Could you please try to run Cinebench on your Windows VM. This is a benchmark that renders a scene using the CPU. It subdivides the scene into small squares where at a given time each VCPU renders one square. There you could visually see how many VCPUs are active and utilizable on your VM.
Thank you for replying.
Ok I will change it when I am at home.
So dies refer to CCD ?
Exactly. You can generally use it without specifying the dies= option but then Windows won’t be able to correctly recognize the L3 cache! If Windows has a correct mapping of your L3-Cache you can check in the Windows VM by using the Coreinfo tool.
1 Like
Yeah I will try it tonight before changing cputune. I am at work
It is an interesting test were you lock a VM to a CCX for cache pooling VS the modern kernels scheduler using all the CCX’s and all cache via its codebase. There are a few schedulers.
No on 3000 series Ryzen it refers to the CCX not the CCD. The L3 cache is per CCX not per CCD.
1 Like
If it refers to ccx, 3900x has 4 ccx so 4 dies, right ?.
If I want to pass through 18 vcpu, It must look like this :
[..]
<vcpu placement="static">18</vcpu>
[..]
<cpu mode="host-passthrough" check="none" migratable="on">
<topology sockets="1" dies="3" cores="3" threads="2"/>
<feature policy="require" name="topoext"/>
</cpu>
[..]Should be correct. I am not entirely sure since I have no way of testing it currently. Please just try to start the VM with this setting and see the output of Coreinfo. It shows how the Cache is assigned to the VCPUS in pairs of two, meaning each core plus its hyperthread. Then if the L3 cache is assigned to all VCPUs it is not correctly assigned. In your case there should be 3 instances of L3 each assingned to 6 VCPUs.
Edit: It needs to be:
<cpu mode="host-passthrough" check="none" migratable="on">
<topology sockets="1" dies="3" cores="3" threads="2"/>
<cache mode="passthrough"/>
<feature policy="require" name="topoext"/>
</cpu>
1 Like
This got me thinking…
If I execute
sudo virsh capabilities | xmllint --xpath "//topology|//cache" -I get the following:
<topology sockets="1" dies="1" cores="16" threads="2"/>
<topology>
<cells num="1">
<cell id="0">
<memory unit="KiB">32782280</memory>
<pages unit="KiB" size="4">8130034</pages>
<pages unit="KiB" size="2048">128</pages>
<pages unit="KiB" size="1048576">0</pages>
<distances>
<sibling id="0" value="10"/>
</distances>
<cpus num="32">
<cpu id="0" socket_id="0" die_id="0" core_id="0" siblings="0,16"/>
<cpu id="1" socket_id="0" die_id="0" core_id="1" siblings="1,17"/>
<cpu id="2" socket_id="0" die_id="0" core_id="2" siblings="2,18"/>
<cpu id="3" socket_id="0" die_id="0" core_id="3" siblings="3,19"/>
<cpu id="4" socket_id="0" die_id="0" core_id="4" siblings="4,20"/>
<cpu id="5" socket_id="0" die_id="0" core_id="5" siblings="5,21"/>
<cpu id="6" socket_id="0" die_id="0" core_id="6" siblings="6,22"/>
<cpu id="7" socket_id="0" die_id="0" core_id="7" siblings="7,23"/>
<cpu id="8" socket_id="0" die_id="0" core_id="8" siblings="8,24"/>
<cpu id="9" socket_id="0" die_id="0" core_id="9" siblings="9,25"/>
<cpu id="10" socket_id="0" die_id="0" core_id="10" siblings="10,26"/>
<cpu id="11" socket_id="0" die_id="0" core_id="11" siblings="11,27"/>
<cpu id="12" socket_id="0" die_id="0" core_id="12" siblings="12,28"/>
<cpu id="13" socket_id="0" die_id="0" core_id="13" siblings="13,29"/>
<cpu id="14" socket_id="0" die_id="0" core_id="14" siblings="14,30"/>
<cpu id="15" socket_id="0" die_id="0" core_id="15" siblings="15,31"/>
<cpu id="16" socket_id="0" die_id="0" core_id="0" siblings="0,16"/>
