Well i suppose that AMD likely has those boards in house,
so they could try to reproduce the problem.
I cannot remember that i have read many other complaints,
from users that use different motherboards.
Mainly only Gigabyte Aorus Master and Extreme users.
So this is kinda interesting.
Any update on this? Trying to figure out if I should buy a Gigabyte or ASUS board for a 3960X.
Not much definite stuff that I can say right now - AMD is looking into it; big company is a bit slow. In my opinion, the issue i have is Bios-fixable, if you will even have it.
Also, complaints are mainly about the MASTER and EXTREME - Designare seems fine (Wendell tested it) although the sample size is not large enough for any kind of prediction.
For now, i suggest you buy ASUS, if you find a board you like and it is the same price. If ASUS is a compromise for you, then buy Gigabyte. This thread is only a hint to an existing problem, by no means does it guarantee that you will suffer.
In general, you will only suffer from not having a PC if you RMA your parts. Now, since you are aware of the issue, you can test this right away and simply use your 14-day return right with a pretty good money back guarantee.
1 Like
FYI, someone with an ASUS Zenith II Extreme Alpha and a 3970X just reported a similar issue:
1 Like
This is getting interesting with every new post! Keep all of us updated!
1 Like
Guys, an update:
Basically this whole Prime95-stability issue has been resolved on a technical level, but it is not out yet. So if you were uncertain to buy a Threadripper or Gigabyte-MoBo, dont be, its fine.
- The VRM issue was real. Gigabyte has a fix. (as expected)
- The P95-stability issue was not only due to the VRM-flaw but also because of an AGESA-flaw.
BOTH issues cause P95-instability. This was confusing to diagnose since people with- and without the VRM problem may have experienced problems.
I first believed that all systems that crashed must have had the VRM-issue - but that wasnt the case. I initially thought it was a measurement mistake or just a hard-to-measure level of VRM-misbehavior. (If crashing systems were diagnosed with “good” VRMs)
To anyone who observed the Gigabyte Bios releases, this was a funny to watch chaos over the last few days.
Basically any Bios version F4x is flawed (old AGESA, no VRM fix; which does not mean your system is inherently unstable, but it could be )
Then Gigabyte came out with F5b which fixed the VRM bug. But to the anger of AMD this was an uncoordinated release and did not include the new AGESA version which would have fixed all problems at once. So Gigabyte pulled F5b and pushed F5c (which is currently the most recent Bios online). This Bios has now the new AGESA to fix P95, but funny enough, it does not include the VRM fix.
I am pretty sure, that quite soon, there will be a F5d-bios or something that will include both fixes and “everything just works”.
Once this is out, the Vcore will look like this:
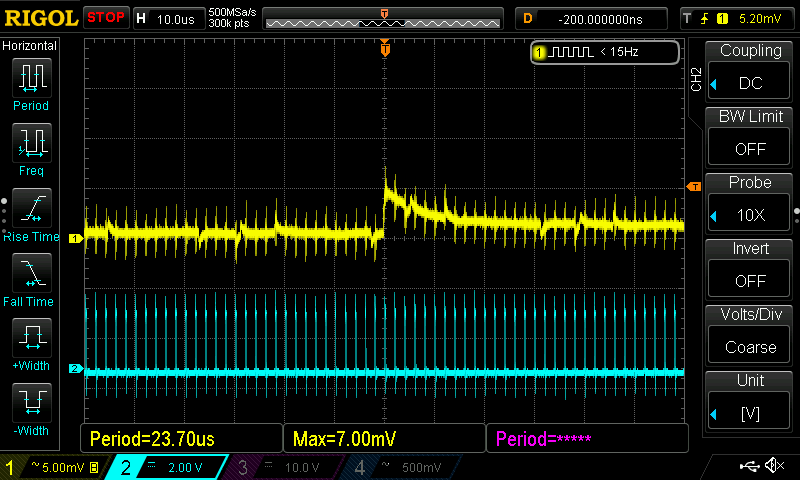
THIS IS PERFECT! (captured with the short-lived F5b bios; P95 was still crashing due to AGESA-problems)
As a reminder, a load decrease (the voltage jump you see above) caused missing switching cycles before, during which the low side mosfets were turned on, resulting in a violent discharge of Vcore. Here is some detail:
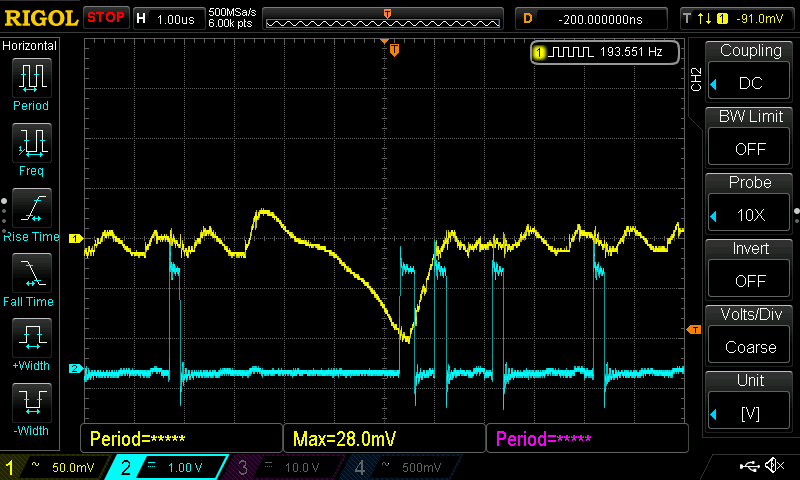
(Captured with the current F5c-bios)
I am currently staying on the F5c bios since the new AGESA version does make my PC more stable in light-load scenarios. I am currently running 60h without crash (the age of F5c) - this was unthinkable before.
