Hello, I wanted to start a thread about server backup solutions and your experiences with them. I’m managing quite a few centos 7 servers, and data loss is always on my mind, just didn’t have time or possibility to try out more solutions. It would be a big problem for me, if I somehow lost data, literally the worst thing I can imagine ![]() . Curious if borg is a good choice.
. Curious if borg is a good choice.
Tried some commercial solutions(synology’s active backup, r1soft, synconix), they were all horrible and with serious bugs, not to mention expensive.
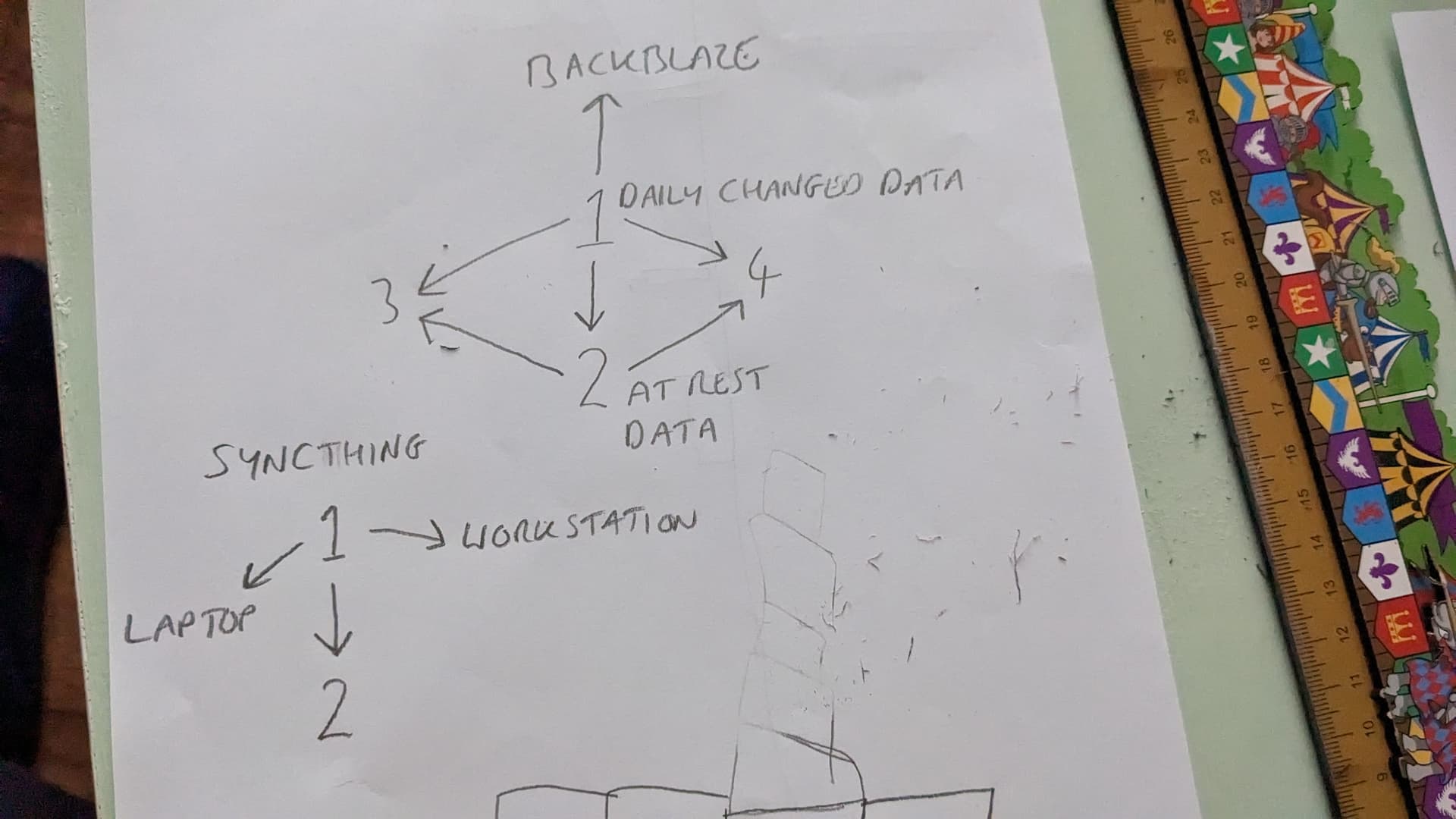
I’ve been using borg with borgbase as host. It’s fast and didn’t have issues with retrieving files from backup, the few times I’ve needed them. The host is really cheap, 12€ a year.
I know about Hetzner’s storage box, it’s compatible with a lot protocols, that’s next on my list to try as host.