<cpu id="17" socket_id="0" die_id="0" core_id="1" siblings="1,17"/>
<cpu id="18" socket_id="0" die_id="0" core_id="2" siblings="2,18"/>
<cpu id="19" socket_id="0" die_id="0" core_id="3" siblings="3,19"/>
<cpu id="20" socket_id="0" die_id="0" core_id="4" siblings="4,20"/>
<cpu id="21" socket_id="0" die_id="0" core_id="5" siblings="5,21"/>
<cpu id="22" socket_id="0" die_id="0" core_id="6" siblings="6,22"/>
<cpu id="23" socket_id="0" die_id="0" core_id="7" siblings="7,23"/>
<cpu id="24" socket_id="0" die_id="0" core_id="8" siblings="8,24"/>
<cpu id="25" socket_id="0" die_id="0" core_id="9" siblings="9,25"/>
<cpu id="26" socket_id="0" die_id="0" core_id="10" siblings="10,26"/>
<cpu id="27" socket_id="0" die_id="0" core_id="11" siblings="11,27"/>
<cpu id="28" socket_id="0" die_id="0" core_id="12" siblings="12,28"/>
<cpu id="29" socket_id="0" die_id="0" core_id="13" siblings="13,29"/>
<cpu id="30" socket_id="0" die_id="0" core_id="14" siblings="14,30"/>
<cpu id="31" socket_id="0" die_id="0" core_id="15" siblings="15,31"/>
</cpus>
</cell>
</cells>
</topology>
<cache>
<bank id="0" level="3" type="both" size="16" unit="MiB" cpus="0-3,16-19"/>
<bank id="1" level="3" type="both" size="16" unit="MiB" cpus="4-7,20-23"/>
<bank id="2" level="3" type="both" size="16" unit="MiB" cpus="8-11,24-27"/>
<bank id="3" level="3" type="both" size="16" unit="MiB" cpus="12-15,28-31"/>
</cache>So I was wrong according to the above - libvirt detects one socket and one die on AMD Rysen 9 3950X (It’s similar for 3900X)
2 Likes
But as far as I understand it this setting I am recommending is important not to the host but to the guest. So basically for Windows to know that it is not one coherent cache in total but one L3 cache per CCX you need to specify the dies= option still. It is not a requirement for the VM to work, but for Windows to be able to effectively manage the L3 on its own it needs to know about the L3 topology. From my experience the only way for Windows to see the correct layout is the dies= option in combination with the cache mode=. This is why I recommended the Coreinfo tool, since it basically shows how Windows sees the cache topology.
It also detects 4 banks of L3 cache. If you know of another way to let the guest see the L3 cache I would be interested but from what I know until now the dies= options does this.
3 Likes
OK that makes sense - the dies setting entirely depends on how many and which CPUs you will assign to the VM so that they know how to handle the cache 
I tried testing this on my VM and my 3950X. I pinned the cores to the VM bundled them per L3 cache memory assigning essentially bank ‘1’ and ‘3’ to the VM (or at least I think I did  )
)
(Only showing relevant bigs of the XML)
<domain>
[..]
<vcpu placement="static">16</vcpu>
<iothreads>1</iothreads>
<cputune>
<vcpupin vcpu="0" cpuset="4"/>
<vcpupin vcpu="1" cpuset="20"/>
<vcpupin vcpu="2" cpuset="5"/>
<vcpupin vcpu="3" cpuset="21"/>
<vcpupin vcpu="4" cpuset="6"/>
<vcpupin vcpu="5" cpuset="22"/>
<vcpupin vcpu="6" cpuset="7"/>
<vcpupin vcpu="7" cpuset="23"/>
<vcpupin vcpu="8" cpuset="12"/>
<vcpupin vcpu="9" cpuset="28"/>
<vcpupin vcpu="10" cpuset="13"/>
<vcpupin vcpu="11" cpuset="29"/>
<vcpupin vcpu="12" cpuset="14"/>
<vcpupin vcpu="13" cpuset="30"/>
<vcpupin vcpu="14" cpuset="15"/>
<vcpupin vcpu="15" cpuset="31"/>
<emulatorpin cpuset="0-3,8-11,16-19,24-27"/>
<iothreadpin iothread="1" cpuset="0-3,8-11,16-19,24-27"/>
</cputune>
<cpu mode="host-passthrough" check="none" migratable="on">
<topology sockets="1" dies="4" cores="2" threads="2"/>
<cache mode="passthrough"/>
<feature policy="require" name="topoext"/>
</cpu>
[..]
