Hi all!
I recently built myself a NAS with the intention of storage via NFS (for daily backup via rsync or borg), a Plex server and a few VMs. My special requirement is no noise as this is my dorm room. Edit: Fans are in semi-passive mode (off < 45 celcius) and the temperature is usually around 42 degrees.
I am using an old desktop system (Ryzen 5 1600, Fatal1ty AB350 Gaming-ITX, 32GB RAM, 4x 1 TB Crucial BX500 QLC SSDs (CT1000BX500SSD1) + boot SSD) connected via 1 Gbit ethernet. (Edit: SSDs raid-z1, connected via motherboard SATA ports, and one via cheap expansion card – I had the same issue without the expansion card though.)
Yes those SSDs tank once you fill their cache (going down to ~ 30 MB/s when used alone), but I don’t plan on having long sustained writes (actually maybe later but then I will to add a 1TB 970 EVO or so as write cache), new data moved to the NAS should come in slow increments.
If I copy a single large file (~4GB) I get my full 1 Gbit/s speed for about a minute and then drop to 200 Mbit/s, this is what I would expect for QLC and cache. Reading files as expected is not an issue though (running at full 1 Gbit/s speed).
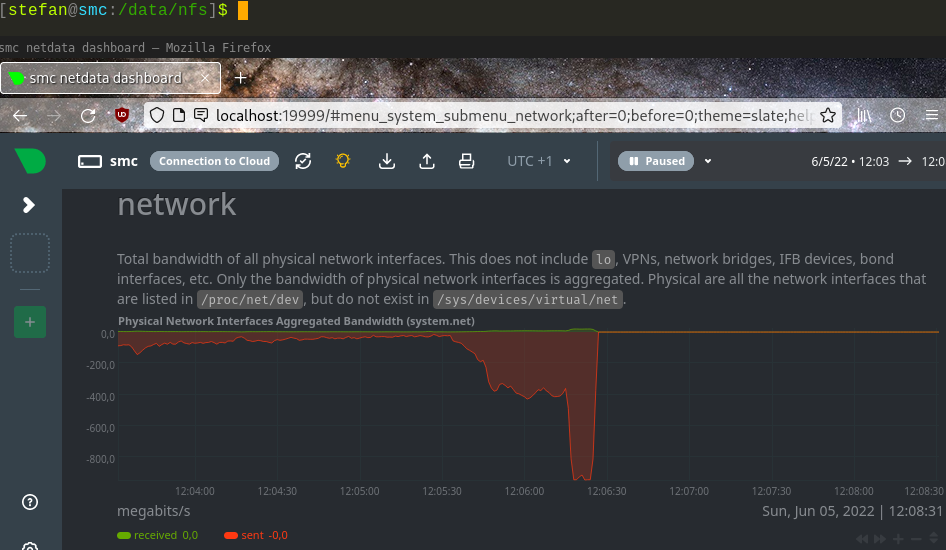
My problem now is that the performance frequently drops to the <1 MB/s level when transferring small-ish files (rsync home directory), for no apparent reason. Sometimes the speed goes up for a minute and down again. I don’t think this is the expected QLC penalty. Here’s a picture of my network transfer rate, with a good speed at the beginning (middle of screenshot) and then the drop to 1 Mbit/s levels.

And here is iostat -w 1 -n 5 -d on my NAS at the same time. I’m rsync-ing my home directory. In this section rsync was working on (~/.cache/mozilla/firefox/) and, after about a minute, the transfer rate (on my network adaptor) dropped from 200 Mbit/s to ~1 Mbit/s. At the same time the transactions per second (tps) drop from ~1000 to ~10.
