc.
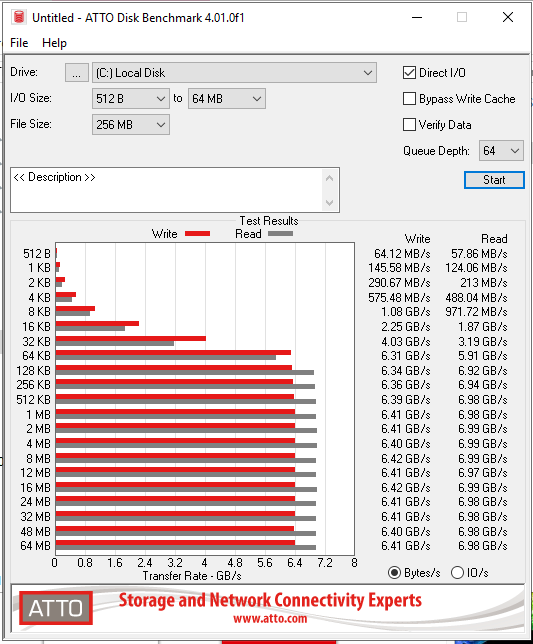
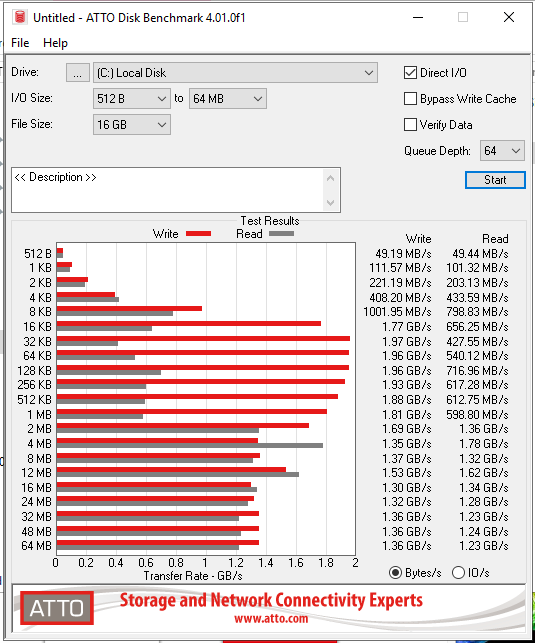
Here’s a screenshot of CDM:
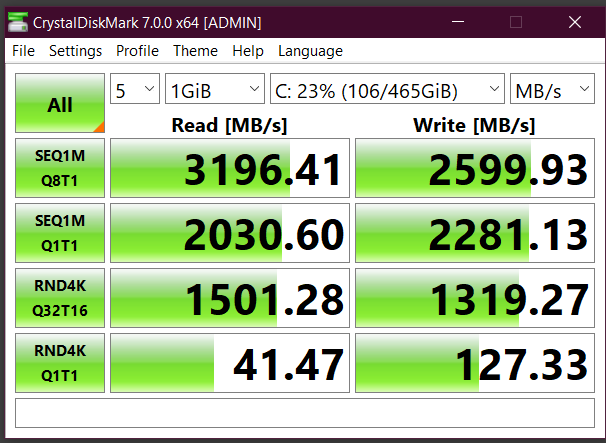
Here’s the same run on my WD Black NVMe at home, just the one drive:
I’ve tested with ATTO too and the performance is the same.
I’m really hoping I’ve missed something massive that is causing the speed issues because this is some expensive kit being beaten by a sub £100 consumer drive.
Any input much appreciated.
Thanks,