Thought that maybe vibrations were potentially causing issues since I only had one screw holding each drive in, so I bought a ton of new screws and put 4 in each drive, re-ran the test. Still getting errors.  I’ll pop the lid on the shelf tomorrow and take a look at the internal SAS connections, but I can’t imagine that being the problem since I’m (eventually) getting errors across all the drives in the shelf.
I’ll pop the lid on the shelf tomorrow and take a look at the internal SAS connections, but I can’t imagine that being the problem since I’m (eventually) getting errors across all the drives in the shelf.
It seems a lot more like a problem with the HBA or maybe (but less likely) a problem with the IOM3/6 controller. The DS4243 doesn’t use internal cables. The controllers are connected directly to the backplane. Did yours come with two controllers? If so you could try swapping to controller B. Make sure you use the port marked with a square and don’t connect anything to the circle port. Also make sure you aren’t connecting anything to the RJ-45 ports.
The above info about the cable is right. The IOM3 and IOM6 netapp controllers use a qsfp cable. I believe with a netapp HBA you would just use a regular qsfp DAC. Though connecting to any other HBA, qsfp to sff-8088 and qsfp to sff-8644 cables probably exist for that reason. The IOM12 uses mini SAS connections but that controller is quite expensive.
Edit: I had a chance to read over the post again. If you get access to the shelf, pull both controllers out as well as the blue blanks and shine a flashlight in to inspect the pins. With the lever locked in place, the controller either seats fully or not at all.
2 PSUs are fine. One in slot 1 and the other in 4. You should only need to connect one for the shelf to work but connecting both is probably good if you don’t have easy access to it. If you are wanting to connect both controllers to the HBA, I believe you use the square port on controller A and the circle port on controller B.
Hope that helps
4 Likes
I’m new to this forum software so pardon if I do something stupid with the quoting.
I’ve got an LSI SAS9201-16e on the way, and the SFF-8088/QSFP cable was delivered today, so once the card shows up, hopefully all this will go away.
Yes, it has both IOM3 controllers. I swapped them around last time I reseated the cable with no change in behavior. Confirmed that the QSFP cable was plugged into the square port, not the circle port. The RJ45 ports are empty. I’ve also not connected the controllers together since I only have the one QSFP cable.
Pins and backplane all look good from what I can tell.



The shelf came with PSUs installed in 1 and 4 (top-left and bottom-right when looking at the back of the shelf). Haven’t bothered messing with these at all since the LED status lights seem to indicate they’re working correctly. Both are plugged in but to the same power strip since I don’t have multiple circuits to plug the PSUs into.
I appreciate the input. So far everything seems to be pointing to the HBA. New one is being delivered on the 30th, so hopefully February is the year of mass, stable storage.
2 Likes
New card was delivered while I was at work, and the cable has been here for a few days, so tomorrow I’ll drop it in and see what happens.
For those interested, the QSFP+ cable I had been using is a Juniper Networks 740-038623 Rev 01.
The HBA I had been using is a PMC-Sierra PM8003 SSC Rev 3.0. I had originally ordered a rev 5.0 card because I heard about issues running the 3.0 cards in servers that weren’t specifically the NetApp servers, but the seller had sent this instead. The issues that I saw with the 3.0 were related to the card not being recognized or the card throwing all kinds of errors on boot; seemed totally different than what I saw here, so I dunno if 3.0 cards are generally cursed or if I just happened to have an odd issue.
Now that I’m looking at the card, trying to decide if I should remove the heatsink and clean/reapply the thermal paste, I noticed the A/B/C/D port labels on the back of the card. Fairly sure I was using port D instead of port A. You think that matters at all? Seems like, if it did matter, it wouldn’t work at all, but who knows. Might pop it back in and try it out.