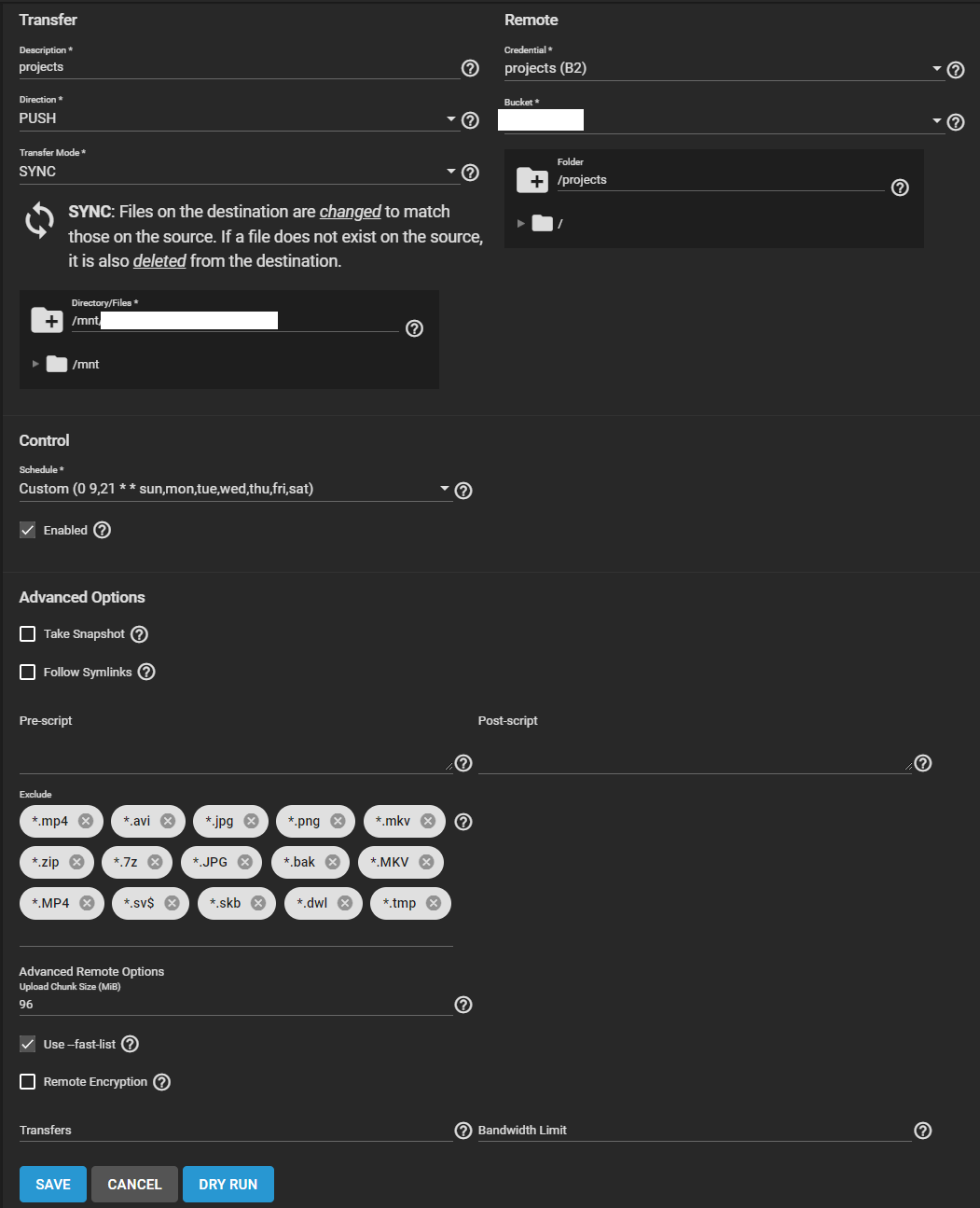
I also use rclone with storj to store a local borg backup for a personal vps.
My favorite things about borg and necessary criterias for other software:
- no need to open ports and run some service on the client machine for it
- encryption
- differential (maybe incremental, not sure if it’s a good idea with more than years worth of daily backups)
- compression
- cheap hosting available
- saving unix permissions
- corruption resistant (afaik borg is, if you verify periodically)
Did you have problems with borg?
Do you guys have experience with other software, that more or less fit the above list? I looked at a few, but I can’t decide without trying them out for a few weeks each. Contenders right now are restic, duplicity, duplicati, rsnapshot with cryptshot(rsnapshot inside luks)
Extra:
Do you think about disaster recovery? How would you go about it in case of physical servers and virtual too. I know about rear, just not sure how to save recovery images efficiently or make image from existing borg backup. Also I’m not sure if I could convince my vps host to run a recovery image for me. So I would like something that might be able to restore server to a previous state if I have at least ssh or command line access(novnc).