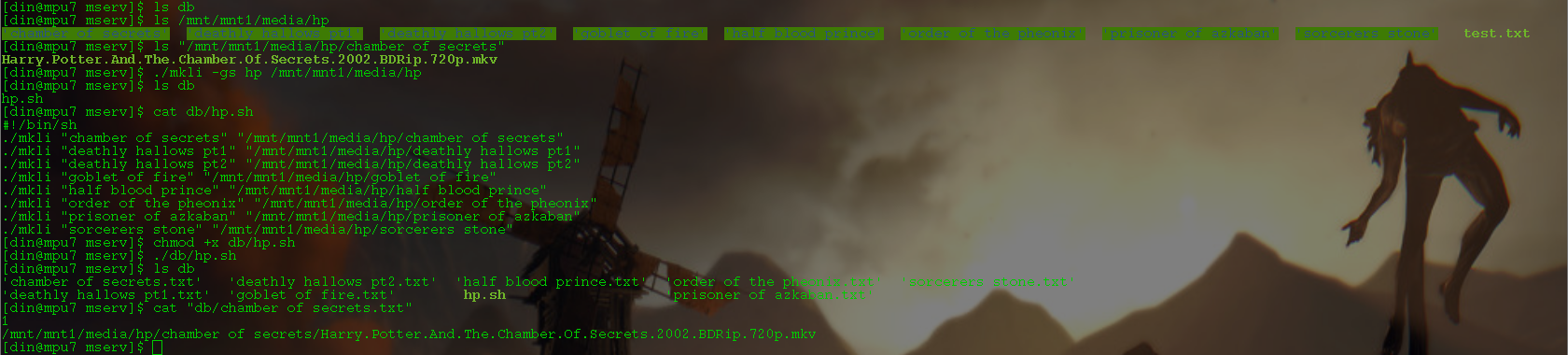
probs add in that it chmod automatically for the script eventually, but not sure for running it auto, as.. the point of doing it this way is if you have directories named stupidly/in a way that will make it more annoying to use that as the name, as it had been extrapolated.
example.. an apostrophe, in bash you have to do \' not just ' as it treats it as a single quote and proceeds to give warning messages, names without spaces would make it you dont have to use double quotes, if you had downloaded the file it might have the name of the person who ripped it, or if its 1080p, or if its 264/265 etc. so leaving it as the file lets you change the name before you run the script
ramblings mostly
oh yeah.. i said sortof recursively. cause it only does the directory you typed in. but having it scan the last 5 characters for a period currently, to then exempt those files from being included as directories will not have an extension, but gonna think on that for a bit and do that later :p.
as would like it to exempt files as we are looking for directories, but some directories may be named like .2008, as some programs/settings, result in files being output with periods instead of spaces, but doesnt seem too common, but would still like to exempt say .flac or .tiff etc
Utility company wants an app for all their employees' phones to log fuel purchases on the job. It also needs to have the potential for expanded functionality in the future. They were pretty vague on what that functionality would need to be.
Our web developer left the company over a year ago and they haven't seen fit to replace him, so it fell to me to build all parts of the project. I built this as a Web API running on one of their Windows Server VMs to handle the data, with SQL Server backing. This was the first time I had to implement OAuth on the web service side of things, so that was a fun rabbit hole to fall down. I did a lot of research/training and built some test projects to make sure I understood what I was doing. A lot of the material out there assumes you know a lot more about general web development than I did going into this, but despite the frustration I learned a hell of a lot on this project. I even re-purposed a machine I built to run pfsense as a web server, bought a domain, and set up dynamic DNS, so I now have a serviceable test environment.
The iOS and Android apps were pretty straightforward, since this is my normal specialization. Consume the Wep API with a bog standard REST client, store the OAuth token in a sane and secure manner (Object->Json->Crypto->file i/o).
Everything is working as intended. I'm lucky to have a job that lets me take as much time as needed to learn a new skill. Maybe I'll use what I've picked up here to finally set up some DIY home automation and sensors.
Built a WebGUI using Bootstrap, JQuery, JS, and HTML, which is for our network admin to help format Nagios entries. I'll probably mod it so it's more useful for me, too. It really make formatting entries easy.