<!-- Adding the disk to show the iothread=1 running directly on an SSD Crucial (SATA) -->
<disk type="block" device="disk">
<driver name="qemu" type="raw" cache="none" io="native" discard="unmap" iothread="1" queues="8"/>
<source dev="/dev/disk/by-id/wwn-0x500a0751e1e25459"/>
<target dev="vda" bus="virtio"/>
<address type="pci" domain="0x0000" bus="0x04" slot="0x00" function="0x0"/>
</disk>
</domain>So inside the windows 10 VM running coreinfo results in:
AMD Ryzen 9 3950X 16-Core Processor
AMD64 Family 23 Model 113 Stepping 0, AuthenticAMD
Microcode signature: 00000000
HTT * Multicore
HYPERVISOR * Hypervisor is present
VMX - Supports Intel hardware-assisted virtualization
SVM * Supports AMD hardware-assisted virtualization
X64 * Supports 64-bit mode
SMX - Supports Intel trusted execution
SKINIT - Supports AMD SKINIT
NX * Supports no-execute page protection
SMEP * Supports Supervisor Mode Execution Prevention
SMAP * Supports Supervisor Mode Access Prevention
PAGE1GB * Supports 1 GB large pages
PAE * Supports > 32-bit physical addresses
PAT * Supports Page Attribute Table
PSE * Supports 4 MB pages
PSE36 * Supports > 32-bit address 4 MB pages
PGE * Supports global bit in page tables
SS - Supports bus snooping for cache operations
VME * Supports Virtual-8086 mode
RDWRFSGSBASE * Supports direct GS/FS base access
FPU * Implements i387 floating point instructions
MMX * Supports MMX instruction set
MMXEXT * Implements AMD MMX extensions
3DNOW - Supports 3DNow! instructions
3DNOWEXT - Supports 3DNow! extension instructions
SSE * Supports Streaming SIMD Extensions
SSE2 * Supports Streaming SIMD Extensions 2
SSE3 * Supports Streaming SIMD Extensions 3
SSSE3 * Supports Supplemental SIMD Extensions 3
SSE4a * Supports Streaming SIMDR Extensions 4a
SSE4.1 * Supports Streaming SIMD Extensions 4.1
SSE4.2 * Supports Streaming SIMD Extensions 4.2
AES * Supports AES extensions
AVX * Supports AVX instruction extensions
FMA * Supports FMA extensions using YMM state
MSR * Implements RDMSR/WRMSR instructions
MTRR * Supports Memory Type Range Registers
XSAVE * Supports XSAVE/XRSTOR instructions
OSXSAVE * Supports XSETBV/XGETBV instructions
RDRAND * Supports RDRAND instruction
RDSEED * Supports RDSEED instruction
CMOV * Supports CMOVcc instruction
CLFSH * Supports CLFLUSH instruction
CX8 * Supports compare and exchange 8-byte instructions
CX16 * Supports CMPXCHG16B instruction
BMI1 * Supports bit manipulation extensions 1
BMI2 * Supports bit manipulation extensions 2
ADX * Supports ADCX/ADOX instructions
DCA - Supports prefetch from memory-mapped device
F16C * Supports half-precision instruction
FXSR * Supports FXSAVE/FXSTOR instructions
FFXSR * Supports optimized FXSAVE/FSRSTOR instruction
MONITOR - Supports MONITOR and MWAIT instructions
MOVBE * Supports MOVBE instruction
ERMSB - Supports Enhanced REP MOVSB/STOSB
PCLMULDQ * Supports PCLMULDQ instruction
POPCNT * Supports POPCNT instruction
LZCNT * Supports LZCNT instruction
SEP * Supports fast system call instructions
LAHF-SAHF * Supports LAHF/SAHF instructions in 64-bit mode
HLE - Supports Hardware Lock Elision instructions
RTM - Supports Restricted Transactional Memory instructions
DE * Supports I/O breakpoints including CR4.DE
DTES64 - Can write history of 64-bit branch addresses
DS - Implements memory-resident debug buffer
DS-CPL - Supports Debug Store feature with CPL
PCID - Supports PCIDs and settable CR4.PCIDE
INVPCID - Supports INVPCID instruction
PDCM - Supports Performance Capabilities MSR
RDTSCP * Supports RDTSCP instruction
TSC * Supports RDTSC instruction
TSC-DEADLINE * Local APIC supports one-shot deadline timer
TSC-INVARIANT - TSC runs at constant rate
xTPR - Supports disabling task priority messages
EIST - Supports Enhanced Intel Speedstep
ACPI - Implements MSR for power management
TM - Implements thermal monitor circuitry
TM2 - Implements Thermal Monitor 2 control
APIC * Implements software-accessible local APIC
x2APIC * Supports x2APIC
CNXT-ID - L1 data cache mode adaptive or BIOS
MCE * Supports Machine Check, INT18 and CR4.MCE
MCA * Implements Machine Check Architecture
PBE - Supports use of FERR#/PBE# pin
PSN - Implements 96-bit processor serial number
PREFETCHW * Supports PREFETCHW instruction
Maximum implemented CPUID leaves: 0000001F (Basic), 8000001F (Extended).
