Update on my end. I decided to forgo RMAing the board and instead just bought a new one. I switched to an ASUS ROG Crosshair VIII Hero about two weeks ago and haven’t had any problems since. At this point I’m fairly confident it was the motherboard.
2 Likes
@agurenko Regarding your question on the GPU - I am using ZOTAC Gaming GeForce RTX 2080 SUPER Triple Fan-Edition.
What do you mean by saying ‘windows driver seems to be better handling hangs …’? Don’t you use any nVidia drivers on your wife’s PC at all?
@nerDrums I meant that I’m using only Linux and she is only using Windows, hence windows AMD driver seems to be handling GPU reset better than Linux amdgpu driver. Can you try to switch your PCI-E port to gen3 mode and see if it makes the difference? I’m just guessing here, but I’m all out of options.
Also I’ve opened following defect: [mce] random reboots Machine Check: 0 Bank 5: bea0000000000108 (#1551) · Issues · drm / amd · GitLab
Keep us posted with the results. At this point, I’m still convinced it’s a combination of factors, but since we don’t have any interested party, we’ll probably never know…
Cool keep us updated on it.
Actually I can’t really follow this instruction due to lack of knowledge  I am a simple user, so before all this I never had to make any changes in my BIOS which was a very big step for me. Tempting with the hardware is something completely differerent.
I am a simple user, so before all this I never had to make any changes in my BIOS which was a very big step for me. Tempting with the hardware is something completely differerent.
How would I switch this PCI-E port to gen3? I am using a MSI B550-A PRO motherboard with MSI Click BIOS 5.
In a BIOS go to Settings → Advanced → PCI Subsystem Settings
and change PCI_E1 Gen Switch from Auto to Gen3.
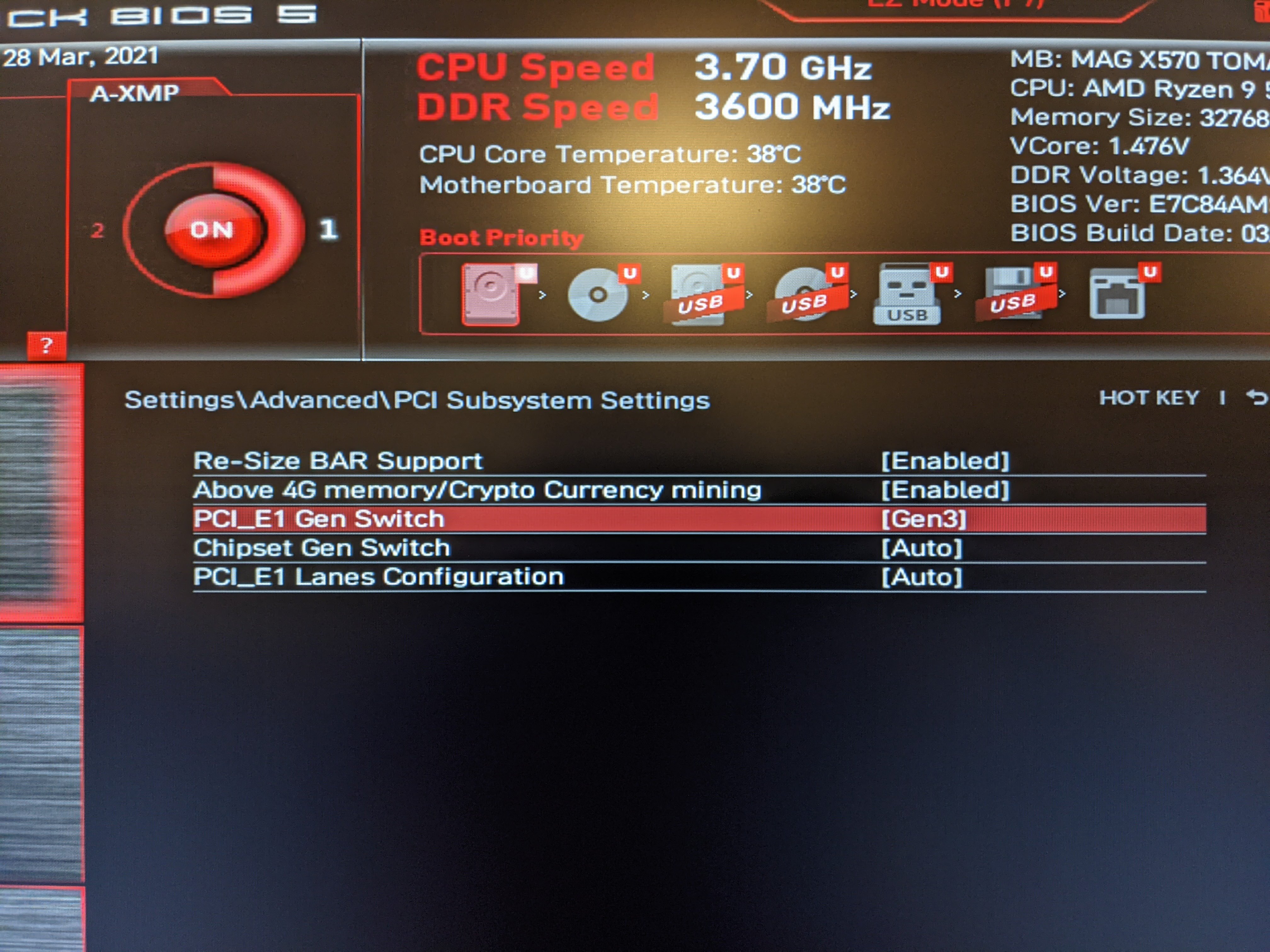
I couldn’t find if it also switches nvme port to gen3, but I would guess so.
Not sure about the B550 boards, but AFAIK nvme 0 and PCIe x16 port 0 both connected to the CPU and that’s the switch for that as I have separate switch for the PCIe ports connected to the chipset (X570 in my case), which you probably don’t have.
1 Like
@agurenko So, I checked and found the settings you mentioned - thanks for the guidance. But please tell me what exactely does this do? What is the difference if it’s on Auto or Gen3?