ada0 ada1 ada2 ada3 ada4
KB/t tps MB/s KB/t tps MB/s KB/t tps MB/s KB/t tps MB/s KB/t tps MB/s
0.00 0 0.00 9.46 876 8.09 9.33 876 7.98 9.25 876 7.91 9.45 876 8.08
0.00 0 0.00 9.36 892 8.16 9.27 892 8.07 9.12 892 7.95 9.36 892 8.16
0.00 0 0.00 11.73 1194 13.68 11.86 1169 13.54 12.72 1090 13.54 11.66 1208 13.76
0.00 0 0.00 9.78 903 8.63 9.70 903 8.55 9.56 903 8.43 9.78 903 8.63
0.00 0 0.00 9.18 897 8.04 9.03 897 7.91 9.02 897 7.91 9.18 897 8.04
0.00 0 0.00 10.63 592 6.15 10.47 592 6.06 10.35 593 6.00 10.77 600 6.31
0.00 0 0.00 9.64 725 6.82 9.47 725 6.70 9.47 724 6.69 9.51 716 6.66
0.00 0 0.00 13.28 1168 15.15 13.19 1157 14.90 13.65 1116 14.88 12.75 1218 15.17
0.00 0 0.00 10.99 867 9.31 10.84 867 9.18 10.69 867 9.06 10.99 867 9.31
0.00 0 0.00 9.53 878 8.17 9.39 878 8.05 9.31 878 7.98 9.53 878 8.17
0.00 0 0.00 9.91 888 8.59 9.83 888 8.52 9.58 888 8.30 9.91 888 8.59
0.00 0 0.00 9.45 897 8.27 9.32 897 8.16 9.24 897 8.09 9.45 897 8.28
0.00 0 0.00 10.60 400 4.14 10.52 398 4.09 9.17 367 3.29 10.33 412 4.16
0.00 0 0.00 19.79 153 2.95 20.86 144 2.93 50.98 59 2.93 18.07 168 2.96
0.00 0 0.00 18.49 122 2.21 18.06 124 2.19 43.41 54 2.30 18.28 123 2.20
0.00 0 0.00 7.42 146 1.06 7.30 148 1.05 13.26 127 1.64 7.41 148 1.07
0.00 0 0.00 6.91 11 0.07 6.91 11 0.07 7.27 11 0.08 7.27 11 0.08
0.00 0 0.00 15.00 32 0.47 15.00 32 0.47 9.28 25 0.23 14.00 34 0.46
0.00 0 0.00 6.95 62 0.42 6.85 60 0.40 11.26 55 0.61 7.07 61 0.42
0.00 0 0.00 15.56 27 0.41 15.56 27 0.41 13.42 31 0.41 15.56 27 0.41
0.00 0 0.00 6.18 11 0.07 6.18 11 0.07 6.55 11 0.07 6.55 11 0.07
0.00 0 0.00 10.93 15 0.16 10.93 15 0.16 10.40 15 0.15 10.67 15 0.16
0.00 0 0.00 7.38 13 0.09 7.08 13 0.09 7.38 13 0.09 7.38 13 0.09
0.00 0 0.00 8.51 87 0.72 9.81 75 0.72 9.57 79 0.74 8.17 96 0.76
0.00 0 0.00 12.21 19 0.22 11.79 19 0.22 12.42 19 0.23 12.42 19 0.23
0.00 0 0.00 6.18 11 0.07 6.18 11 0.07 6.18 11 0.07 6.18 11 0.07
0.00 0 0.00 8.33 12 0.10 8.33 12 0.10 8.00 12 0.09 8.00 12 0.09
0.00 0 0.00 12.62 13 0.16 12.62 13 0.16 12.31 13 0.16 12.92 13 0.16
0.00 0 0.00 9.56 87 0.81 9.26 89 0.80 10.70 71 0.74 10.46 78 0.79
0.00 0 0.00 8.31 13 0.11 8.31 13 0.11 8.57 14 0.12 8.62 13 0.11
0.00 0 0.00 10.00 14 0.14 10.00 14 0.14 9.71 14 0.13 9.71 14 0.13
0.00 0 0.00 7.50 16 0.12 7.25 16 0.11 7.50 16 0.12 7.50 16 0.12
0.00 0 0.00 7.38 13 0.09 7.08 13 0.09 7.69 13 0.10 7.69 13 0.10
0.00 0 0.00 11.10 89 0.96 10.14 97 0.96 11.95 80 0.93 10.26 99 0.99
0.00 0 0.00 10.80 10 0.11 10.40 10 0.10 10.00 12 0.12 10.80 10 0.11
0.00 0 0.00 6.00 12 0.07 6.00 12 0.07 6.55 11 0.07 6.00 12 0.07
0.00 0 0.00 9.00 12 0.11 9.00 12 0.11 9.00 12 0.11 9.33 12 0.11
0.00 0 0.00 10.77 13 0.13 10.77 13 0.13 9.85 13 0.12 10.46 13 0.13
0.00 0 0.00 9.35 83 0.76 9.72 79 0.75 11.59 69 0.78 9.86 84 0.81
0.00 0 0.00 16.00 25 0.39 15.68 25 0.38 15.84 25 0.39 16.16 25 0.39
I also get this issue if I copy, say, a bunch of mp3 files so it’s not tiny files only. It basically occurs in any workload I try, the performance goes down to “unusable” levels with single files often taking seconds to transfer.
Any ideas how to troubleshoot this problem? I suspect it’s drive related rather than protocol since sshfs shows a similar behaviour, but open to suggestions!