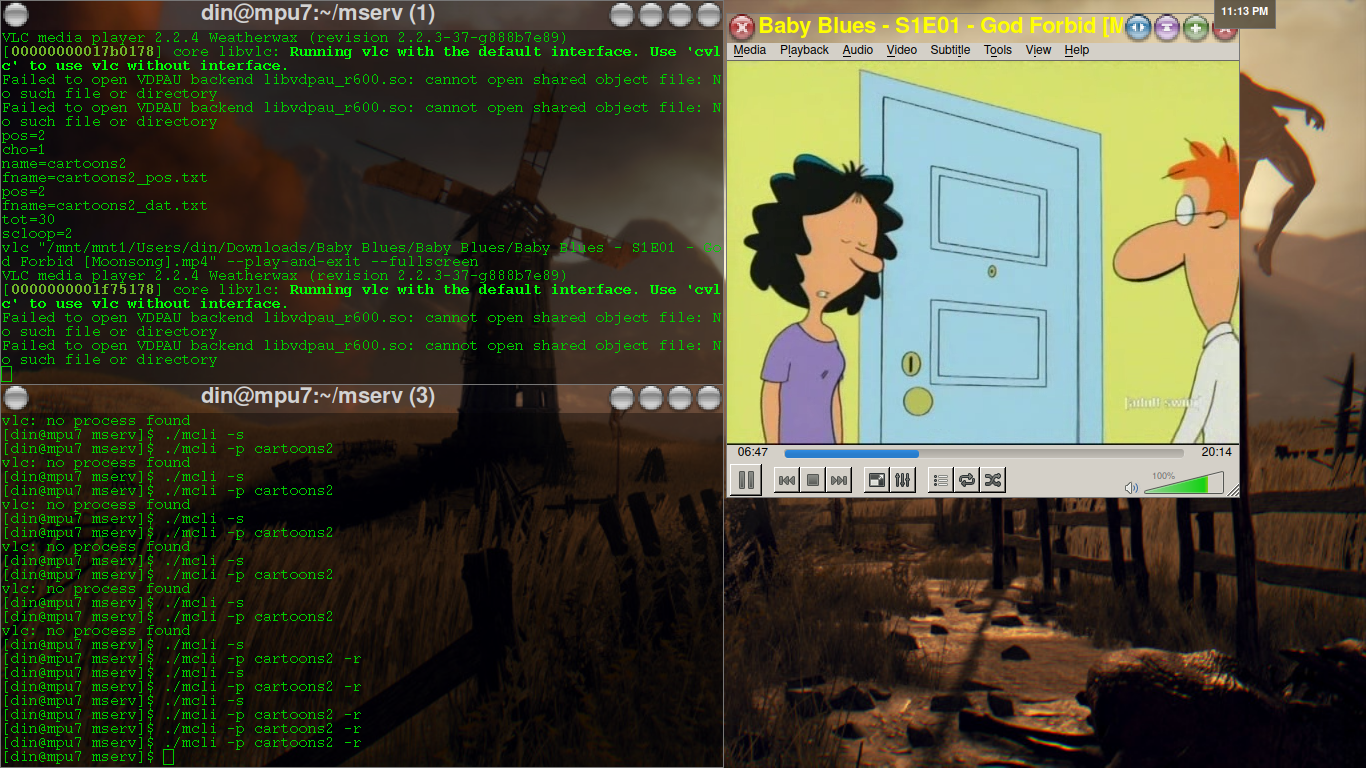
did a bit more work on mserv(well mostly the cli component but a but with mserv also and the mkli)
added option for 'numbered play' where you could interrupt previous instructions to play a specified number of segments and then return to whatever it was doing before(playing or just the low power/wait state).
a multiplier option,
math stuffs kinda
a bit of refining to the math for the distribution of calculated lists(had forgotten have to bootstrap the thing, since it just decides when to put a segment from a sublist by doing division, of the total number of segments, the amount of segments in the list, against how many segments have been played/picked so far in the list.
