He wants all that through the dicord that is listed so everyone can communicate what they are doing. Right now all he wants is building and testing on as much hardware as possible.
I’m working on an internet connected (IoT) garage door opener.
The hardware I’m using is …
- Raspberry Pi Zero W
- 8GB SD Card
- 5V 1A PSU
- 1/4 Meter Jumper Wire
- YARD Stick One
- HackRF One
- Original Garage Door Opener
The software that I’m using is …
In theory, this whole process is stright forward. You lookup the FCC ID of the garage door opener on FCC.io, and get the general area of the transmitter and then point an RTL dongle, or a HackRF One in my case to that general area. Sometimes it’s as simple as doing that with osmocom_fft but you make do and you capture it with GNURadio instead. It’s annoying, but it works.
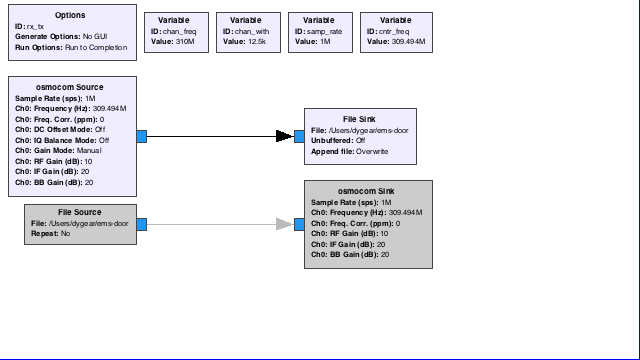
So once you’ve captured the file, you move on to using inspectrum and opening the file. You say to yourself, wow this is going great and then you realize that your waveform doesn’t line up with the other pluses down the line and you’re like … Ok, maybe this will work anyway still … But it doesn’t so you start sulking on the Level1Tech Forums. (No, I’m not bitter at all.)

Although, I will say that I’ve gotten the Socket.IO part to work no problem. I can press a button on a website and it will execute some shell code on the other computer. So, the part that I thought would be the hardest, is actually the easiest part. The part that I would think that would of been the easiest, is actually the hardest part. Odd considering how easy they make this look in all of the videos out there.
But this is around the part where I start banging my head against the keyboard.
Instead of trying to activate the opener using the transmitter, couldn’t you have the PI momentarily close an auxiliary relay that would be wired with the opener’s manual push button?
I could, in theory, but my electrical engineering skills suck. Soldering irons scare me, lol (I don’t own one. I’ve used them before in shop class like 15 years ago.)
Wrote a VIM plugin for reviewing pull requests on Github: https://github.com/AGhost-7/critiq.vim
1 Like
been thinkin a bit about doing the reorder thing…
but also, messing a bit with the loop structure, that probably gonna add some tuning options for calculating the lists
curently is the top to bottom, checks if the sublist is ready to go(basically)
to be can have it not go onto the next list if say, the list could go multiple times, let it go as many as the math lets it pass, or could have a restriction, maybe only goes one extra time at most, or do a comparison against the list total, so that you could let say the longer sublists go but not the shorter ones
just gotta figure out how to do it, for the ‘ui’ stuff, how many options to give, maybe let user put a number in themselves(for a threshold or something). lots of options but want to keep it simple, easy to understand quick/out of the way. how its described to the user, if theres a help text for it etc
edit: also might mess with the boot strap a bit… currently it just does +1 after the math stuff, so it just forces it to go the first time, but i might put it to go like +1 until theyve all gone(or some other threshold for it being properly started to where it will run itself through the loop after that normally) to then ignore the minus 1, to correct for basically, the longests lists tend to have excess episodes at the end of the list, so with the change should correct up front instead by forcing them all right away, and then the shorter ones would skip the next one basically, then on as normal after that
or could try boot strapping the longer lists only or something, but as is isnt too bad usually, the whole spreed seems to be about 10-15% at worst(how far from the end the first list ends, assuming not a list with only like 2 episodes or something)
My bread board 28c16 reader/writer: https://i.imgur.com/njBvCbr.jpg, which can read and write using only 6 gpio pins. It’s true the raspberry pi 3 has 28 programmable gpio pins; so you could just hook up all the pins directly to the pi. But that’s not much fun.
{kind=link}
The 28c16 is an eeprom with 2048 bytes of storage. So it has 11 address lines and 8 I/O lines. With the 3 8-bit shift registers, I can shift in all 11 address bits and 8 I/O bits using only 1 data pin, 1 pin for the shift clock, 1 pin for the register clock, and 1 pin to toggle a write. I used a dedicated pi pin for the write enable and output enable pins on the eeprom, but the data out/data in could be combined, and the output enable could be shifted in since there are 5 bits left over on the shift registers.
Reading is 8 times slower than writing. While the writer can write 8 bits at a time, the reader can only read 1 bit a time.