Maximum implemented address width: 48 bits (virtual), 40 bits (physical).
Processor signature: 00870F10
Logical to Physical Processor Map:
**-------------- Physical Processor 0 (Hyperthreaded)
--**------------ Physical Processor 1 (Hyperthreaded)
----**---------- Physical Processor 2 (Hyperthreaded)
------**-------- Physical Processor 3 (Hyperthreaded)
--------**------ Physical Processor 4 (Hyperthreaded)
----------**---- Physical Processor 5 (Hyperthreaded)
------------**-- Physical Processor 6 (Hyperthreaded)
--------------** Physical Processor 7 (Hyperthreaded)
Logical Processor to Socket Map:
**************** Socket 0
Logical Processor to NUMA Node Map:
**************** NUMA Node 0
No NUMA nodes.
Logical Processor to Cache Map:
**-------------- Data Cache 0, Level 1, 32 KB, Assoc 8, LineSize 64
**-------------- Instruction Cache 0, Level 1, 32 KB, Assoc 8, LineSize 64
**-------------- Unified Cache 0, Level 2, 512 KB, Assoc 8, LineSize 64
********-------- Unified Cache 1, Level 3, 16 MB, Assoc 16, LineSize 64
--**------------ Data Cache 1, Level 1, 32 KB, Assoc 8, LineSize 64
--**------------ Instruction Cache 1, Level 1, 32 KB, Assoc 8, LineSize 64
--**------------ Unified Cache 2, Level 2, 512 KB, Assoc 8, LineSize 64
----**---------- Data Cache 2, Level 1, 32 KB, Assoc 8, LineSize 64
----**---------- Instruction Cache 2, Level 1, 32 KB, Assoc 8, LineSize 64
----**---------- Unified Cache 3, Level 2, 512 KB, Assoc 8, LineSize 64
------**-------- Data Cache 3, Level 1, 32 KB, Assoc 8, LineSize 64
------**-------- Instruction Cache 3, Level 1, 32 KB, Assoc 8, LineSize 64
------**-------- Unified Cache 4, Level 2, 512 KB, Assoc 8, LineSize 64
--------**------ Data Cache 4, Level 1, 32 KB, Assoc 8, LineSize 64
--------**------ Instruction Cache 4, Level 1, 32 KB, Assoc 8, LineSize 64
--------**------ Unified Cache 5, Level 2, 512 KB, Assoc 8, LineSize 64
--------******** Unified Cache 6, Level 3, 16 MB, Assoc 16, LineSize 64
----------**---- Data Cache 5, Level 1, 32 KB, Assoc 8, LineSize 64
----------**---- Instruction Cache 5, Level 1, 32 KB, Assoc 8, LineSize 64
----------**---- Unified Cache 7, Level 2, 512 KB, Assoc 8, LineSize 64
------------**-- Data Cache 6, Level 1, 32 KB, Assoc 8, LineSize 64
------------**-- Instruction Cache 6, Level 1, 32 KB, Assoc 8, LineSize 64
------------**-- Unified Cache 8, Level 2, 512 KB, Assoc 8, LineSize 64
--------------** Data Cache 7, Level 1, 32 KB, Assoc 8, LineSize 64
--------------** Instruction Cache 7, Level 1, 32 KB, Assoc 8, LineSize 64