I generally reapply the thermal paste on everything I get used, once I confirm the item works, as who knows how long it’s been sitting there. I do this because it makes me feel better, but does it make a difference? No idea. I’d have to figure out whatever pain in the ass software is needed to look at the temps AND come up with some sort of consistent test. Generally, I don’t think it matters to much for cards with tiny IHS/chips to cover.
I personally prefer IC Diamond paste for things I intend to forget about, as it gives temps similar to top tier pastes like kryonaut, while also being seemingly stable for many years in my own experience. In comparison, most other pastes should probably be reappled after about 2 years.
Also thanks for posting pics of the internals. The thing goes way beyond what I was expecting when it comes to being “special”.
Reinstalled the card in a different slot and with the QSFP+ cable in port A instead of port D with no change (if anything, slightly worse performance since the card was closer to my SFP+ NIC. Decided against reconditioning the cooler since my options are a) tinker with a card I’m going to replace tomorrow morning or b) go home and have dinner lol.
Got the card installed. Here’s some pics of the server and disk shelf. Let’s see if this thing works.







1 Like
So everything looks like it’s been resolved by installing the new HBA. When I booted the server I immediately saw all the disks in the shelves, was able to setup 2 vDevs of 5 disks in a new pool, and ran my usual suite of file transfers to try to invoke an error. The biggest transfer was a 1.5TB folder and a 39GB ZIP file, among other things, and I got zero checksum errors, so that seems to be all resolved. Using Windows File Transfer to copy files across our 10gig fiber network I saw peaks at 1GB/s and a constant file transfer of 350-420MB/s.
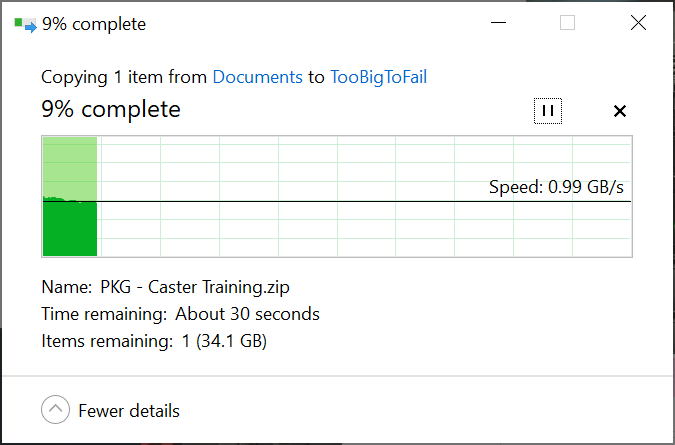
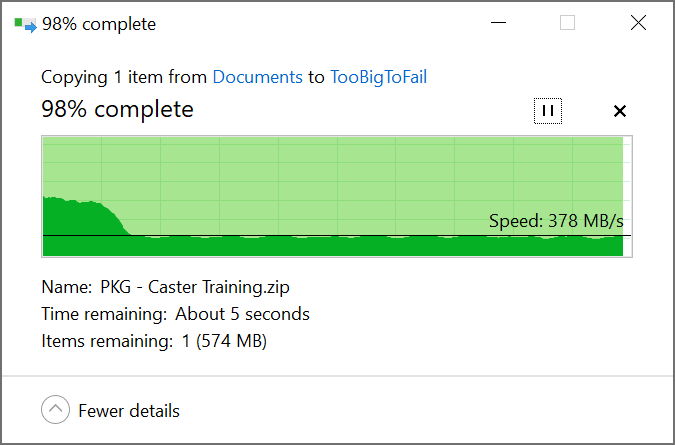

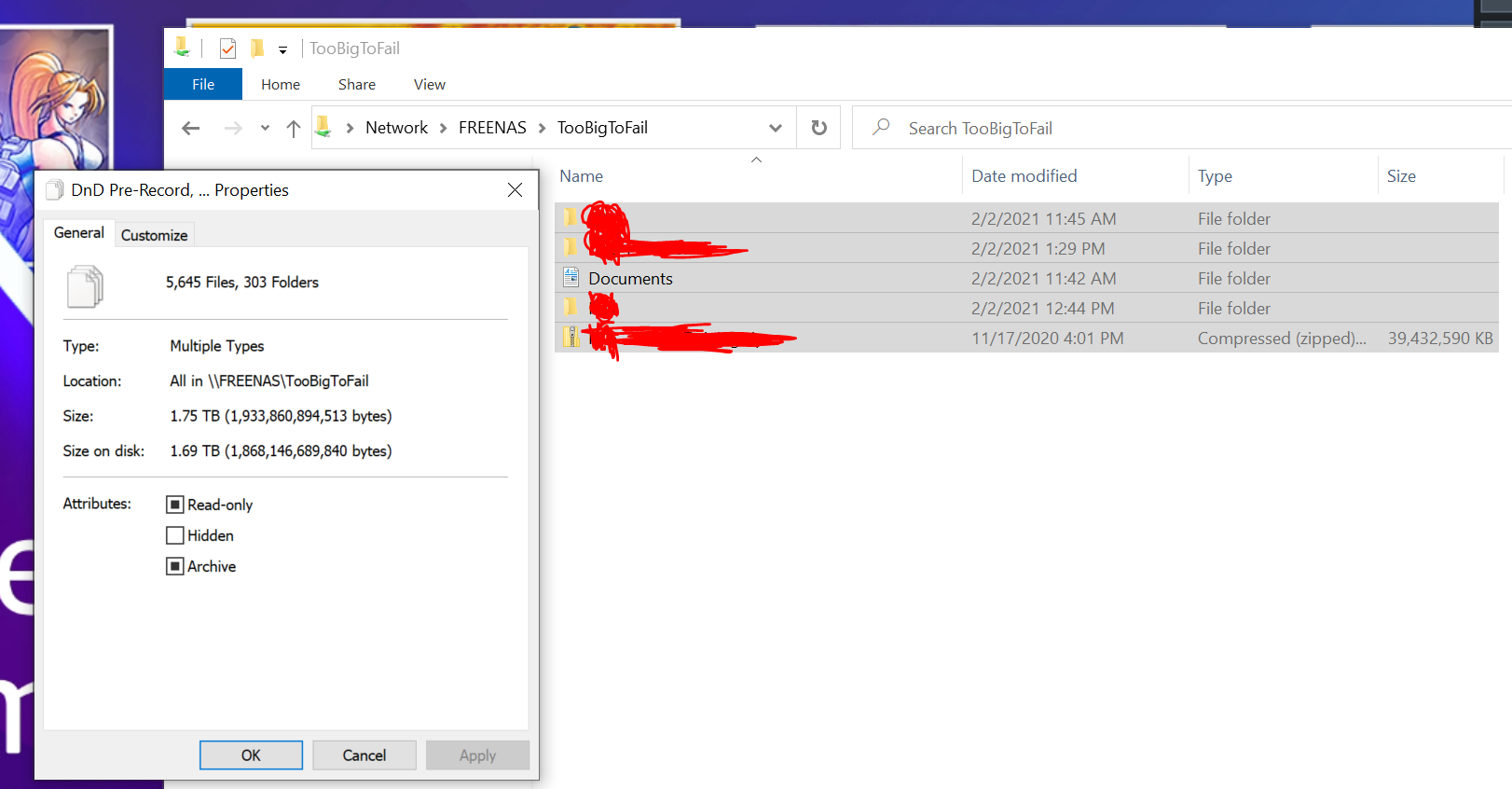
Next I’ll be deciding on how I want to configure the drives, rebuild the pool, and migrate the data from the drives in the server into the disk shelf, then move the drives over to the NAS to expand the storage there (right now it’s 5 striped disks with no redundancy lol).
2 Likes
Very good news, glad it worked out!