Btw. sorry for the late answer. I was busy all week long but now it’s four days off for the Easter holidays. Hope you guys have a good weekend!
Auto is what MSI calls the default. Gen3 forces PCIe Gen3 speeds for the Primary GPU slot.
I still got one restart in last week, but it only happened once so far, so generally my stability greatly improved, so it does not look like it’s a permanent solution, but no one is looking into BZs or amdgpu reports, so we’ll have to live with that I guess.
1 Like
Yes, I am, and so far only one for after sleep in 9 days.
1 Like
Just set this one as well after my PC crashed during gameplay. How about the rest of your settings - everything else are stock options, or did you amend something else as well?
Before it seemed that disabling ‘Core Performance Boost’, but leaving the CPU voltage at AUTO, has had a similar effect on my system - one crash every few days.
Happy Easter everyone!
I have stock settings, except:
- XMP profile enabled (3600 Mhz/CL16)
- SVM enabled for KVM usage
- PCIe_0 set to Gen3
The rest is untouched. As far as I can tell, only sleep mode causes resets with those settings.
1 Like
@agurenko So this PCIe_0-Setting didn’t work out for me neither  No idle crashes so far but my PC crashed two times today while ingame (Deep Rock Galactic) …
No idle crashes so far but my PC crashed two times today while ingame (Deep Rock Galactic) …
Besides PCIe_0 set to Gen3 I also only have XMP profile enabled and the rest is stock settings.
Hey, it’s been another few weeks, how is your experience so far? Do I understand correctly that with same CPU, GPU and RAM but with a new motherboard it’s running surely for you now?
That’s disappointing, because while I miss sleep mode, stability-wise my system is okay-ish now. Got only 2 out 3 resets in few weeks which is the best improvement I had so far.
I am having similar issues, but not exactly identical to anyone else in the thread. I suspect it is a Motherboard issue, and am about to start an RMA process with ASUS after posting here.
If anyone wants to suggest anything, I would love to learn more ways to troubleshoot! However, my main goal is to add some data points—to add my voice to the chorus having these issues and say “You’re not alone!”
Behavior (summary):
Locks for a moment, then reboots. Occasionally hard-locks (no reboot) if ECC is disabled. A more detailed explanation follows the System description.
