My bread board 28c16 reader/writer: https://i.imgur.com/njBvCbr.jpg, which can read and write using only 6 gpio pins. It’s true the raspberry pi 3 has 28 programmable gpio pins; so you could just hook up all the pins directly to the pi. But that’s not much fun.
The 28c16 is an eeprom with 2048 bytes of storage. So it has 11 address lines and 8 I/O lines. With the 3 8-bit shift registers, I can shift in all 11 address bits and 8 I/O bits using only 1 data pin, 1 pin for the shift clock, 1 pin for the register clock, and 1 pin to toggle a write. I used a dedicated pi pin for the write enable and output enable pins on the eeprom, but the data out/data in could be combined, and the output enable could be shifted in since there are 5 bits left over on the shift registers.
Reading is 8 times slower than writing. While the writer can write 8 bits at a time, the reader can only read 1 bit a time.
I wrote a simple c program (using the wiring pi library to handle reads and writes:
eeprom (-r [low] [high] | -w (value) [low] [high])
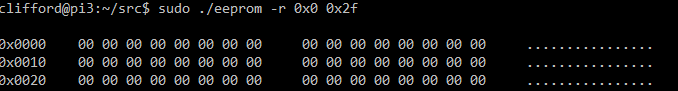
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
#include <string.h>
#include <wiringPi.h>
#include <wiringShift.h>
#define PIN_DATA 4
#define PIN_SHIFT_CL 16
#define PIN_REG_CL 15
#define PIN_OUT_EN 5
#define PIN_WR_EN 1
#define PIN_DATA_IN 6
typedef enum tagMODE { READ = 1,
WRITE = 2 } MODE;
void pulsePin(int pin, int delay) {
//delay is microseconds
int state = digitalRead(pin);
digitalWrite(pin, !state);
delayMicroseconds(delay);
digitalWrite(pin, state);
}
void shiftByte(unsigned char data) {
shiftOut(PIN_DATA, PIN_SHIFT_CL, LSBFIRST, data);
pulsePin(PIN_REG_CL, 101);
digitalWrite(PIN_DATA, LOW);
}
void programByte(unsigned short address, unsigned char data) {
unsigned char lower = (unsigned char) address;
unsigned char upper = (unsigned char) (address >> 8);
shiftByte(lower);
shiftByte(upper);
shiftByte(data);
pulsePin(PIN_WR_EN, 101);
}
unsigned char readByte(unsigned short address) {
unsigned char data = 0x00;
unsigned char lower = (unsigned char) address;
unsigned char upper = (unsigned char) (address >> 8);
for( int i = 0; i < 8; ++i ) {
unsigned char bit;
unsigned char mask = 0x1 << i;
shiftByte(lower);
shiftByte(upper);
shiftByte(mask);
bit = digitalRead(PIN_DATA_IN);
data = data | (bit << i);
}
return data;
}
void read(unsigned short low, unsigned short high) {
unsigned char data;
unsigned char buffer[17] = {0};
unsigned short length = high - low;
for( unsigned short i = 0; i <= length; ++i ) {
data = readByte((unsigned short) i);
buffer[i % 16] = data;
if( i % 16 == 0 )
printf("\n0x%.4x", low + i);
if( i % 8 == 0 )
printf(" ");
printf("%.2x ", data);
if( (i+1) % 16 == 0 ) {
printf(" ");
for( int j = 0; j < 16; ++j ) {
if( ( buffer[j] >= 'a' && buffer[j] <= 'z' ) || ( buffer[j] >= 'A' && buffer[j] <= 'Z' ) ||
( buffer[j] >= 0x20 && buffer[j] <= 0x64) || ( buffer[j] >= 0x7b && buffer[j] <= 0x7e ) )
printf("%c", buffer[j]);
else
printf(".");
}
}
}
printf("\n");
digitalWrite(PIN_OUT_EN, HIGH);
shiftByte(0x00);
}
void write(unsigned char data, unsigned short low, unsigned short high) {
unsigned short length = high - low;
for( unsigned short i = 0; i <= length; ++i ) {
programByte(low + i, data);
}
digitalWrite(PIN_OUT_EN, LOW);
}
int main(int argc, char * argv[]) {
unsigned char data;
MODE mode;
char * szMode;
unsigned short low, high;
if( argc < 2 )
return 0;
szMode = argv[1];
if( strcmp(szMode, "-r") == 0 ) {
mode = READ;
} else if ( strcmp(szMode, "-w") == 0 ) {
mode = WRITE;
}
wiringPiSetup();
pinMode(PIN_DATA, OUTPUT);
pinMode(PIN_SHIFT_CL, OUTPUT);
pinMode(PIN_REG_CL, OUTPUT);
pinMode(PIN_OUT_EN, OUTPUT);
pinMode(PIN_WR_EN, OUTPUT);
pinMode(PIN_DATA_IN, INPUT);
digitalWrite(PIN_DATA, LOW);
digitalWrite(PIN_SHIFT_CL, LOW);
digitalWrite(PIN_REG_CL, LOW);
digitalWrite(PIN_WR_EN, HIGH);
switch ( mode) {
case READ:
digitalWrite(PIN_OUT_EN, LOW);
if( argc < 3 ) {
low = 0x00;
high = 0x7ff;
} else {
low = (unsigned short) strtol(argv[2], NULL, 16);
if( argc > 3 )
high = (unsigned short) strtol(argv[3], NULL, 16);
else
high = 0x7ff;
}
read(low, high);
break;
case WRITE:
digitalWrite(PIN_OUT_EN, HIGH);
if ( argc < 3 ) {
data = 0xff;
low = 0x00;
high = 0x7ff;
} else {
data = (unsigned char) strtol(argv[2], NULL, 16);
if( argc >= 5 ) {
low = (unsigned short) strtol(argv[3], NULL, 16);
high = (unsigned short) strtol(argv[4], NULL, 16);
} else if (argc == 4) {
low = (unsigned short) strtol(argv[3], NULL, 16);
high = 0x7ff;
} else {
low = 0x00;
high = 0x7ff;
}
}
write(data, low, high);
break;
}
return 0;
}



{kind=link}