Expansion planning is always fun…especially when using ZFS at home. If you can find 2 more disks (referring to the two 5 disk vdevs), you could go with two 6 disk vdevs so you still have some stripe write performance benefit and have the option to expand up to 4 vdevs on that shelf. On my shelf I decided to do a 12 disk raidz2 so I could expand the pool with 12 more disks for consistency. Though even how cheap drives are, buying 12 at a time still hurts… I’m actually thinking about trimming to fewer larger drives. The IOM6 i have does support the 8TB drives i have now and there have been reports it has no problems supporting even larger drives.
Something else… if you’re not planning to use that second controller, you can save about 15-20 watts by disconnecting it. You could just leave it partially in the slot so airflow is unaffected. The second power supply also draws about 30 watts from what I’ve been able to measure. If it is critical that it stays up then the extra power draw is cheap insurance. Otherwise that extra 50ish watts is a pretty good power savings IMO.
2 Likes
Last night I backed up all the current files on my box to a NAS at work so I can wipe the whole system. I have a total of 16 2TB drives, plus a bunch of misc. drives. Based on that, my options are
| # vDevs | RaidZn | drives/vDev | Usable Capacity | Hot Spares | Max Capacity | Hot Spares |
|---|---|---|---|---|---|---|
| 2 | 1 | 8 | 28 TB | 0 | 42 TB | 0 |
| 2 | 2 | 8 | 24 TB | 0 | 36 TB | 0 |
| 3 | 1 | 5 | 24 TB | 1 | 32 TB | 4 |
| 3 | 2 | 5 | 18 TB | 1 | 24 TB | 4 |
| 4 | 1 | 4 | 24 TB | 0 | 36 TB | 0 |
| 4 | 2 | 4 | 16 TB | 0 | 24 TB | 0 |
These figures are assuming I’m only using my disk shelf for storage. I still have 5 bays in my server, so taking that into account, the maximum capacity figures and the number of hot spares available changes quite a bit.
| # vDevs | RaidZn | drives/vDev | Usable Capacity | Hot Spares | Max Capacity | Hot Spares |
|---|---|---|---|---|---|---|
| 2 | 1 | 8 | 28 TB | 0 | 42 TB | 5 |
| 2 | 2 | 8 | 24 TB | 0 | 36 TB | 5 |
| 3 | 1 | 5 | 24 TB | 1 | 40 TB | 4 |
| 3 | 2 | 5 | 18 TB | 1 | 30 TB | 4 |
| 4 | 1 | 4 | 24 TB | 0 | 42 TB | 1 |
| 4 | 2 | 4 | 16 TB | 0 | 28 TB | 1 |
That being said, I’m torn between “This is already plenty of storage” and “I’ll probably just get bigger disks in the future”, so I’m not sure how much planning I want/need to do versus building for speed+resiliency.  If I go with 2 vDevs with RaidZ2, I feel like I’m getting a good compromise of speed and data loss protection, and I can always just buy one or two more drives as a hot spare. Is there a benefit to going with more/smaller vDevs beyond making it less expensive to expand the pool? Better odds of a multi-drive failure not all landing on the same pool?
If I go with 2 vDevs with RaidZ2, I feel like I’m getting a good compromise of speed and data loss protection, and I can always just buy one or two more drives as a hot spare. Is there a benefit to going with more/smaller vDevs beyond making it less expensive to expand the pool? Better odds of a multi-drive failure not all landing on the same pool?
The smaller the vdev is the more disk you’ll lose to parity and/or redundancy. The most performance would probably just be a stripe of mirrors. I tend to go for the largest number of disks in a vdev for maximum capacity. Hot spares for a home user isn’t really necessary IMO. I have my TrueNAS email me anytime there is an issue and use raidZ2 which still gives me 10 disks of capacity with two disks capacity worth of parity.