I'm lazy, but never too lazy to help someone else be lazy.
added the chmod for the script, and put back the console output so you can see progress or whatever if you were to add like.. 10k files at once or something.
although not really that beneficial otherwise as mkli has lots of error handling stuff so most errors would have printed output already, and its pretty fast cause its just reading a text file that has one line per file full path, and scanning the lines in, checking for exempt extensions and then writing to a different file, that unless you're adding thousands of media files, or have something much slower than say my old piledrive a10-4655m laptop, will be a fraction of a second. like this example list would be like.. the amount of time to start vi or something like that
Im making a database for my college computer club for guides and tutorials on all kinds of computer science topics and some functionality that will allow club members to make written guides and tutorials on topics they want to present on. its essentially a database with a pretty skin wrapped around it.
Below is lukeFileWalker.rb. It traverses a file system looking for duplicate and blank files. It then reports each in separate files.
I'd appreciate any appraisal of my code. I'd like to get better at Ruby and Object Oriented programming - so any tips or advice would be appreciated.
#!/usr/bin/ruby
########################################################################################################################################
# #
# *** LUKE FILEWALKER *** #
# #
# #
# This program recursively scans a file system, starting with the directory it is called from, and reports blank and duplicate files #
# #
########################################################################################################################################
#Needed to generate MD5 value
require 'digest'
#Class for anything that is discovered to be a file
class FileName
def initialize(filename)
@fileName = filename
setMD5()
end
attr_reader :fileName, :md5
def setMD5()
@md5 = Digest::MD5.file @fileName
end
def is_empty?
if @md5 === "d41d8cd98f00b204e9800998ecf8427e"
is_empty =true
else
is_empty = false
end
return is_empty
end
end
#Lambda needed for number of files scanned, which will be displayed to update user
def increase_by(i)
start = 0
lambda { start += i }
end
#Builds an array of FileName Objects (array of files), and prints to console how many files scanned
#iterates through each item in the cwd, determines if it's a file
#if it's a file push it to the an array of FileName objects
#and print every time it scans another 100 items
#or it's a directory, cd into dir and recursively call itself
def buildArray(localObjCache, increase)
localDirContents=[] #Array of all items in the cwd
localDirContents=Dir[Dir.pwd+"/*"] #Builds the array of items in cwd
localDirContents.each do |item|
if File.file?(item)
fileObj = FileName.new(item)
localObjCache.push(fileObj)
n = increase.call #printing every 100 files scanned
if n % 100 == 0
puts n
end
elsif File.directory?(item)
Dir.chdir(item)
buildArray(localObjCache, increase)
end
end
return localObjCache
end
#Compares each fileObj's md5sum against all
#But first, if it's empty write to push it to a blanks array
#However, if equal create a hash of the files and
def findDups(objArray, dupsHashArray, emptyFileArray)
objArray.each_with_index do |obj, idx1|
if obj.is_empty?
emptyFileArray.push(obj.fileName)
next
end
objArray.each_with_index do |obj2, idx2|
next if idx1 >= idx2
if obj.md5 === obj2.md5
foundDupHash= {:filePath => obj.fileName, :duplicatePath => obj2.fileName}
dupsHashArray.push(foundDupHash)
end
end
end
end
#Print all blanks to a file
def printEmpty(emptyFileArray)
puts "Writing blanks to: /tmp/blanks.txt"
File.open("/tmp/blanks.txt", "w") do |f|
emptyFileArray.each { |element| f.puts(element)}
end
end
#Write all dups to a file
def printDups(dupsHashArray)
puts "Writing duplicates to: /tmp/duplicates.txt"
File.open("/tmp/duplicates.txt","w") do |f|
dupsHashArray.each { |element| f.puts(element[:filePath] + " : " + element[:duplicatePath]) }
end
end
#Define main
def main()
localObjCache=[]
emptyFileArray = []
dupsHashArray = []
increase = increase_by(1)
objArray = buildArray(localObjCache, increase)
findDups(objArray, dupsHashArray, emptyFileArray)
printEmpty(emptyFileArray)
printDups(dupsHashArray)
end
#Let's run this show
main()
@Dynamic_Gravity I could be totally wrong here, but here is what I was thinking.
Recursion is an expensive operation, plus each recursve call is getting pushed onto a stack. So it's a slow and heavy process running, plus is building a massive array of objects. Which, is probably not going to help the "heaviness" of the process. I figured to try to save, mostly time (figuring generating md5 sum should save time compare to SHA1), and maybe saving a little heap.
This thing gets into the millions of files - I ran it on a Ubuntu 16.04 from / and the stack limit got hit around 1 million files scanned.
With that said, maybe in the grand scheme of things generating a SHA1 for each obj would be negligible. That I don't know.
