I'm also working on an i386 (with plans for x86_64, arm) OS. Mine's written in C/Asm and doesn't really do much, but also has PS/2, VGA, Timer, and an ext2 driver which I'm almost done writing.
It also has paging support as well as a full kernel memory manager!
Once I finish the ext2 driver I plan on adding ATA support (probably PIO mode for now) and then I'll move on to userspace.
I plan to design it in such a way that systemcalls can be easily swapped per-process so that kernel-level compatibility for other operating systems can be achieved (kind of like Wine, but in the kernel).
The full source is available here under the GPLv3 license.
Dude! Thanks so much for tutorial! Really appreciate this! And nice progress! How hard was to implement ext2 driver? Are you doing VFS atm to test it? Like in RAM?
I've been working on the ext2 driver on and off for months now. My goal is to have a fully working driver with no shortcuts, so naturally it is taking a long time. I'm writing it as a Linux usermode application because it's MUCH easier to debug with tools like GDB and Valgrind. Once it's fully done, porting it to ShawnOS should be a breeze, since it already has a VFS system.
I'm currently developing it in a separate repository here. Once it's done, I plan on testing it by loading an ext2 filesystem into RAM using Multiboot's module loading, so it'll work similar to an initramfs.
It's a monolithic kernel, as I didn't want to spend 90% of the time writing the complex communication mechanisms required for a microkernel.
The kernel itself won't directly implement any POSIX functions (or any other standardized functions for that matter). Instead, it will provide only the basic mechanisms necessary for userspace. Once that's done, I plan on implementing a POSIX systemcall layer as I briefly described above which will use the aforementioned mechanisms. This will allow me to expand it further and potentially even write a systemcall layer for Linux or NetBSD applications to run natively.
Rad man, absolutely rad. I want to reinvent as much wheels as possible, so I don't plan on porting any software. So, no POSIX for me, but your idea of userspace translation layer is pretty damn good idea.
Thanks. It's not going to be an easy task re-implementing all those syscalls, but if it works it would be really awesome.
As for reinventing the wheel, I totally get it. That was my original plan, but my goal/dream is to port existing software to the OS like gcc, a web server, and maybe even a minecraft server or something. That's why I came up with the compromise of the translation layer: internally it lets me do things my way, but it still leaves the door open for POSIX compatibility so I can port all the cool applications that already exist.
I’ve been playing with this data structure that is sort of like a sparse array implemented as a linked list, where each node stores a half-open interval [start, end) representing the range of indices stored in this node, and a sequence of values corresponding to the indices.
It’s been a fun little challenge to implement this data structure. Eventually I’m planning to extend this concept to a tree for faster access.
I recently did this for more compact sparse bit array storage! Once you have a index array built, there’s not much more a tree and offer you over binary search but you might be fighting CPU cache misses to the array formulation would probably be more performance. It The indexing structure chosen becomes a decision to trade off write performance for faster segment finding with a densely packed array, or quicker modification with a tree as array.
Been working on and off for the past year or 2 on a simple home automation system. It is no where near finished, but it is functional. It is a centralized system, all nodes talk to a central server and get talked to by a central server, not plans to make it disturbed because of my end goal with it.
The goal of the project is to be able to program your house as easily as you would you desktop environment, and to make it easy for programmers who don’t deal with electronic hardware the ability to make their own home auto system they have complete control over.
It will communicate with hardware attached to the PI via docker images that can be fed to it via the central server with a json config object and will have a unix socket to communicate value changes to the node which forwards it to the central server, currently it just takes a blob tarball containing structured JS and runs it on the system and is not stable but functions and is run inside of one global docker image.
The plan is to create a web socket API and build a wrapper in a few languages to interact with it, that way you can make your own program that will interact with the home auto system. Being able to subscribe to inputs so you get events when they change, and being able to publish to outputs to change their values.
I use raspberry pi’s as the nodes in the system, but it is currently written to work with NodeJS so it runs on almost anything that has NodeJS 4+, I even ran it on my android phone using Termux. Once it functions how i want, I will swap the JS code over to GO for speed and so that I can strip out almost all of the other programs and get as close to a single program on a kernel as I can get.
I’ve put most of my latest work into the token-update branch of each.
mostly finished with the 1000 conversion/update, but still need full reaudit basically lol.
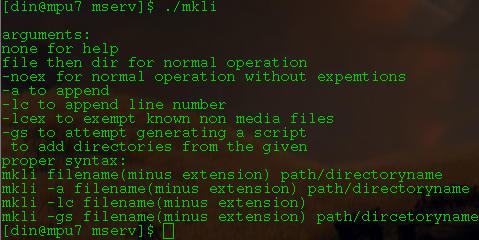
minor change to mkli changed -nex to -noex(for clarification as it was very similar to lcex, which is -lc and does the exemption)
otherwise all the new file name resolution stuff is in there.
whether its below 1000, or over 1000(meaning the actual data other than the file containing the number of segments would be in a sub dir, split into multiple files), or just in the one file for smaller(less than 1000)
if its _dat or not(_dat is appended to the end of the name for lists created by the user using the mcli program, where the generated lists from mkli are just name.txt)
if its in /db or not
the indexing is done through the name resolution the name/0.txt file is 0-999 segments, then 1000, is 1000-1999 and so on, as a way of indexing the data by lines, without knowing the exact length of each line, or ensuring each line length by padding the file(which would use up more space once you start getting into limit of line is over 1000 characters, with an average of well below 500 in most instances, versus just extra blocks ‘taken up’ because new files)
for creating lists, or playing, or generating from mkli, it uses the 1000 ‘convention’
added a ‘move’ command in the mcli console mode, for moving sublists to a designated spot
changed the formatting for the table mcli console prints for the list when it scans it, to include numbers, and the total in the footer
added a sorta redundant error handling check, where it will check if the list you are trying to openi n the mcli console, could be running(if mserv.txt is not set as not running, or low power/wait state, and the list that its playing is the one you entered), where it did check when it would open the file if it could open it for writing at the time of opening
taking a break currently but probably next is to add move to the help text for the console part, and add support for using the 3 commands to set position, for a given list name as well, as the current where it applies to the current playing list
I was getting sick of doing it manually so I wrote a shell script to automate the creation of bootable Windows USBs. It takes a single argument for the ISO image and the UI directs the user to select a device to create the bootable drive:
Sure, I just like collaborating with friends. But always be sure to have backups just in case! I do scheduled automatic backups of my server as well though.
Edit: Currently updating GitLab instance so if you are using atm and get a timeout don’t freak.
Edit2: Update complete.
I’ve been having a gander at this lately. The project is aimed at piping D3D9 through vulkan and being usable on any platform. Currently it works well on windows and linux and is only in the preliminary stages, but there also aren’t very many people working on it either. Mostly its just the original guy, but I want to help when I have time to throw at it.
On a serious note, I’ve just had a look at the repo and the main barrier to assistance I see is that there’s no issue tracking, so I don’t really know what needs to be done. This is something that everyone should be taught in school. How to maintain a development flow. It’s valuable for so many more things than just programming.