Each vdev added to a pool is striped together it’s more important that all the vdevs have parity to survive the resilvering process in the event of a disk failure. But when it comes to data security, nothing beats frequent backups…
I agree with the backups thing. I’d like to backup critical files to Backblaze or something once it’s all setup, but hot spares are pretty important for me since, when we’re not in a pandemic, I’m often away from home for long periods of time with work, so it’s nice to have the server maintain itself lol.
Thats a good point if you wouldn’t have access to it. Something to be mindful of is you can add vdevs and you can expand pools with larger disks but you can’t eliminate data vdevs in a pool or reduce the number of disks in a vdev. At least no way I know of.
If it were me, i would go with two 8 disk raidZ2 vdevs. It should help boost write performance while still giving you a good amount of parity. It would also give you the option for one more 8 disk vdev in the future as well.
Moved all the data over from my Drobo (being able to stop using my Drobo was a large reason I underwent all of this). 11% capacity used, and when I pulled the drives out of the box they were also 2TB drives, so now I have 5 more to add to the pool! They’re hot spares for now since the vDevs are 8 drives, but that means I’ll be investing a lot less when it comes to filling the DS4243.
Except that I’m out of caddies so I could only install 3 of the 5 new drives lol.
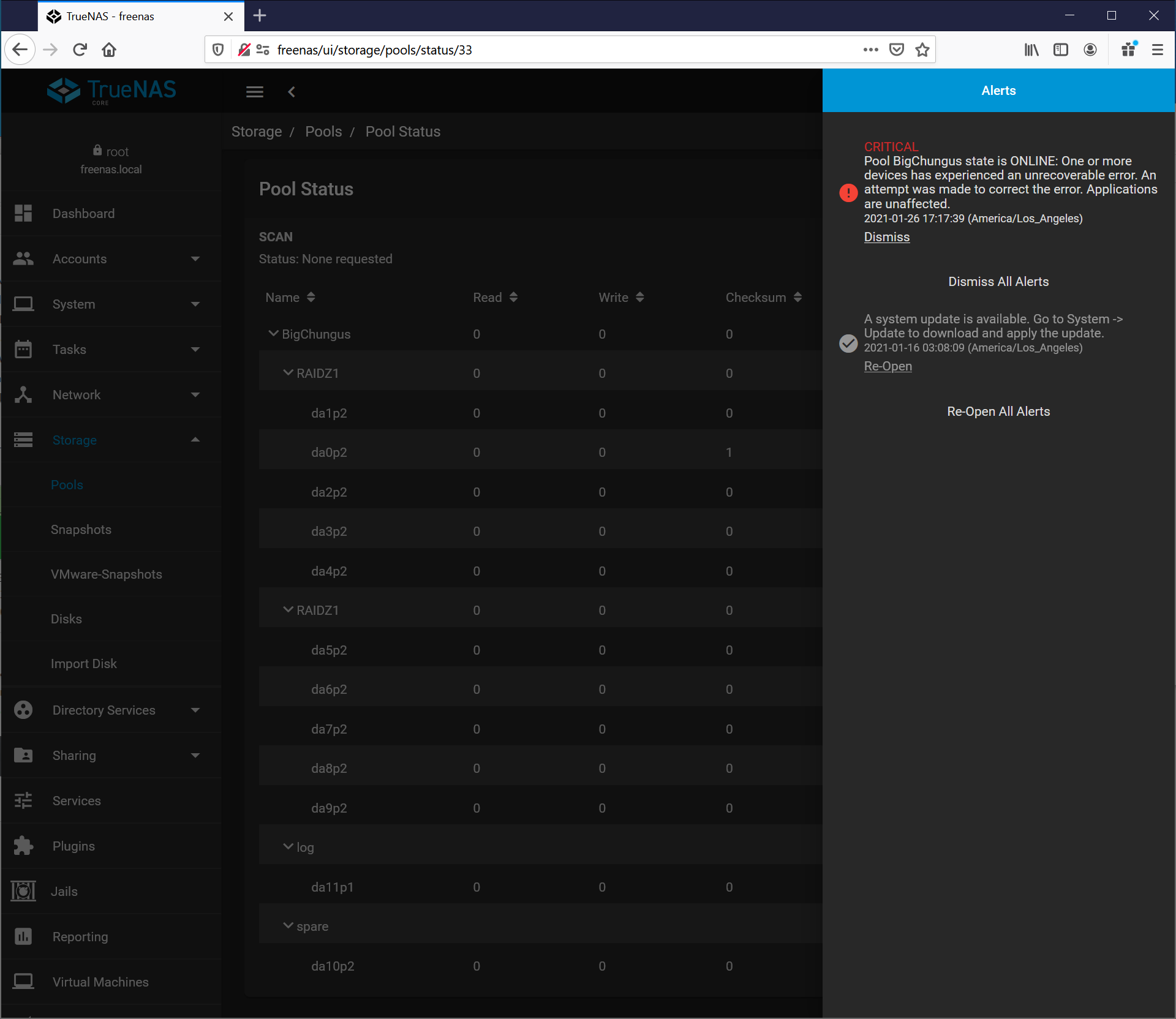
can i ask what process you’re using to determine CRC/Checksum errors ? i’ve been having issues with my DS4243 and LSI 9200 with TrueNAS as well and am in the process of diagnosing everything
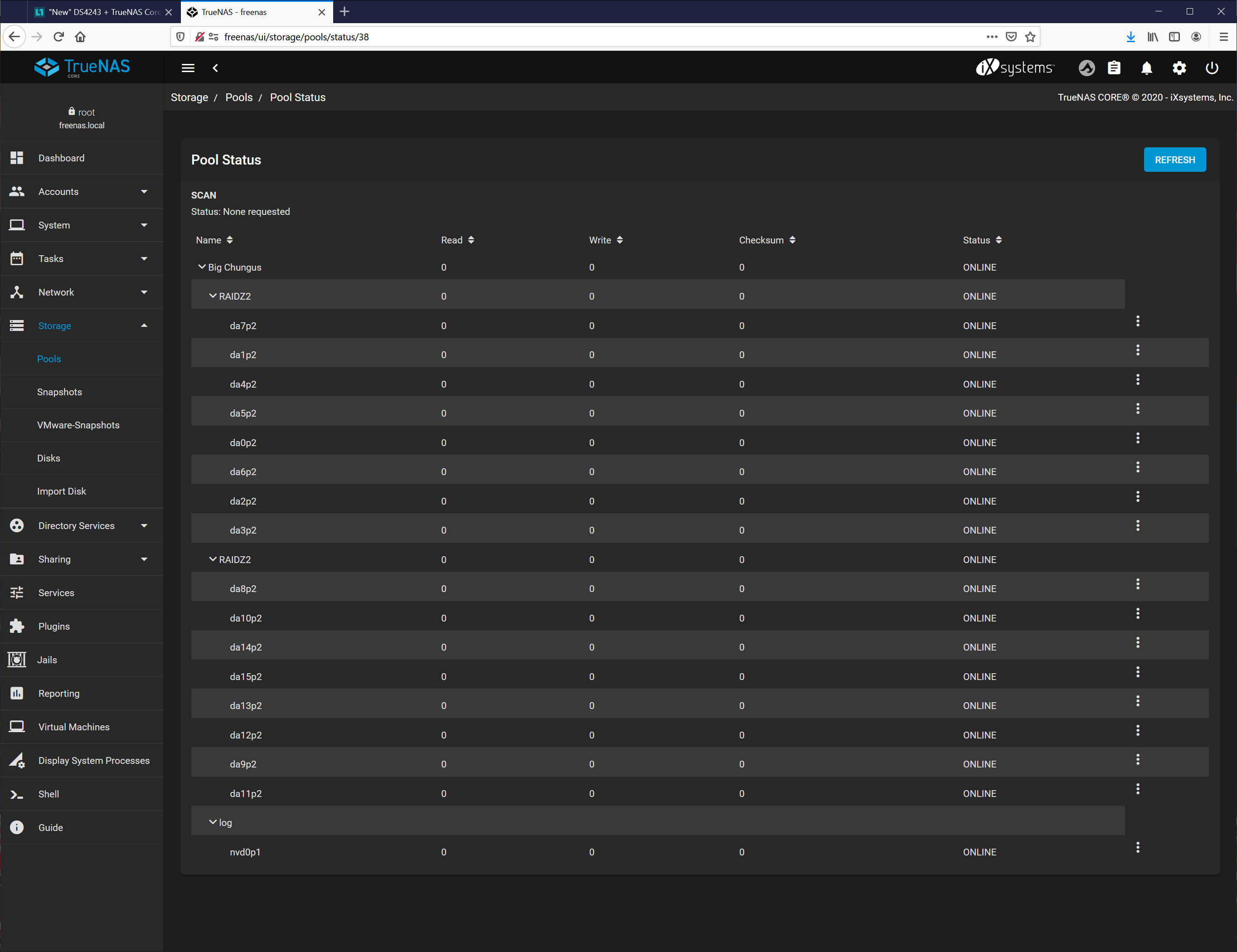
For TrueNAS web UI
After logging in and at your dashboard. On the navigation tree on the left side select “Storage” go to “Pools”. Then click the gear icon for the pool you want to check on the right of the screen then click “Status”
1 Like
Hello from Germany in COVID 19 Times After a LONG search i found your Forum with the same Problem i have.
1 have also a NETAPP 4243 and a PMC8003 Controller. First i uses Freenas 11.3. But it strugling around with lost data connection on DA10 DA11 DA12. an chk errors on these.
All other drives work perfectly. Without trouble. I tought defect drives. But all Drives works in other SLOTs without problems.
So i figured out. I put 2 Fans on the Heatthink of the PMC8003. An what should i say. It is working without loses of drives. DA10 DA11 DA12 never give up. So i think there is first a termo problem with the controller.
But than the totaly disaster happends after Installing TRUENAS12 U2.
All drives become same CHK Errors like you. THATS a totaly disaster of
a wrong SOFTWARE developed DRIVER ERROR.
There is a WRONG Driver(perhaps old with errors) or a fauly DRIVER for the PMC8003 in it. !!! Thats a SOFTWARE FAULT.