--------------** Unified Cache 9, Level 2, 512 KB, Assoc 8, LineSize 64
Logical Processor to Group Map:
**************** Group 0And the cpu-stats are like
cpu-stats
CPU0:
cpu_time 6.740163063 seconds
vcpu_time 0.000000000 seconds
CPU1:
cpu_time 8.246149058 seconds
vcpu_time 0.000000000 seconds
CPU2:
cpu_time 8.595681036 seconds
vcpu_time 0.000000000 seconds
CPU3:
cpu_time 8.054007756 seconds
vcpu_time 0.000000000 seconds
CPU4:
cpu_time 188.581467166 seconds
vcpu_time 188.581521759 seconds
CPU5:
cpu_time 77.434765652 seconds
vcpu_time 77.434817098 seconds
CPU6:
cpu_time 76.127551444 seconds
vcpu_time 76.127644497 seconds
CPU7:
cpu_time 56.719673873 seconds
vcpu_time 56.719761097 seconds
CPU8:
cpu_time 5.669370253 seconds
vcpu_time 0.000000000 seconds
CPU9:
cpu_time 7.131605927 seconds
vcpu_time 0.000000000 seconds
CPU10:
cpu_time 6.828465294 seconds
vcpu_time 0.000000000 seconds
CPU11:
cpu_time 6.739869749 seconds
vcpu_time 0.000000000 seconds
CPU12:
cpu_time 71.485769981 seconds
vcpu_time 71.485812962 seconds
CPU13:
cpu_time 57.768022065 seconds
vcpu_time 57.768049004 seconds
CPU14:
cpu_time 67.327900820 seconds
vcpu_time 67.328034270 seconds
CPU15:
cpu_time 84.009917745 seconds
vcpu_time 84.009952481 seconds
CPU16:
cpu_time 8.381416595 seconds
vcpu_time 0.000000000 seconds
CPU17:
cpu_time 7.864862961 seconds
vcpu_time 0.000000000 seconds
CPU18:
cpu_time 7.691901992 seconds
vcpu_time 0.000000000 seconds
CPU19:
cpu_time 6.764826545 seconds
vcpu_time 0.000000000 seconds
CPU20:
cpu_time 38.516764584 seconds
vcpu_time 38.516779703 seconds
CPU21:
cpu_time 32.667939260 seconds
vcpu_time 32.667972904 seconds
CPU22:
cpu_time 38.251954202 seconds
vcpu_time 38.251983948 seconds
CPU23:
cpu_time 36.460081452 seconds
vcpu_time 36.460109074 seconds
CPU24:
cpu_time 6.344174920 seconds
vcpu_time 0.000000000 seconds
CPU25:
cpu_time 7.506903059 seconds
vcpu_time 0.000000000 seconds
CPU26:
cpu_time 6.916942265 seconds
vcpu_time 0.000000000 seconds
CPU27:
cpu_time 6.597001417 seconds
vcpu_time 0.000000000 seconds
CPU28:
cpu_time 22.647488723 seconds
vcpu_time 22.647511345 seconds
CPU29:
cpu_time 28.100916697 seconds
vcpu_time 28.100942555 seconds
CPU30:
cpu_time 38.783726425 seconds
vcpu_time 38.783857300 seconds
CPU31:
cpu_time 32.045074950 seconds
vcpu_time 32.045110778 seconds
Total:
cpu_time 1063.004898876 seconds
user_time 46.880000000 seconds
system_time 972.530000000 seconds
Running Cinebench R20 inside the VM Turbo boosts the cores assigned and leaves normally (a bit low for a 3950X but that’s a host issue not a VM  don’t get me started).
don’t get me started).