Not coding per-sey, but I'm trying to setup jenkins with docker swarm mode but I'm having issues trying to spin up guests to run the jenkins build devices on. Also @cotton are you from Oklahoma?
disclaimer: I do not want to sound like a dick but I want you to understand what you said was wrong and why.
heap is non-contiguous memory, a stack is contiguous.
Recursive operations are pushed on a stack.
Heap allocation and stack allocation are not synonymous with each other, they are separate.
MD5 are easily exploitable, so if you are relying on MD5 hashes of files if someone has crafted files to look like other files (easily done with MD5 hashing since its so broken), then your program may have a problem.
Lastly, if the size of your collection of objects is large then you should use a lookup table instead of just sticking it into an array.
again, this is a process of allocating memory, little heap and large heap doesn't make sense technically.
Im a bit late to the party, but I made a site a while ago.
Its like PasteBin, but for file sharing.
The use case was something like "I need to share this file with 30 classmates real quick, but don't have time to sign into Dropbox or exchange emails" or something like that. Its just a site to "Hold This" for a few days.
Its really nothing special, but the code is public.
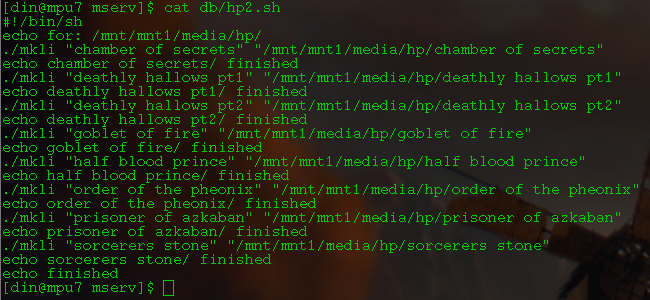
added the '_olist.txt' file, where it compares the new output from the ls to generate the list agains, so it can add new entries to the end of the list without modifying the list, as to save any changes made by the user to change names or whatever, ex: 'Dr. Strangelove or How I Learned to Stop Worrying and Love the Bomb' to 'strangelove' as the probability of having another file of that name seems not that likely, and should still be easy to remember what the content is, but is still significantly shorter to be more convenient
so you can extended the script without losing such changes, and i added an option for '-q' where it will skip files instead of overwriting which the script uses, so it will speed up the operations if you add to the script to just be able to run it again by skipping immediately upon it checking for existence of the sublist file
and as it also compared the new ls output to the olist file, it just adds the new entries, so its possible to use it to add entirely separate entries such that you could build say a 'upgrade/update' script where it could add all of your media directories, to the effect that if you had changes to a directory, or multiple you could update them at once by removing the original sublists and running the script, but thats not really that beneficial as to overwrite the old sublist would just require the single command to run it manually. but is a nice extra i guess for just allowing the ability to update the script without losing previous changes
did a nearly full deployment of it(to do more testing lol)
ended up finding funny bug
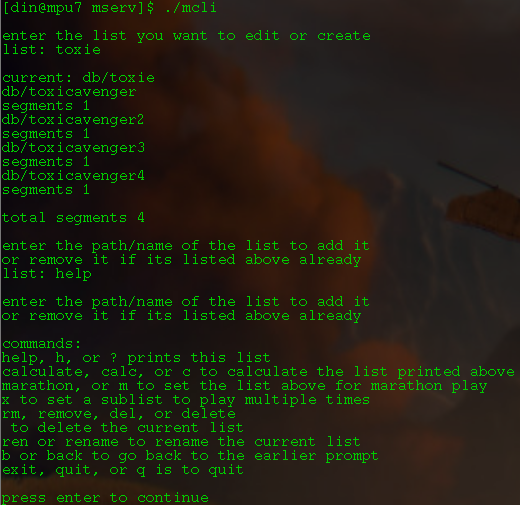
but added couple new options to the console for mcli, delete and rename functions for the current working list, and a back option to drop back to the prompt to select a list,(it already dropped back if you hit calculate or marathon, and if you exit it just closes the whole program, so figured back might be useful if they were just checking configuration but didnt actually make any change)
added to mserv, that it will delete the pos file after playing if the list only has a single segment(save some space/clean up since it would only ever store a one anyways,
edit:
added options for -a for the -n, or -sp commands for mcli,
like.. ./mcli -sp toxie 4 -aro would play 4th segment of the toxie list, after the current play finishes and then resume play(which would be pointless as the file will have finished at that point but its there lol) if did just -a it wouldnt do the normal -ro option, but without the a it will kill vlc, as to immediately start the what you just scheduled instead of leaving it queued to start after