FPGAs and PLAs are not magical “software to amazing hardware”-adapters. They are just options to have somewhat high speed (meaning high switching frequency) without needing dedicated logic gates to allow for some degree of customization on the fly (or on startup, depends on implementation).
The fundamental problem with FPGAs is that you need to emulate dedicated hardware through hardware and software making it more complex and more expensive compared to dedicated hardware.
IIRC the fastest FPGAs are made by “Xilinx” and cost somewhere arround 60,000 (60 thousand) dollars a piece. Compared to modern CPUs, you get 700GFLOPS at 50ish Watt (14GFLOP per W) compared to Radeon Instinct MI8, that is a bad joke (8200GFLOP at 180W, ~47GLOPS per W).
Applications talk to Windows using DirectX
Windows talks to the GPU using WDDM
Thus there doesn’t have to be any DirectX related code on the GPU. You are right though, there is a rendering engine on the card. But this is what I’ve been trying to tell you from my very first post. It’s just a software rasterizer. Nothing special. Utterly useless.
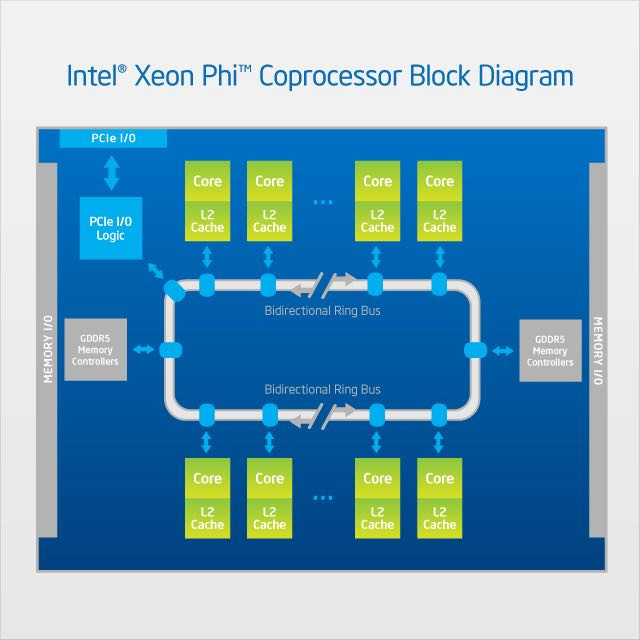
It’s a processor aimed at scientific computing and supercomputers in general. All sensible programs use GPUs such workloads, but Xeon Phis allowed executing legacy code. This is how they’ve always been marketed. Don’t fix your program, just throw money at us and we’ll make your problem go away.
Got to play with a few Xeon Phi units once.
It’s basically an array of optimized Pentium 3’s with vector extensions turned up to 9000 and the whole 9 yards of optimizations added on.
Hook those up via L2 cache into a ring network with ram stapled on and you’ve got a great general purpose compute card for complex multi threaded workloads. Unfortunately there wasn’t big demand for them because the the target market wasn’t ready.
This may be stupid, but how can a BUS not be bidrectional? If one component on the bus sends, all the other recive the whole thing. Or am I thinking too close to my beloved I2C here?
If you disassemble the code back to assembly it’s much the same either way. There are plenty of talented assembly language coders out there.
Fact is you’re going to be dealing with code written for an exotic architecture (sure, it’s still a bunch of x86 cores, but they’re connected with a high speed memory subsystem, etc. that you just don’t have) that is not commercially available and attempting to adapt it to something completely different.
I’d suggest that the commonly available drivers/libraries that already exist, on every windows install for DX11/12 would give you far more information. And even then you still need to re-implement a compatible rendering pipeline.
Which is why those who know what they’re doing have already started work on shims to just translate into an API that already exists.
There is some wisdom in not trying to use the x86 ISA for literally everything.
Linus’ video was really quite good. He did a lot of homework there and got to talk to a lot of cool people, sounds like. I’m not going to say it’s fundamentally wrong to try to make x86 into a graphics device, but well there are some things that are really tough to solve in software and have the benefits of the hardware.
Think about hardware x264 vs software x264.
Thus far I would say that graphics cards have been designed such that they can provide features for implementing, say, h265 without directly (inflexibly) implementing raw h265 in hardware. The cuda “cores” are vectorized, sure, if you want to describe it that way and built with “common” game operations in mind.
Even if the compute uint could be more like x86 cores… you’re going to add a lot of latency to the stack which offsets “gaming” performance. Whether that offset is fatal is another matter I would concede, but I would say probably that’s why we’ve seen intel waffle on this thing like crazy.
We are now getting close to hardware ray tracing, which I think perhaps swings the pendulum farther away from “massively parallel vectorized x86” (or anything really that approaches non-risc/VLIW type architectures).
Jim Keller might come up with something really neat though that is x86 compatible, but is in no way related. Long pipelines don’t work for games the way they can work for AI and computation tasks…
No, I suspect “massively parallel vectorized x86” of the future is actually sticking the basic operational computation circuity actually in the ram itself. then the compute device that’s paired with can work nicely with the workload at hand. Who knows maybe we’ll see fpgas on gpus of the futre lol…
^
definitely the future is moving the hardware components closer together, and CPUs and GPUs blending together on the same package.
Since the 90s i’ve seen first FPUs into the CPU core, then onboard graphics, then graphics in the CPU core. I’ve seen MPEG decoder cards go into the GPU and then the CPU.
Stuff like Kaby Lake G is only the start. I see HBM being used on CPU packages in general and traditional RAM becoming “second tier” (or rather, 6th tier … after registers, l1, l2, l3, HBM caches) storage.
Once all the components have been crammed together and the high speed interconnects between them become too much of a limiting factor then yes i agree we will maybe see the logic move directly onto the memory. Or rather the memory move directly into the cpu core.
It’s all going to converge… that much i think it inevitable.
edit:
HBM scaling may mean traditional memory gets relegated to secondary storage faster than we think.
Vega 20 is already rumoured to have 32 GB of HBM on it. That’s enough to be both system RAM and GPU memory for a regular user. Give it a few more years of doubling every few years and i think it’s clear that on-package (and later on-die) HBM (or something similar) will end up being primary system memory…
I can’t imagine intel wouldn’t bury his ass in legal filings if he ever did pull the OS off that thing and released it. Even if it was eventually found to be on the up & up with the FOSS licensing of BSD, the 10+ years Intel would keep him in court would bankrupt him.
I still don’t see what could be gained. You have code written for an architecture that for all intents and purposes as a consumer: does not exist. Thus, it’s not likely to be very usable for the architectures we are currently using.
We have code on every modern Windows PC out there for DX on architectures that DO exist…