to the effect that if you have a list of 5 24 segment sublists, you have a total of 120, but the divison will tell it to play an episode of each 1 every 5 segments, so by forcing the first time it comes up, then it will be time to play the second episode as 5 will have already gone, then by the time all 5 have gone again will be 10 and so on. otherwise if none had been picked it would exit the loop(as it only runs once for the outter most section per segment, never having updated the counter for amount of picked so it would just fail every time, but with the boot strap it just screws up the distribution a little bit at the start/end but the spread hasnt been too bad in my testing,(worst saw was like 15%, but average seems like 5~10% spread between when first sublist ends and the last segment in the list)
messed with the multiplier option made some lists between 2500-27000, that even if its just one list is crazy long and the other sublists or short etc, (like one being 25,700 and shortest being 13) was still around 9% spread
some performance tuning/optimization of the multiplication mode so it just shifts the number of segments once it goes past the original number instead of trying to scan 47lines in a 24line file and just rewinding until it finishes, so that it would just minus 24 if it was over 24(in that example) until it was below 24
which speeds it up alot when you get into scanning the same file to do like 100 plays of that sublist, when you get into the 100th play, it would have been scanning 100 times, it still has a similar slow down in that the more times you play it the more work it has to do shifting the number down but its substantially faster and not doing stuff with disk speed(if it doesn get cached into system memory)
so pretty okay with that so far
an example file working on readme/documentation stuff currently
>./mcli
enter the list you want to edit or create
list: >cartoons2
current: db/cartoons2
total segments 0
enter the path/name of the list to add it
or remove it if its listed above already
list: >ed edd n eddy
current: db/cartoons2
db/ed edd n eddy
segments 70
total segments 70
enter the path/name of the list to add it
or remove it if its listed above already
list: >babyblues
current: db/cartoons2
db/ed edd n eddy
segments 70
db/babyblues
segments 13
total segments 83
enter the path/name of the list to add it
or remove it if its listed above already
list: >commercial
current: db/cartoons2
db/ed edd n eddy
segments 70
db/babyblues
segments 13
db/commercial
segments 17
total segments 100
enter the path/name of the list to add it
or remove it if its listed above already
list: >x
enter the list name to apply or remove a multiplier
list: >baby blues
enter the multiplier: >5
current: db/cartoons2
db/ed edd n eddy
segments 70
db/babyblues
segments 13 x5
db/commercial
segments 17
total segments 152
enter the path/name of the list to add it
or remove it if its listed above already
list: >x
enter the list name to apply or remove a multiplier
list: >commercial
enter the multiplier: >4
current: db/cartoons2
db/ed edd n eddy
segments 70
db/babyblues
segments 13 x5
db/commercial
segments 17 x4
total segments 203
enter the path/name of the list to add it
or remove it if its listed above already
list: >c
this may take a few moments
enter the list you want to edit or create
list: >exit
the text following > was user input, i just piped the output of the program to a file so had to backfill the input.
probably add so it outputs the total number instead of just the original number/multiplier(bit easier for some i guess/when you get into longer lists with many more sublists doing the math might become more tedious.
the mentioned readme lol
no arguments to run the cli/console to calculate lists
commands:
-h, --h, -help, --help or ?, to print this list
-p, --p, -play, or --play, to play the list named after
-r, --r, -resume, or --resume, after the listname
to resume play at the begining of the file
instead of starting the next
-n, --n, -numberedplay, or --numberedplay to play given number of segments
-rn, --rn, -resumen, or --resumen
to begin at start of file on the numbered play
-ro, --ro, -resumeo, or --resumeo
to begin at start of file of the original list
-rb, --rb, -resumeb, or --resumeb
to begin at start of file for both plays
-start, or --start, to resume playing
-r, --r, -resume, or --resume
to begin at start of file
-stop, or --stop, to stop playing
-setpos, or --setpos, to set the position of what's to be played
-setpos-, ot --setpos-, to subtract the entered number
-setpos+, or --setpos+, to add the entered number
-shutdown, --shutdown, -halt, or --halt,
to shutdown mserv
for mkli:
proper syntax:
mkli filename(minus extension) path/directoryname
mkli is to make a list from a directory in the proper format.
but if the directory is not entirelly made up of the media files you
want to play, or the files arent named in a way to maintain specific order
(if desired)
then you will need to open that file and edit it, to remove the lines
for the files you dont want to play or to ensure the order is as desired.
then you will need to change the number on the first line to reflect any
changes made(if you removed files)
otherwise you start mserv, and then use mcli to issue commands or make
the lists of sublists.
the format is such, that you can play the sublists directly aswell using
the exact same method as to play the calculated lists.
if you modify a sublist, or calculated list you will need to recalculate
every list that list is present in; to update them to reflect those
changes.
the first parts being the output from doing -h or whatever, and then shittily explaining some stuff below havent finished it yet but think the formtting for the help output is mostly done..
oh yeah..
modified mkli, so theres an option to pipe the ls output to the end of the file, then a command to scan the file(to add the line number)
so you could fire multiple directories into a single file edit out anything you dont need, and then have it make the line number for you