However under high load the VRM bug still causes CPU-failure.
Again, i think this will be fixed very soon (it should be trivial). So everything is good.
What was it like to work with AMD?
Well, there was no working WITH or FOR them. Its a big company with big policies - it is pretty much a one way communication. No juicy details leave AMD, which at times was quite annoying; specially as an interested engineer, i would have preferred some details-but-not-details, basically a summary for idiots at least. The one way communication left me quite frustrated at times - especially when AMD hinted that they werent completely sure if they addressed the right issue or not (they did). But it sparked the urge to help or double-check, which was impossible. (Those issues are all about replicating the original problem which can be extremely hard, specially if the problems are statistical in nature and only communicated via email in written form in English as a 2nd language)
AMDs motivation to solve the issue was/is crazy high. People really care to provide a good product and a good experience. The only thing that bothers me is how broken the customer support is - i guess it is fine when you have a normal RMA but true technical issues dont come through.
The fact that this issue was solved so quickly seems like a big coincidence. (Thanks forum!)
It boggles the mind what AMD can do with software configuration to their processors. Those systems are incredible if you even try to understand the details that must go into them.
All in all a super cool experience 
8 Likes
Did Gigabyte made any statements about the actual,
vrm bug, or lets say the bios bug?
Because i´m kinda curious about that.
No, there was no communication to Giagbyte at all. AMD was my/our interface the whole time.
However you can ask me details. I am pretty confident that i am understanding the VRM problem good enough to give educated answers.
Oh an in case you want to know:
Bios F5b (which fixed the VRM) was described along the lines… “memory compatibility improvement”  yeah, right.
yeah, right.
Well since this is not actually the first time that Gigabyte,
was having vrm issues with TRX40 boards.
So i’m kinda currious what the actual bug is.
To my best knowledge:
This is a simple configuration failure. Those VRMs alone are incredibly complex systems (from a control-theory point of view) They are very customizable and even their regulation response time can be programmed (to some extent) and stuff.
Those VRMs have so many features that it is easy to misconfigure them.
The particular effect you see here is a result of missing switching cycles (or cycles with a duty cycle of 0%). The failure always occurs after a load decrease (you can see the voltage rising slightly before the failure).
The missing Power-stage pulses can be caused by 4 things:
- a over-voltage protection based on the voltage-slope. Maybe if Voltage rises too quickly, Vcore gets discharged violently in order to protect the hardware (preemptively). I am not sure if this feature exists in the chip since its datasheet is not open to the public)
- The load reduction triggers a power-saving feature of the VRM. The missing pulses could be explained by a varying switching frequency (which is enabled evidently, since it can insert pulses during recovery - effectively reaching 1MHz switching frequency). So when load decreases sufficiently, the switching frequency could be decreased to 250kHz. This would explain it perfectly.
- The VRM has an “adaptive control loop”. Such a control loop algorithm seeks to optimize load change response. This is a very complicated control-theory topic and there is much that can go wrong here. It is very well possible that this adaptable control loop just fucks up during load decrease. If the adaptability isnt contained within certain constraints, things happen.
- there are actually more things, like power stage current sharing failures, which could cause a VRM - reset/restart which could manifest this way
I am strongly in favor of option 2)
going to bed now. sorry
2 Likes
Yeah it´s probablly a miss configuration between the bios,
and the actual pwm, the Infineon XDPE132G5C.
Option 2 sounds plausible.
I believe Gigabyte normaly run their switching frequency at about 400khz.
But if in the case of the said bios it’s dynamicaly changing,
then it could definitely be a reason why it would skip cycles when load decreases.
But of course also AMD acknowledged that there also is an issue on their behalve.
So it´s likely a combination of both.