System:
Mobo:
ASUS Pro WS X570-ACE (across several BIOS versions)
CPU:
Ryzen 9 5950X
RAM:
4x Kingston KSM32ED8/32ME, per the motherboard QVL (128GB Total, ECC UDIMMs)
PSU:
Seasonic PRIME 850W Gold
GPU:
Some old Gigabyte RX 580.
Storage:
- 2x Samsung 970 EVO Plus 1TB in ZFS Mirror, via ASUS PCIe 4.0 Hyper M.2 Card
- 8x Crucial MX500 1TB in ZFS RAIDZ2 via LSI 9207-8i HBA
OS:
Linux Mint 20.1 Cinnamon. Effectively Ubuntu 20.04 LTS.
However, I have compiled and installed several kernels, and upgraded ZFS versions, in the course of my attempted debugging.
Nothing is overclocked. Everything is set to stock speeds, voltages, etc.
I never do that until later in a product’s lifecycle (e.g. beyond any warranty time).
I would be happy to just get the parts working as they ought to be, out-of-the-box.
Behavior (description):
Locks for a moment, then reboots.
Occasionally hard-locks (no reboot occurs) if ECC is disabled. Sometimes will still reboot even without ECC, seems about 50/50. Also occasionally, when ECC is disabled, I will lose audio, power to USB devices, or ethernet first, and sometimes don’t get a UI lock/halt until 1-2 minutes later.
With ECC enabled, I have never observed these more gradual failures. It has always just been a swift reboot within 5 of any UI freeze.
- Primarily experienced during heavy I/O, but sometimes randomly under light desktop use.
- Ignoring situations where I was forcing a repro of the issue while trying to fix it, I get a “natural” occurrence anywhere from 1 to 4 times per day.
- Strangely, it has never occurred under heavy CPU load. Having compiled the Linux kernel, with all 32 threads pinned to 99-100% a dozen times, has never caused the issue.
- It has only occurred once while the machine was unattended: locked at a screensaver.
- I have never attempted to put the machine into sleep/suspend.
A little more on what I mean by “primarily during heavy I/O”:
I can reliably trigger the behavior at-will just by running zpool scrub on either of the pools (the NVMe SSDs or the SATA SSDs). Some times it happens in under 30 seconds, sometimes only after 3-4 minutes and progressing through much of the larger pool’s 3TB utilized space. Sometimes it will complete on one pool or the other (I estimate 1 out of 10 times). But when making incremental changes to study/rectify this behavior, I was able to reliably reproduce via ZFS scrub. On a tragicomic note, because ZFS will pick up the scrub again after the reboot, a few times I was caught in a boot loop for 2 or 3 boots, unable to log in and cancel the scrub before another lock-and-reboot was triggered.
Additionally, this is a machine I am trying to use for Real Work™, so I tested a moderate ETL workload. It chews through about 100GB of data, out-of-and-back-into PostgreSQL. This workload will also reliably trigger a lock (and reboot) after anywhere from 10 seconds to a minute. It seems to cause the issue faster than zfs scrub, but I haven’t measured closely enough to conclude that for sure. It might just be my perception. However, while a zpool scrub has succeeded on rare occasions, this ETL task has never succeeded.
Regarding the “gradual failure” of USB or audio:
While I have been debugging this (mostly via scrub) I will keep a second monitor split-screened between htop and watch zpool status. So when I lose networking, it is evident that other things are still running. When I lose mouse and keyboard lose power, I have tried moving them to other USB ports, with no success, but I can still see htop going and the scrub chugging along… for a minute or so? Regardless of which goes out firs,t it all locks and reboots.
Behavior (logs):
I have never seen any record of the issue under the previous boot’s journals, i.e. journalctl -b -1 never has anything interesting or out-of-place at the end of its logs.
I will sometimes see issues after boot, i.e. logs in dmesg or journalctl -b 0 will show some of the same Machine Check Errors, or EDAC memory errors, but it is inconsistent. Sometimes MCE, sometimes EDAC, sometimes neither, and sometimes both. If I had to place a frequency on it, I would estimate it at 50% one of those errors, 25% both, and 25% neither. Rough estimates. With ECC disabled I never see the EDAC error (obviously).
