Nice!
Remind me what your hypervisor is running?
Nice!
Remind me what your hypervisor is running?
just running Fedora 35 with libvirtd
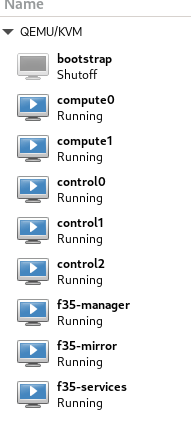
hindsight:
I should have combined the services & manager vm to save about GB or so of ram , there was no need to do two separate VMs.
services vm has: iptables + routing / dhcp / bind / haproxy
manager vm: oc command / kubectl / httpd (for ignition files)
mirror vm: quay image repo
Can you install arbitrary stuff on CoreOS or is pretty locked down? I have drive slots in my servers that won’t be used if I deploy okd on bare metal. Wondering if I can sneak gluster on there.
How much disk space does each vm take up after initial deploy?
i’d guess that if you could figure out how to bake what you want into the ignition files… you could do whatever you want.
the core user has sudo after its running…
from the little bit of poking i did … its using overlayfs
i didnt check each vm after it was all up and running, but from what saw after install, i could have used much less space on each vm… i used 120GB for vm drives… I think that 60GB would have been more than enough also
How much ram do you think you’d want to avoid swapping?
currently the box im using has two 32G dimms and i dont have two more 32GB sticks…
but i do have two 16GB sticks…
so might try to throw them in there, and see what happens.
it was using 4GB of swap
and i disabled zram swap
but swap was on a 900p optane drive, so i wasnt worried about hurting overall performance
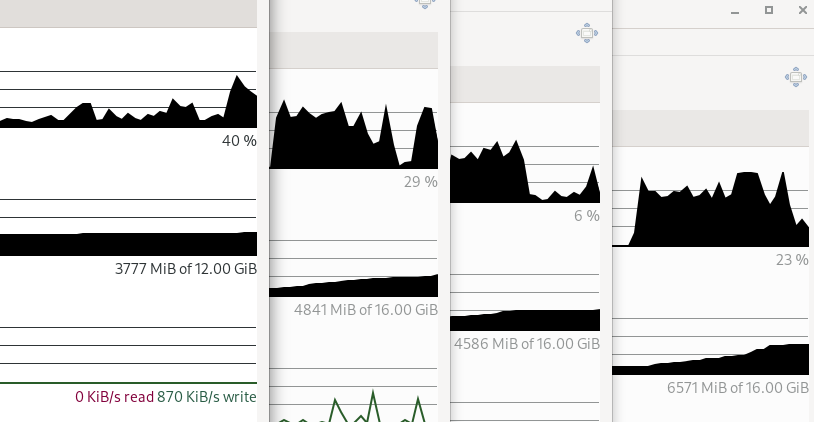
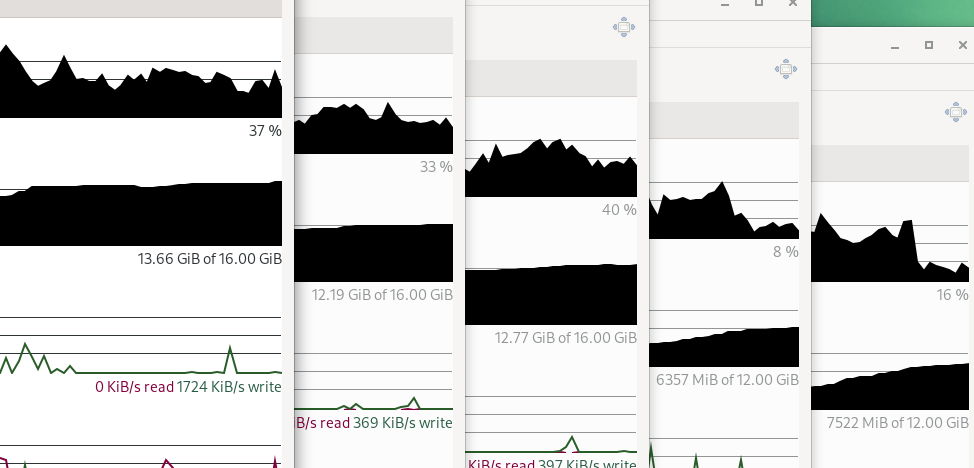
the control plane/master vms had 16G RAM each (and were using ~12G of it
the bootstrap had 12G and probably topped out around 8-9G in use.