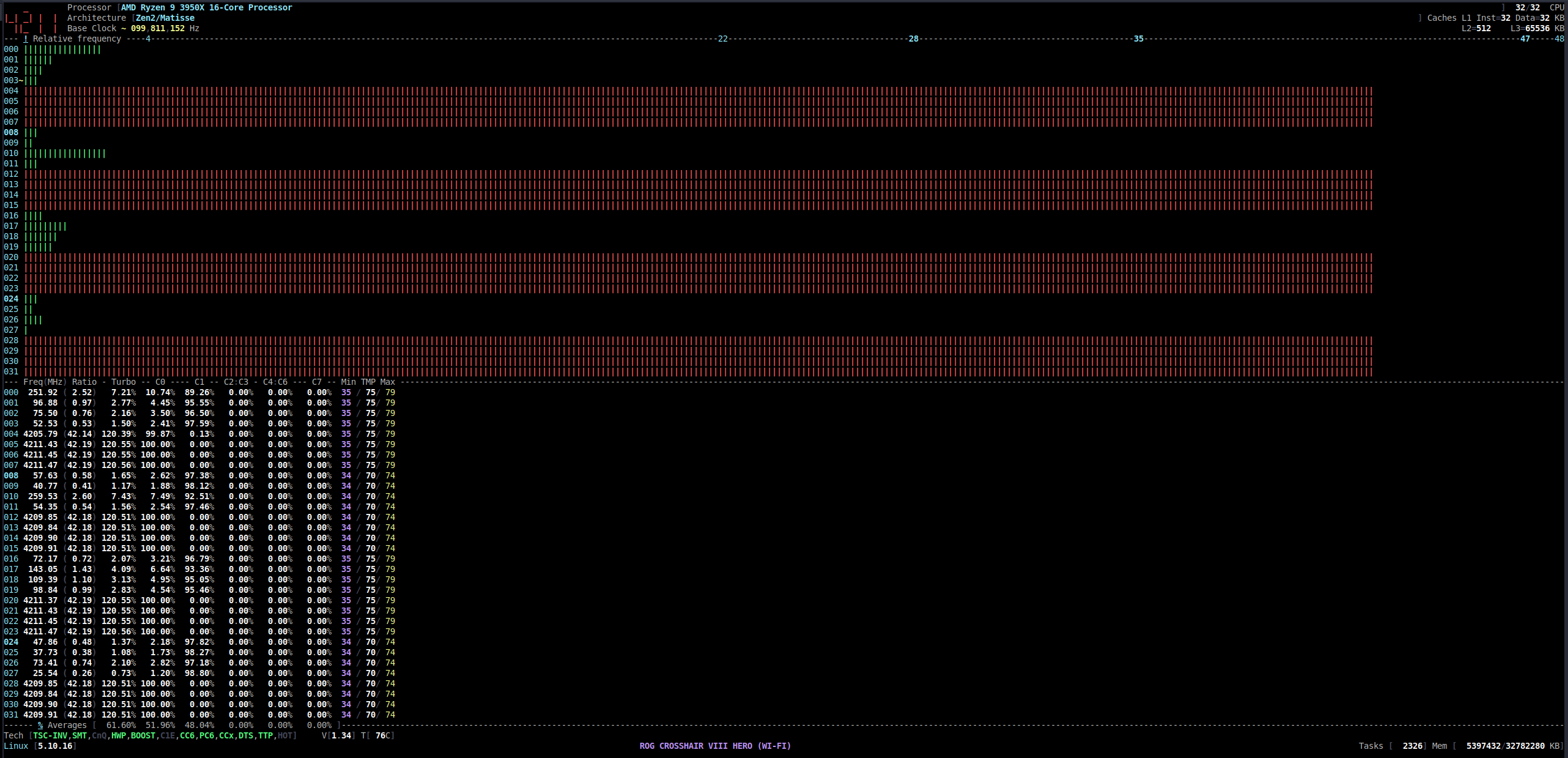
Note: For anyone needing a reminder of Rysen 9 3950X topology (only slightly different than the original post author which is 3900X. I think 3900X has 1 core disabled in each CCX):
lscpu -e
$ lscpu -e 1 ↵
CPU NODE SOCKET CORE L1d:L1i:L2:L3 ONLINE MAXMHZ MINMHZ
0 0 0 0 0:0:0:0 yes 3500.0000 2200.0000
1 0 0 1 1:1:1:0 yes 3500.0000 2200.0000
2 0 0 2 2:2:2:0 yes 3500.0000 2200.0000
3 0 0 3 3:3:3:0 yes 3500.0000 2200.0000
4 0 0 4 4:4:4:1 yes 3500.0000 2200.0000
5 0 0 5 5:5:5:1 yes 3500.0000 2200.0000
6 0 0 6 6:6:6:1 yes 3500.0000 2200.0000
7 0 0 7 7:7:7:1 yes 3500.0000 2200.0000
8 0 0 8 8:8:8:2 yes 3500.0000 2200.0000
9 0 0 9 9:9:9:2 yes 3500.0000 2200.0000
10 0 0 10 10:10:10:2 yes 3500.0000 2200.0000
11 0 0 11 11:11:11:2 yes 3500.0000 2200.0000
12 0 0 12 12:12:12:3 yes 3500.0000 2200.0000
13 0 0 13 13:13:13:3 yes 3500.0000 2200.0000
14 0 0 14 14:14:14:3 yes 3500.0000 2200.0000
15 0 0 15 15:15:15:3 yes 3500.0000 2200.0000
16 0 0 0 0:0:0:0 yes 3500.0000 2200.0000
17 0 0 1 1:1:1:0 yes 3500.0000 2200.0000
18 0 0 2 2:2:2:0 yes 3500.0000 2200.0000
19 0 0 3 3:3:3:0 yes 3500.0000 2200.0000
20 0 0 4 4:4:4:1 yes 3500.0000 2200.0000
21 0 0 5 5:5:5:1 yes 3500.0000 2200.0000
22 0 0 6 6:6:6:1 yes 3500.0000 2200.0000
23 0 0 7 7:7:7:1 yes 3500.0000 2200.0000
24 0 0 8 8:8:8:2 yes 3500.0000 2200.0000
25 0 0 9 9:9:9:2 yes 3500.0000 2200.0000
26 0 0 10 10:10:10:2 yes 3500.0000 2200.0000
27 0 0 11 11:11:11:2 yes 3500.0000 2200.0000
28 0 0 12 12:12:12:3 yes 3500.0000 2200.0000
29 0 0 13 13:13:13:3 yes 3500.0000 2200.0000
30 0 0 14 14:14:14:3 yes 3500.0000 2200.0000
31 0 0 15 15:15:15:3 yes 3500.0000 2200.0000
I think it’s wrong. 3950x has 4 dies (like 3900x), but 4 cores per die (3 for 3900x), right ?
So, it would be :