Halving switching frequencies is not a safety feature, it is about VRM efficiency. Every switching cycle creates some amount of heat from the switching alone, this is why having a lower switching frequency is inherently beneficial for the mosfets. However lower switching frequency increases the RMS-current in the inductors which is causing more heat loss in them. It is a delicate balance to find the overall minimum heat loss.
1 Like
Do you think that VRM bug affects TRX40 desinare as well (prime95 is stable here with suggested settings but everything is stock and still on air (temps hit 93C… on the NH12 I temporarly use).
Possibly but more “no” than “yes”. The VRM-Issue is very noticeable under high load. If you have stable high-load scenarios, then you can be sure you dont have an issue.
Contrary to common believe, high temperatures are not bad for your CPU. Well they are, but in a way that is certainly not relevant for you.
I found thermal paste application extremely difficult for me. The chip is so big, that the contact pressure is quite low - leading to too thick of a paste layer since it is not squeezed out to the sides. If you used generous amounts, try a little less. (rip the cooler of, and clean one side but not the other, just put the cooler back on).
On the other hand, its a 300W part. Holy shit thats an incredible heat density for the chip size. At some point it does not matter what you put on it, it is not an issue of cooling capacity but it becomes an issue of heat density at the thermal interface. So 93°C in Prime is likely fine. (imo)
If you throttle too much (below 3.5GHz during Prime95) and you are stable, just try some undervolting
1 Like
Its the first PC I assembled myself, so in regard to thermal paste I used the most conservative ‘spread a thin’ layer method. Idle temps are around 40C so its not that bad. The cooler is undersized (The NH-U14S doesn’t fit due to combination of high profile ram and case not really mean for air cooling (the 011D XL)).
The Heatkiller iV is underway though to deal with that together with MORA-420
In HWiNFO I see that package limit is at 280W, no throttling, and for some reason the sum of CPU power and SOC power is about 240W. I haven’t researched where the extra power goes.
BTW, do you know what the safe VRM temps are? On that board, someone from gigabyte thought it would be a very good practical joke to put 1100RPM (yes that is not a typo) fan on the VRM and set a default fan curve to hit that speed when VRM reaches about 60C, which means that even at idle, when VRM is at about 40C, the fan sounds like a vacuum cleaner (about 5000-6000 rpm), so I set a custom fan curve to deal with that but I wonder how far I can push VRM without overheating it.
Haha yes, the first thing i did was to disconnect the VRM fan with the original bios. That this fan is controllable was not until a later bios version. It is ridicules. I have set mine to enable above 70°C.
I am not sure where the temps are measured so there is no educated answer i can give. But 70°C and above are fine.
Lets put it this way: the VRM has an over-temperature shutdown. If you manage to trigger that, you might consider changing a setting. It is impossible to destroy the VRM through heat, so just go for it.
Btw: I have heatkiller iV + 420. Dont be disappointed if your temperatures rach 85+degC 
VRMs are OK until 90-95 °C.
Technically most powerstages have thermal limits higher than that, 100-135 °C , but the capacitors around the powerstage will not be too happy with those kinds of temperatures for extended periods of time.
Yeah i know, mosfets don’t like high switching frequency at all.
Because it produce a tremendous amount of heat.
So yeah in terms of heat production a lower switching frequency is better for the fets.
However the down side of lower switching frequency is that it increases ripple current.
Because the slower the switching cycle, the higher the ripple amplitude.
And with the skipping cycles, then yeah…
It will increase more loss in the inductors then indeed.
It’s a pretty complex story that i don’t want to go too deeply into right now.
Because that would be something for a another time, lots of write up work.
But yeah gigabyte likely did something wrong with their bios.
And will likely being fixed with the new bios update.
When Gigabyte eventually does come out with a statement,
then it will likely be a pile of nonsene.
Still of course there is a problem at two sides.
Because AMD also comes with a Agesa update.
So yeah we will see when the initial bios update comes,
out with the fix and new Agesa.
A processor running hot has NOTHING to do with VRM control loop behavior. (which this problem was)
I was getting about 72 °C on the most intense P95 torture test with a NH-U14S TR4-SP3 + a second NF-A15 fan, in an open case.
I’m temporarily on an ASUS Zenith II Extreme Alpha (I have it, it’s a much inferior board to the GIGABYTE TRX40 Aorus Xtreme IMHO, despite what most reviews say) and I’m now getting way higher temperatures, around 80 °C I think (I will retest), with the same cooler and an open case.
Keep in mind that this isn’t a fair, scientific comparison of the two boards, first of all because I’m also temporarily on another 3970X, and because there are necessarily some variations between the setups, e.g. silicon lottery, thermal paste application, etc.
UPDATE: After 20 minutes of P95 in Small FFTs test on the ASUS board, the CPU is at 76 °C (Tdie) and the chipset is at 56.3 °C. Ambient is at 20 °C.