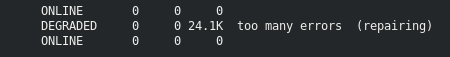I got this recently and wanted to see if anyone can help interpret the smart data… because zfs thinks the disk is bad…
I dont really think anything is wrong with the drive… but im not 100% sure.
zpool status -v
pool: ironw4tb
state: ONLINE
status: One or more devices has experienced an unrecoverable error. An
attempt was made to correct the error. Applications are unaffected.
action: Determine if the device needs to be replaced, and clear the errors
using 'zpool clear' or replace the device with 'zpool replace'.
see: http://zfsonlinux.org/msg/ZFS-8000-9P
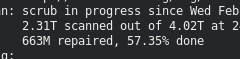
scan: scrub in progress since Wed Feb 20 17:30:03 2019
437G scanned out of 4.02T at 275M/s, 3h48m to go
24K repaired, 10.60% done
config:
NAME STATE READ WRITE CKSUM
ironw4tb ONLINE 0 0 0
raidz1-0 ONLINE 0 0 0
wwn-0x5000c5035a8e26-part1 ONLINE 0 0 0
wwn-0x5000c5035b602f-part1 ONLINE 0 0 0
wwn-0x5000c5035b9eac-part1 ONLINE 0 0 0
wwn-0x5000c5035bc732-part1 ONLINE 0 0 0
wwn-0x5000c5035c051a-part1 ONLINE 0 0 0
wwn-0x5000c5000f2abd-part1 ONLINE 0 0 1 (repairing)
wwn-0x5000c50076120f-part1 ONLINE 0 0 0
logs
nvme-INTEL_SSDPE21D480GA-part2 ONLINE 0 0 0
cache
nvme0n1p1 ONLINE 0 0 0
errors: No known data errors
smartctl 6.5 2016-05-07 r4318 [x86_64-linux-4.17.12-100.fc27.x86_64] (local build)
Copyright (C) 2002-16, Bruce Allen, Christian Franke, www.smartmontools.org
=== START OF INFORMATION SECTION ===
Device Model: ST4000VN008-2DR166
Serial Number: ZDHG
LU WWN Device Id: 5 000c50 0b00f2abd
Firmware Version: SC60
User Capacity: 4,000,787,030,016 bytes [4.00 TB]
Sector Sizes: 512 bytes logical, 4096 bytes physical
Rotation Rate: 5980 rpm
Form Factor: 3.5 inches
Device is: Not in smartctl database [for details use: -P showall]
ATA Version is: ACS-3 T13/2161-D revision 5
SATA Version is: SATA 3.1, 6.0 Gb/s (current: 6.0 Gb/s)
Local Time is: Wed Feb 20 17:55:14 2019 EST
SMART support is: Available - device has SMART capability.
SMART support is: Enabled
=== START OF READ SMART DATA SECTION ===
SMART overall-health self-assessment test result: PASSED
General SMART Values:
Offline data collection status: (0x00) Offline data collection activity
was never started.
Auto Offline Data Collection: Disabled.
Self-test execution status: ( 0) The previous self-test routine completed
without error or no self-test has ever
been run.
Total time to complete Offline
data collection: ( 581) seconds.
Offline data collection
capabilities: (0x73) SMART execute Offline immediate.
Auto Offline data collection on/off support.
Suspend Offline collection upon new
command.
No Offline surface scan supported.
Self-test supported.
Conveyance Self-test supported.
Selective Self-test supported.
SMART capabilities: (0x0003) Saves SMART data before entering
power-saving mode.
Supports SMART auto save timer.
Error logging capability: (0x01) Error logging supported.
General Purpose Logging supported.
Short self-test routine
recommended polling time: ( 1) minutes.
Extended self-test routine
recommended polling time: ( 633) minutes.
Conveyance self-test routine
recommended polling time: ( 2) minutes.
SCT capabilities: (0x50bd) SCT Status supported.
SCT Error Recovery Control supported.
SCT Feature Control supported.
SCT Data Table supported.
SMART Attributes Data Structure revision number: 10
Vendor Specific SMART Attributes with Thresholds:
ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE
1 Raw_Read_Error_Rate 0x000f 082 064 044 Pre-fail Always - 168403018
3 Spin_Up_Time 0x0003 094 094 000 Pre-fail Always - 0
4 Start_Stop_Count 0x0032 100 100 020 Old_age Always - 14
5 Reallocated_Sector_Ct 0x0033 100 100 010 Pre-fail Always - 0
7 Seek_Error_Rate 0x000f 084 060 045 Pre-fail Always - 264132714
9 Power_On_Hours 0x0032 093 093 000 Old_age Always - 6282 (86 200 0)
10 Spin_Retry_Count 0x0013 100 100 097 Pre-fail Always - 0
12 Power_Cycle_Count 0x0032 100 100 020 Old_age Always - 14
184 End-to-End_Error 0x0032 100 100 099 Old_age Always - 0
187 Reported_Uncorrect 0x0032 100 100 000 Old_age Always - 0
188 Command_Timeout 0x0032 100 100 000 Old_age Always - 0
189 High_Fly_Writes 0x003a 100 100 000 Old_age Always - 0
190 Airflow_Temperature_Cel 0x0022 072 065 040 Old_age Always - 28 (Min/Max 19/28)
191 G-Sense_Error_Rate 0x0032 100 100 000 Old_age Always - 0
192 Power-Off_Retract_Count 0x0032 100 100 000 Old_age Always - 0
193 Load_Cycle_Count 0x0032 097 097 000 Old_age Always - 6350
194 Temperature_Celsius 0x0022 028 040 000 Old_age Always - 28 (0 18 0 0 0)
197 Current_Pending_Sector 0x0012 100 100 000 Old_age Always - 0
198 Offline_Uncorrectable 0x0010 100 100 000 Old_age Offline - 0
199 UDMA_CRC_Error_Count 0x003e 200 184 000 Old_age Always - 77
240 Head_Flying_Hours 0x0000 100 253 000 Old_age Offline - 5677 (202 146 0)
241 Total_LBAs_Written 0x0000 100 253 000 Old_age Offline - 3548892120
242 Total_LBAs_Read 0x0000 100 253 000 Old_age Offline - 7252203119
SMART Error Log Version: 1
No Errors Logged
SMART Self-test log structure revision number 1
No self-tests have been logged. [To run self-tests, use: smartctl -t]
SMART Selective self-test log data structure revision number 1
SPAN MIN_LBA MAX_LBA CURRENT_TEST_STATUS
1 0 0 Not_testing
2 0 0 Not_testing
3 0 0 Not_testing
4 0 0 Not_testing
5 0 0 Not_testing
Selective self-test flags (0x0):
After scanning selected spans, do NOT read-scan remainder of disk.
If Selective self-test is pending on power-up, resume after 0 minute delay.