the workers had 8G each and were using 6-7G (and i hadnt spun anything up on them either)
so the more the better (after bootstrapping tho, you’ll get to power that vm off)
the mirror vm needed 4GB of ram so it would work, but if your internet is fast enough, you can skip it. (it took 4 hours to preload the mirror repo, and id bet the cluster install would timeout well before then if i didnt have it)
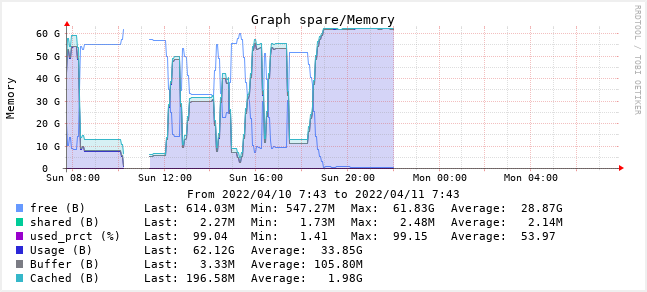
now lets recreate it with 96G of ram…
Going to try not to hit 100% used this time lol
When you dont need a gpu…
(slaps computer)
you can fit so many nvme in this bad boy
doing it again to see if it consistently works
(since ram is mixmatched (2x32 + 2x16 dimms))
bootstrap and 3 control planes
done with bootstrap
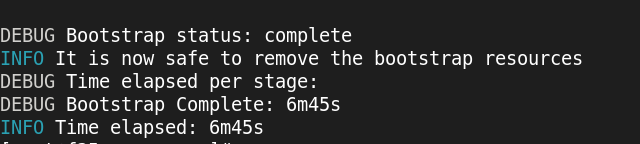
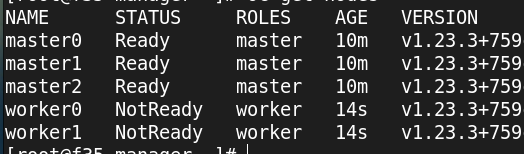
bootstrap shutdown now…
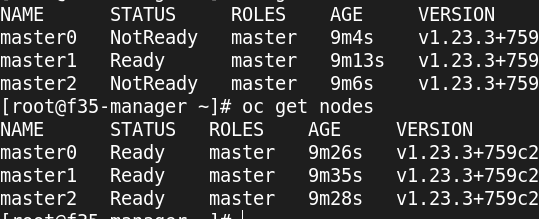
so the 3 control and 2 workers
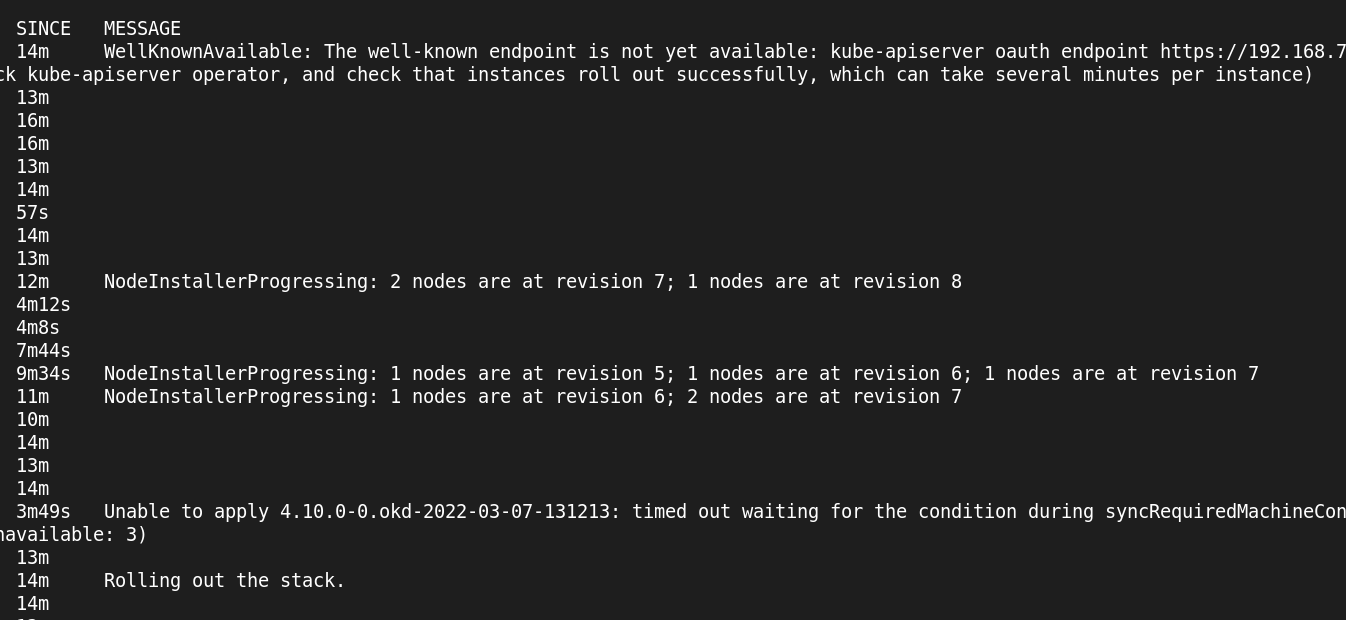
as soon as these messages get resolved… it’ll be happy
this is the last one that needs to clear…
machine-config True True True 8m35s Unable to apply 4.10.0-0.okd-2022-03-07-131213: timed out waiting for the condition during syncRequiredMachineConfigPools: error pool master is not ready, retrying. Status: (pool degraded: true total: 3, ready 0, updated: 0, unavailable: 3)
tired of waiting…
going to reset and try again…
damn so close
next attempt didnt go any better, still at same point with same error on the machine-config pod/role/service thing
so it seems that the ignition/bootstrap stuff that is generated from the openshift-install command is time or try sensitive…
the other day when it worked… it was after generating them fresh…
then the next day i started cluster over again… and the machine-config pod wasnt ending cleanly…
and the last 4 -6 attempts havent worked…
so now as i just generated the configs again… it seems to be working now…
Are you essentially performing bare metal provisioning? Is any of this manipulating the VMs directly through libvirt?