<cpu mode="host-passthrough" check="none" migratable="on">
<topology sockets="1" dies="2" cores="4" threads="2"/>
<cache mode="passthrough"/>
<feature policy="require" name="topoext"/>
</cpu>
It matches 16 vcpu.
Maybe I am wrong ^^
This is not correct, but seems to work none the less. A core is a thread and the associated hyperthread. Each thread is a VCPU. So if you want to assign 8 physical cores that is 16 VCPUS. Each 4 Cores on your CPU are in a CCX so it results in:
<cpu mode="host-passthrough" check="none" migratable="on">
<topology sockets="1" dies="2" cores="4" threads="2"/>
<cache mode="passthrough"/>
<feature policy="require" name="topoext"/>
</cpu>
This seems correct however:
It means the first 8 threads (or the first 4 cores) have one L3 cache of 16MB as well as the second 8 threads.
1 Like
Hmm I tried your suggestion @anon27075190 with 2 dies 4 cores and 2 threads (same cputune nodes) and the coreinfo output is exactly the same. Windows can’t see a difference or the fact I passthrough the cache is then detected from Windows appropriately regardless of the fact that I have miss configured the topology?
@Ur4m3sh1 sorry for high-jacking your thread 
Seems this way. The whole thing with setting the dies= option for the cache topology is something I learned not too long ago. It seems this behavior is not well documented and kind of experimental. I also was not able to benchmark significant performance improvements after making this change. It still seems plausible that given Windows history of not detecting topologies with AMD CPUs under heavy load or in certain workloads there might be an advantage when configuring it in a transparent way for Windows.
No problem It’s approximately the same topic.
Can you put the return of lstopo command ?