A sample of MCE from journalctl:
May 06 00:07:43 mittermeyer kernel: mce: [Hardware Error]: CPU 22: Machine Check: 0 Bank 0: bc00080001010135
May 06 00:07:43 mittermeyer kernel: mce: [Hardware Error]: TSC 0 ADDR 17ca9dce00 MISC d012000000000000 IPID 1000b000000000
May 06 00:07:43 mittermeyer kernel: mce: [Hardware Error]: PROCESSOR 2:a20f10 TIME 1620277647 SOCKET 0 APIC d microcode a201009
Note: the CPU for the error has jumped around a bit. Out of eleven occurrences, five are on CPU 22, but the other six are across CPUs 0, 5, 6 and 7. Additionally, the MCE is only ever for one core at a time, never more than one per failure.
A sample of EDAC from dmesg:
[ 19.403706] EDAC amd64: F19h detected (node 0).
[ 19.403713] EDAC amd64: Error: F0 not found, device 0x1650 (broken BIOS?)
[ 19.404416] EDAC amd64: Error: Error probing instance: 0
Note: this “(broken BIOS?)” has always been present, regardless of UEFI version.
Attempted solutions, roughly in order:
BIOS:
- Upgraded BIOS to version from 3204 (2021/01/29, AGESA V2 PI 1.2.0.0) to 3402 (2021/03/23, AGESA V2 PI 1.2.0.1 Patch A). Issue persisted.
- Changed UEFI Setting “Power Supply Idle Control”: From “Auto” to “Typical Current”. Issue persisted. Kept setting at “Typical Current”.
- Changed UEFI Setting “Global C-State Control”: From “Auto” to “Disabled”. Issue persisted. Kept setting at “Disabled”.
- Changed UEFI Setting “SVM Mode”: From “Enabled” to “Disabled”. Issue persisted. Returned setting to “Enabled”.
- Changed UEFI Setting “DRAM ECC Enable”: From “Enabled” to “Disabled”. Issue persisted. Have alternated this several times in conjunction with other changes, for the sake of gathering data.
Power Supply Swap:
Issue persisted.
It is worth noting the current PSU is not new, and came from a system that was MUCH more power-hungry (an overclocked X58 monstrosity).
The other PSU tested was only a 650W, and although I would be nervous about its capacity if I were slamming the CPU and GPU at once, I didn’t need to do so. I barely use the GPU to its capacity. Per sensors it is almost never drawing more than 50W (most of the time sits around 35W). The CPU does not get more than 50% utilization with zpool scrub, but the freezes and reboots persist on this 650W PSU.
I have since returned the original 850W 80+ Gold PSU to this machine, as the 650W is actively used by another system.
Linux Kernel Upgrades:
- 5.4.0-72, which came with Mint 20.1.
- 5.8.0-80, which was available in out-of-the-box apt repos.
- 5.10.35, which was built from source. I am led to believe 5.10 added better Zen 3 support, at least as it relates to scheduling?
For what it’s worth, I had intended to move to 5.10 anyway, because I prefer LTS kernels wherever possible, but compiling it required me to transition to ZFS 2.0 from the 0.8.3 that I was using, so I first tried 5.8.0 which was the highest I could go without having to introduce the ZFS change as well.
I may be fooling myself, but it feels like the EDAC log errors show up a little less since 5.10 kernel, but this is only a sample size of less than 20 lockup/reboot incidents since that upgrade, and the EDAC error has definitely still appeared.
I have not tested in Windows, nor do I have access to any Windows keys, and know nothing about diagnosing hardware via Windows. Beyond that, the fact is that if the machine cannot be made to work in Linux, then the machine will not be useful to me. So involving Windows seems like a bit of a “shrug emoji” situation.
Analysis/Theories:
Here are the things which I believe are not the point of failure, and why.
Not the PSU:
Tried another, plus this PSU has been in another system where it provided months of uptime.
Not CPU Cooling:
I admit I cannot measure (Zen 3 temperatures aren’t available until Kernel 5.12). However!
- The cooler is a Scythe Fuma 2, and it sits in a deep 4U case with ALL THE FANS.