I wrote a simple c program (using the wiring pi library to handle reads and writes:
eeprom (-r [low] [high] | -w (value) [low] [high])
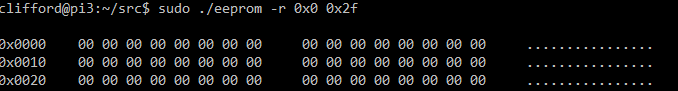
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
#include <string.h>
#include <wiringPi.h>
#include <wiringShift.h>
#define PIN_DATA 4
#define PIN_SHIFT_CL 16
#define PIN_REG_CL 15
#define PIN_OUT_EN 5
#define PIN_WR_EN 1
#define PIN_DATA_IN 6
typedef enum tagMODE { READ = 1,
WRITE = 2 } MODE;
void pulsePin(int pin, int delay) {
//delay is microseconds
int state = digitalRead(pin);
digitalWrite(pin, !state);
delayMicroseconds(delay);
digitalWrite(pin, state);
}
void shiftByte(unsigned char data) {
shiftOut(PIN_DATA, PIN_SHIFT_CL, LSBFIRST, data);
pulsePin(PIN_REG_CL, 101);
digitalWrite(PIN_DATA, LOW);
}
void programByte(unsigned short address, unsigned char data) {
unsigned char lower = (unsigned char) address;
unsigned char upper = (unsigned char) (address >> 8);
shiftByte(lower);
shiftByte(upper);
shiftByte(data);
pulsePin(PIN_WR_EN, 101);
}
unsigned char readByte(unsigned short address) {
unsigned char data = 0x00;
unsigned char lower = (unsigned char) address;
unsigned char upper = (unsigned char) (address >> 8);
for( int i = 0; i < 8; ++i ) {
unsigned char bit;
unsigned char mask = 0x1 << i;
shiftByte(lower);
shiftByte(upper);
shiftByte(mask);
bit = digitalRead(PIN_DATA_IN);
data = data | (bit << i);
}
return data;
}
void read(unsigned short low, unsigned short high) {
unsigned char data;
unsigned char buffer[17] = {0};
unsigned short length = high - low;
for( unsigned short i = 0; i <= length; ++i ) {
data = readByte((unsigned short) i);
buffer[i % 16] = data;
if( i % 16 == 0 )
printf("\n0x%.4x", low + i);
if( i % 8 == 0 )
printf(" ");
printf("%.2x ", data);
if( (i+1) % 16 == 0 ) {
printf(" ");
for( int j = 0; j < 16; ++j ) {
if( ( buffer[j] >= 'a' && buffer[j] <= 'z' ) || ( buffer[j] >= 'A' && buffer[j] <= 'Z' ) ||
( buffer[j] >= 0x20 && buffer[j] <= 0x64) || ( buffer[j] >= 0x7b && buffer[j] <= 0x7e ) )
printf("%c", buffer[j]);
else
printf(".");
}
}
}
printf("\n");
digitalWrite(PIN_OUT_EN, HIGH);
shiftByte(0x00);
}
void write(unsigned char data, unsigned short low, unsigned short high) {
unsigned short length = high - low;
for( unsigned short i = 0; i <= length; ++i ) {
programByte(low + i, data);
}
digitalWrite(PIN_OUT_EN, LOW);
}
int main(int argc, char * argv[]) {
unsigned char data;
MODE mode;
char * szMode;
unsigned short low, high;
if( argc < 2 )
return 0;
szMode = argv[1];
if( strcmp(szMode, "-r") == 0 ) {
mode = READ;
} else if ( strcmp(szMode, "-w") == 0 ) {
mode = WRITE;
}
wiringPiSetup();
pinMode(PIN_DATA, OUTPUT);
pinMode(PIN_SHIFT_CL, OUTPUT);
pinMode(PIN_REG_CL, OUTPUT);
pinMode(PIN_OUT_EN, OUTPUT);
pinMode(PIN_WR_EN, OUTPUT);
pinMode(PIN_DATA_IN, INPUT);
digitalWrite(PIN_DATA, LOW);
digitalWrite(PIN_SHIFT_CL, LOW);
digitalWrite(PIN_REG_CL, LOW);
digitalWrite(PIN_WR_EN, HIGH);
switch ( mode) {
case READ:
digitalWrite(PIN_OUT_EN, LOW);
if( argc < 3 ) {
low = 0x00;
high = 0x7ff;
} else {
low = (unsigned short) strtol(argv[2], NULL, 16);
if( argc > 3 )
high = (unsigned short) strtol(argv[3], NULL, 16);
else
high = 0x7ff;
}
read(low, high);
break;
case WRITE:
digitalWrite(PIN_OUT_EN, HIGH);
if ( argc < 3 ) {
data = 0xff;
low = 0x00;
high = 0x7ff;
} else {
data = (unsigned char) strtol(argv[2], NULL, 16);
if( argc >= 5 ) {
low = (unsigned short) strtol(argv[3], NULL, 16);
high = (unsigned short) strtol(argv[4], NULL, 16);
} else if (argc == 4) {
low = (unsigned short) strtol(argv[3], NULL, 16);
high = 0x7ff;
} else {
low = 0x00;
high = 0x7ff;
}
}
write(data, low, high);
break;
}
return 0;
}
3 Likes
no picture this time 
but just a simple thing to speed up a recurring thing with working on media server project(s),
just c command line thing, to rename all files of a given directory to lower case characters(if it finds any uppercase) for processing media
in that if you have a series and want it to play in a proper order, depending on naming convention, operating system/programs involved, having all the same case, and even numbering scheme, like having 01-09, if theres only 2 digits, or 001 etc for 3 digits and so on, as some programs whatever, go off alphabetic, nut also numeric, in which it just oes off the first digit not the whole number, so ‘episode22.mp4’ could come before ‘episode3.mp4’