So i lauched cinebench r15/20 in 2 configurations :
1-Current conf :
<cpu mode="host-passthrough" check="none">
<topology sockets="1" dies="1" cores="9" threads="2"/>
<cache mode="passthrough"/>
<feature policy="require" name="topoext"/>
</cpu>
cr15 :

cr20 :
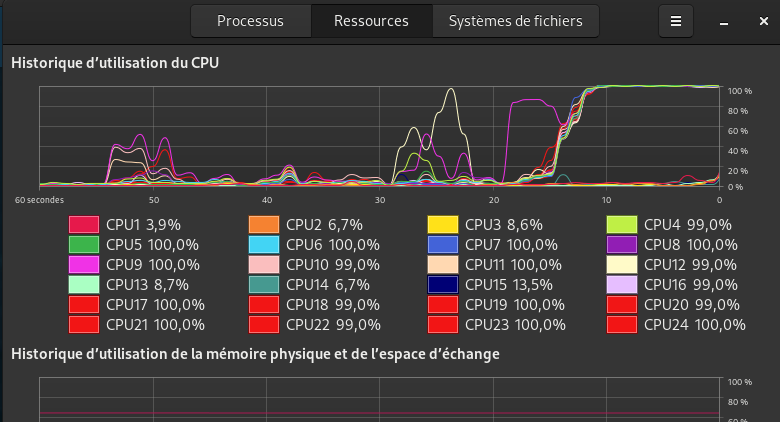
Finally, All cores (9/18T) in cputune are used by the VM.
I got 4800 in cr20 and 2000 in cr15.
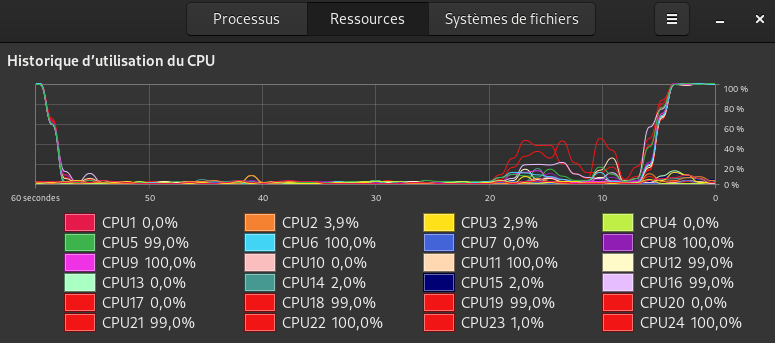
2-modified conf :
<cpu mode="host-passthrough" check="none" migratable="on">
<topology sockets="1" dies="3" cores="3" threads="2"/>
<cache mode="passthrough"/>
<feature policy="require" name="topoext"/>
</cpu>
cr15 :
cr20 :
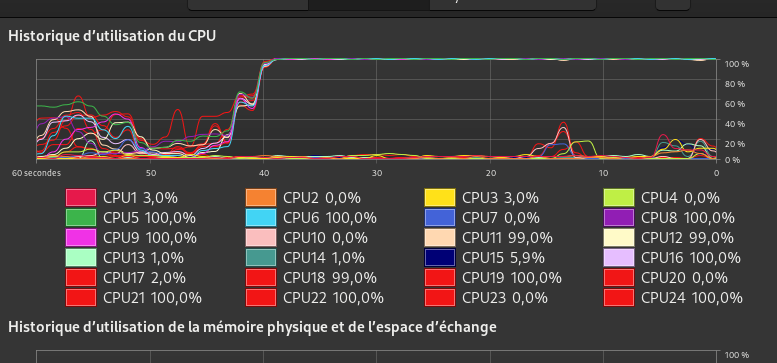
Only 6c/12T are used.
I got 4000 in cr20 and 1675 in cr15.
Conclusion :
The current configuration is better for now. (1 die, 9c, 2T for the topology)
1 Like
I never tried it between different CCDs. You could check with Coreinfo if the cache is even listed correctly. Maybe when we cross the CCD border we need to work with sockets. I maybe investigate this another time, but for now I am happy that you are finally able to use all your cores. If you have an application that only utilized one single VCPU I would guess that it is an problem with the application.
Hmm crossing CCD means your cache won’t be utilised accordingly and you will pass through the Infinity Fabric. Now I kinda wish to have kept my Threadripper 1950x to see how it would work with different NUMA configurations.