- CPU intensive workloads (i.e. compiling for a few minutes of 32 cores at 100%) has never caused a lock.
- The lock has occurred even when CPU load is barely 25%.
- In UEFI (where I can measure temperature), the CPU idles between 48 and 50C, depending on ambient.
- I re-pasted and re-seated the CPU cooler at one point, just as a sanity check, and it had no impact.
Not the GPU:
No graphical bugs, no logs indicating any issues. AMDGPU Polaris drivers are probably the most stable Linux graphics drivers I have ever experienced. I have not gone so far as to swap it for another GPU (best I have is a half-height RX 550 sitting in a server somewhere). However, it also came from that now-retired X58 system where it served its boring, non-gaming duty well for nearly three years.
Not System RAM:
I have a paid Memtest86 License and cleared two full tests (including ECC injection), each test requiring 13-14 hours for the full 128GB.
Regarding ECC, the issue persists when ECC is disabled. And of course these modules are SKUs direct from the QVL.
Not the LSI HBA:
Because I first noticed the issue on an inaugural zpool scrub, I truly thought it was this at first. Just a bad PCIe card causing a cascade of shenanigans.
It is definitely beyond my depth to guess here (that is to say: what follows is B.S.), but letting my imagination wander, my fears jumped to some spoooOOOoooky PCIe bus shenanigans, or maybe some DMA shenanigans or just… again beyond my depth. But (gestures toward a pile of PCBs) complex electrical shenanigans!
Anyway, the same issue occurs from workloads that are purely accessing the NVMe drives. So either it is neither of those, or it is something other factor they share in common.
Not the X570 Chipset (probably?):
The LSI HBA sits on the PCIe x8 that hangs off of the chipset.
The two NVMe SSDs are attached to directly to the CPU.
Heavy I/O on either can cause the issue.
During ‘gradual failure’ scenarios, loss of Ethernet does not involve the chipset.
Conclusion?
I suspect either the Motherboard or the CPU and am leaning heavily on the Motherboard for three reasons:
- Sustained, heavy CPU workloads does not cause a lock.
- That the issue is I/O related, but doesn’t seem to involve memory.
- The occasional ‘gradual failure’ scenario where USB, Ethernet or Audio drop out before a full lock.
I have also performed a cursory visual inspection of the motherboard. I see nothing ‘obviously’ damaged, but I am not experienced enough to truly know what to look for.
There is a possibility that it is some obscure CPU issue (as an arbitrary example), like a core’s L2 cache, but I do not have the knowledge to even begin to guess anything in that realm.
Again, if anyone wants to suggest anything, I would love to learn more ways to troubleshoot, but really just want to share my story an thank y’all for this thread. It gave many good ideas of what to test along the way, even if none of them wound up being a solution.
1 Like
What is your Soc voltage running at?
I was going to say “Whatever the default is, I haven’t overclocked anything.” but I suppose the reason you ask is that it isn’t something that is standard? As I said, I rarely fiddle with those because I am quite fearful to not void any warranties, and so forth (specifically for cases like my current one).
But I hadn’t yet mailed the mobo for RMA, so I unpacked it, and took some photos of the UEFI for my records. These voltages all appear under an interface tab named “Ai Tweaker”:
- CPU Core Voltage: “Auto” 1.441V
- CPU SOC Voltage: “Auto” 0.992V
- DRAM Voltage: “Auto” 1.200V
- VDDG CCD Voltage Control: “Auto”
- VDDG IOD Voltage Control: “Auto”
- CLDO VDDP Voltage: “Auto”
- 1.00V SB Voltage: “Auto” 1.000V
- 1.8V PLL Voltage: “Auto” 1.793V
These are just whatever out-of-the-box values the decision-making-magic of the UEFI and CPU set them as.
I will feel quite sheepish if I spend a month RMA-ing this board when there is an accessible fix. The main question I have is whether voltages are something that I can safely change within my warranty. If you have any ideas, I’ll ask ASUS support if such a change is within warranty and give it a shot… it would be great for this to go away so easily 
That’s a little bit low.
Maybe you could try to set it to 1.1V and see if that helps some.
1 Like