but still thinking on that problem, as many different naming conventions exist, such as s01ep01, 1x01, just 01(no season identifier). but first thing that comes to mind would be if it finds more then 1 digit that isnt consecutive, but then theres what to do if the title itself has a number in it. such as (series name)-(season/episode numbers).(extension)
as i would like to be able to solve this ‘problem’, adding the beginning zeros if they arent present, and put all of the files present to be the same numbering/naming convention, with it just being able to detect what the numbering was originally to get the numbers, without causing issues if say the name had numbers, like ‘reno 911’, such as comparing the filenames to extrapolate the ‘reno 911’ isnt the number as its the same in every file(or maybe not present at all in the file if later seasons or something were just numbers no series name)
so gotta think about that one a bit :p. to ideally have no arguments need to be given other than directory
did bit more testing and had to do some minor bug fixes for specific conditions after the 1000 conversion,
but not figured out yet what to do with improving the distribution yet
or the renaming thing
not that have thought about it much lol.
Still learning but just finished this assignment for class. Setting up the functions was fairly easy but debugging stuff I messed up here and there made me take a bit longer.
https://forum.level1techs.com/t/the-lounge-2018-02-february-abandon-ship-edition/124151/577?u=theonewhoisdrunk&source_topic_id=111752
1 Like
What’s the front-end framework?
I’m learning Vue and it’s fucking gorgeous
Vue 2  for the front end, express on the backend.
for the front end, express on the backend.
Its a MEVN stack.
Specre.css for the pretty stylings.
Looks pretty good. Spectre.css? Might have to give that a try. Looks damn good. I’m using Vue 2 with bootstrap styling for the time being, but It’s still early days on my project.
Nice!
I really like Spectre. I was using bulma before that, but spectre is bit more fleshed out for what it offers.
My main gripe with bootstrap is that a lot of the advanced stuff is reliant on jquery, while spectre incorporates things like popovers in pure css.
Not to mention its like a 1/5 the size.
1 Like
This is probably even more of a meme than Angular at this point, but this is what I’m using: https://bootstrap-vue.js.org/
It’s basically a vue component library for most of the functionality of bootstrap.
Really makes it quick and easy, but I haven’t worked with it too much, I’m working heavily on Android and API at the moment.
Nice!
I don’t use bootstrap specifically because I have no need for their grid systems; because I use CSS Grid. That frees up a lot of the otherwise needed boiler plate and I am free to use more minimalist frameworks
150 KB compressed is a lot to waste on just css stylings.
My app uses the vue-cli webpack for its speed and minification.
The prod dist files are only ~900 KB in size, so it loads really speedy.
1 Like
Ah, I am very reliant on their grid system. I know it’s probably better to build something more lightweight, but this is what I’m comfortable with and I’ve got 2.5 weeks to get this project to beta and I can only devote 15-20 hours a week to it.
I’m using vue-cli webpack, but haven’t actually gotten to building prod yet. I’ll let you know when I do.
lmk if you need any help turning it into a node app.
What you visited before is a live build from my github master branch (set up with webhooks) running on a free heroku dyno.
I use express to serve the static minified files from webpack, and then have my client logic separate. In short, I am not doing server side rendering.
All client logic hooks up with the backend mongo database, with async/await (promises).
If you get some free time, look at it on github and poke around.
1 Like
I’m using a separate repo for the API (running on a free heroku dyno as well, in fact, I’ve set up a full CI/CD pipeline for it) because I’ve got people simultaneously developing Android and iOS apps. The API is working fine and I should be able to figure out deploying webpack to Heroku, but if I do run into trouble, I’ll definitely let you know.
I don’t see a github repo link. Is it up there somewhere? I’m blind, it’s in the footer.
1 Like