if you’re asking what i think you are…
Im following the instructions as if it is bare metal / UPI
example of what you mean?
i have no idea what im supposed to do to fix this…
but hte last few attempts have this issue that hasnt cleared itself…
machine-config True True True 6m38s Unable to apply 4.10.0-0.okd-2022-03-07-131213: timed out waiting for the condition during syncRequiredMachineConfigPools: error pool master is not ready, retrying. Status: (pool degraded: true total: 3, ready 0, updated: 0, unavailable: 3)
So i think that the machine-config issue was happening too fast in the process that ive taken a core from each VM to slow the install process down, and see if that helps it cleanly finish the install.
So the master nodes went from 4 cores to 3.
the workers still have 4 each.
the bootstrap has 3 now also.
edit…
at this point a reset and reinstall is so simple b/c i setup scripts to do just about everything
trying to eliminate variables on whats causing the machine config sync issue
I believe there are scripts for ESXi and RHV which take control (possibly create?) the VMs via esxcli or whatever.
ah yeah thats the IPI method
i decided against esxi/vcenter… i need all the learning i can get out of this experience.
That was one of 2 reasons I was thinking of using oVirt. I’m not sure but I think there’s an IPI method that will work on oVirt since it’s upstream RHV and so I can use gluster for storage across all nodes.
But of course, part of me wants to do bare metal to reduce the complexity of the final stack.
To what extent would it be possible to use a different reverse proxy solution? Is it hard coded into the deployment to use HAproxy on a RHEL platform?
no… most of the guides /videos i saw were using debian for dhcp/dns/haproxy ( or even raspberry pi’s for services instead of VMs)
im using all fedora VMs for services (plus the FCOS) since i have a internal fedora repo mirror (to save internet downloads)