So when you go to LSI its ok because of other driver in TRUENAS which has no Problems.
I switch back to 11.3 an what should i say. ALL ERRORs are gone.
First time with a resilvery issus about 36 Hours of TrueNas12 damged ZFS. After thats all drives art ok. Very luck about not losing my Data.
Thats why i normal never change a running system.
If PLEX was lost it where a totaly disaster for me.
So i decided to write to you. Because somebody has same errors.
First COOLING the HBA with Fans . I have a HPG7 Server there not enough ventilaton. i don t wont running on maximum fans speed from Server.
Not go to Truenas 12 or you data will belost in the MOMENT by using PM8003. It think a update will next fix this issue.
Thats took me a lot of time to figured out ithink 1 week trying everything.
Also PCB REWORK of the DA10 DA11 DA12 SAS Connectors.
2 ERRORs HEAT an TRUENAS.
I am angry because of truenas looks very good i would have it. ! GRRRRRRRR
So i share my experiance. For other having same issue. Thank you.
Greetings
BB
1 Like
My Solution of Temperature Problem so all CHKsum errors gone.
Now i wait for bug fixed Truenas Version 12 which supports PMC8003 right.

There is a 12V Connector on the PCB of PCM8003. I soldered in Jumper Pins.

The fan i stick with glue.
Greetings
BB
1 Like
This topic was automatically closed 273 days after the last reply. New replies are no longer allowed.