Well that ended up taking 13 hours. The subsequent mods did not go as smoothly…
A rare morning beer is in my future.
Well that ended up taking 13 hours. The subsequent mods did not go as smoothly…
A rare morning beer is in my future.
I am setting up an archive NAS that will take about 70TB of uncompressed, undeduped data (mostly large image files).
It needs to, at least temporarily, fit on a ~60TB dataset.
I think I can accomplish this with gzip alone, but am going to throw dedupe into the mix to see how it goes. If it all goes to hell, I just wipe it and try again, nbd.
In this data, there are lots of iterations of photoshop files, often with minor differences between them. They should share a lot of blocks and those blocks should be consecutive.
So, to take full advantage of this, and to eliminate DDT bloat, I’m using a 1M block/record, and I have increased the vfs.zfs.arc_meta_limit tunable to 100GB (system has 128GB), which is roughly 75%. This is obviously much lower than that 3-5:1 GB memory to TB storage ratio that is widely published, but then that’s why:
If it all goes to hell, I just wipe it and try again, nbd.
Currently, the transfer is at about 3.5TB (post compression/dedupe). Dedupe says 5.94TB/5.42TB using about a gig of memory for DDT. Gzip is killing it at 1.55 ratio.
I don’t believe I’ve hit the jackpot of redundant data yet, so I expect the dedupe ratio to increase (~10% now). I’m not sure if this ratio will stay consistent, but 2GB memory per 500GB dedupe is interesting. I think the 1M blocks are helping out there.
More than anything, I am happy to see good gzip numbers early on so that I won’t be too screwed if dedupe doesn’t pan out.
Fwiw, I fully expect not to proceed with dedupe permanently. I’m using an opportunity to satisfy my curiosity.
Checking in before calling it a night. Feeling pretty good about things. I have 4.8TB written to the pool, well over 8TB transferred, 1.55 gzip ratio and 1.1 GB DDT in memory.
If I was to extrapolate from here to 80TB transferred, I’d have ~50TB written and ~12GB DDT. No sweat.
Also, for the record, I am using standard gzip-6. In my experience, gzip-9 is really an exercise in diminishing returns and I am using one of the quiet-cooled systems I wrote about above, so I have a low powered CPU*.
* Update on the Noctua-cooled systems: I replaced the E2630L with the E2630Lv2 and set the fan mode in IPMI to full speed. I am seeing good temps (~50c) during this transfer (which is stressing the CPUs). I still have turbo turned off and eco power turned on, but hyperthreading is on as well as all of the cores. This is a 2u, 2 node system (fat twin).
This particular system has no drives installed in the main chassis (everything is in a jbod), so if/when drives are installed there, I may need to gimp the CPU a bit to accommodate thermals. For now though, I am happy to have all cores handling the initial transfer.
So the final cooling solutions on the 4U 45-drive jbod looks like this:
It is somewhat ghetto, but functional. I added some strips of closed cell foam under the front fans to force the air to come in through the front.
The drives are all reading 30-40 degrees.
For the 3U jbod, I added manual fan controllers to each of the 3 fans and dialed them down slightly to reduce noise. Modding that chassis with new fans was a huge pain. The 4U jbod had 7 screaming fans so it had to be modded, but for 3 fans, dialing the stock fans back a touch is a better solution.
For the Fat Twin chassis, I’m keeping the 80mm Noctuas with turbo and hyper threading turned off. In IPMI, you can turn the fans to go max all the time and that has helped temps a lot. The v2 Xeons also seem to run cooler. Noise is negligible.
Total noise for the whole rack is about 65, but no high pitched resonance, which is what’s really been annoying with the stock fans.
Dedupe progress:
Raw data is at 35.7TB. 4TB have been deduped, taking it down to 31.7TB. DDT is 5GB in RAM.
GZIP ratio is 1.54, taking the total down to just under 22TB.
So still MUCH more painless than I expected. I’m really curious how much the 1M record size is helping here. Unfortunately, I will not have time to do multiple tests.
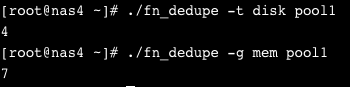
Made a quick script to do dedupe calculations:
It’s a little messy right now, and I need to double check my math but it’s spitting out sensical numbers.
Saving 4TB of storage and using 7GB of RAM (both are truncated, not rounded).
I was out of town for a while but I am back. My dedupe experiment is complete and I am happy with the results. As I hypothesized, 1M records dramatically reduced the dedupe memory requirements while still eliminating lots of redundant data since I was dealing with lots of copies of large files.
Final stats are:
RAM used by DDT: 11GB
Deduped Data: 24TB
Gzip compression ratio: 1.54
Data Written to Pool: 54TB
With all the data copied over, my pool is 85% full, so I just barely pulled it off.
Now I’ll confirm all the data copied and then bring over the drives from the previous system.
so you changed the record size for the dataset to 1M?
Yeah, when I created it.
In case anyone was wondering how to configure Emby to use a Samba 4 AD backend via the LDAP plugin, here it is:
On a related note, this idiocy persists…
https://forum.zentyal.org/index.php?topic=22713.0
User search filter for group membership (via https://emby.media/community/index.php?/topic/56793-ldap-plugin/?p=626737)
(&(|(CN={0}))(|(|(memberof=CN=EmbyGroup,CN=Groups,DC=samdom,DC=domain,DC=tld))))
CN=Groups might be CN=Users depending on your config.
Ok, have to try and figure out which dimm this is… this one is in the DC, so I’ll have to pay them to take it out.
Anyone know how to local a physical dimm on a Supermicro board based on Bank 8 coming from FreeBSD kernel messages?
Is bank a slot or more than that? Hoping it’s a slot, but it sounds like more…
I’ve got 12 dimms in this guy.
> MCA: Bank 8, Status 0x88000040000200cf
> MCA: Global Cap 0x0000000000001c09, Status 0x0000000000000000
> MCA: Vendor "GenuineIntel", ID 0x206c2, APIC ID 35
> MCA: CPU 15 COR (1) MS channel ?? memory error
> MCA: Misc 0xa0a2d08000016081
Relevant:
Can you get serial numbers of the dimms?
Is there a FreeBSD port of dmidecode or something?
https://www.freshports.org/sysutils/dmidecode/
Do a dmidecode -t memory, might work.
yey!
still waiting for stable
woot!
I probably won’t touch it until Ubuntu 20.4 LTS (presumably). I’m just glad it’s making it into .8. I was worried when it wasn’t in the first RCs.
Moving some things around on the dedupe NAS. I am rsyncing a portion of it to another pool with dedupe and gzip-9 instead of default gzip (6 I think?).
So far compression improvement is larger than expected. I am seeing an improvement from 1.54 to 1.73.
The rsync transfer is proceeding at roughly 100GB/hour. According to top, there are 2 rsync processes, one hitting 80-100% cpu and another hitting 30%. I don’t know exactly how to interpret this. I know that uncompressing gzip is inherently single threaded while compressing can be multithreaded, but I don’t know how to unpack the 100/30 ratio here that’s only between 2 threads. In any case, something about the compression, dedupe, plus checksum is limiting the local rsync transfer to 100GB/hour.
TIL
Today I went to Chase Bank to open an account and watched the banker type all my information into Internet Explorer in Windows 7.
Was Steve Ballmer behind the teller pointing a gun to their head?

