I recently picked up a NetApp DS4243 from a local PC recycler to use for my home lab and threw a bunch of 2TB drives into it. The drives were all recognized with the correct metadata all showing up, so I created a pool with 2 5-drive vDevs in raidZ-1 with another drive as a hot spare. This wasn’t going to be my final configuration, I just wanted to flex on my coworkers. To verify everything was working as it should, I transferred one or two hundred gigs of files to the new array and everything was going swimmingly until I noticed a new notification in the TrueNAS GUI warning of a critical issue and that my pool was unhealthy.
Pool BigChungus state is ONLINE: One or more devices has experienced an unrecoverable error. An attempt was made to correct the error. Applications are unaffected.
Fast forward through me trying to figure out exactly what the errors are, zpool status -v and it’s equivalent in the GUI both show no errors for read or write, but a non-zero amount of errors for checksum. I’ve reseated drives in the caddies, shuffled drives around, tried various combinations of raidZ, stripe, and single-drive vDevs, all with the same result. After transferring around 200 gigs of files, either from the pool internal to the server, or from another machine on the same network, I’ll get between one and four errors logged for checksum.
The drives in the shelf right now are 11x 2TB Toshiba SAS drives, a 2TB SATA drive, a 1TB Western Digital Green, and a 1TB Western Digital Black. All the SATA drives are using interposers. The SAS drives are all recent pickups from Craigslist, but I have the exact same errors on the WD SATA drives I’ve had since new, and the 2TB SAS drives in the server’s hot swap bays are identical to what’s in the shelf, and they even came from the same CL seller, so I’m strongly suspecting something that isn’t directly the drive.
The server is an Intel SR2600 with 2x Xeon X5677 CPUs, 96GB of ECC RAM, running TrueNAS Core 12.0-U1 from a USB 2.0 drive. The HBA I’m using to interface with the shelf is a PMC/Sierra PM8001 v3.0. That’s connected to a QSFP or QSFP+ cable that came from the same recycler. It’s largely unlabeled and I found it in a bin of misc. server cables, so that’s a pretty big unknown. Should probably clean the contacts with CRC? The DS4243 has two IOM3 cards. From what I remember the top card was slightly dislodged when I was looking at it at the recycler, so even though I put it back in, maybe it needs to be reseated. The server lives in the warehouse at my work, so I can log into it remotely, but I don’t have hands-on access at the moment to retry anything physical. The shelf has two of the four PSUs installed. I don’t think the PSUs would create such a specific issue, but I can try running with a single unit at a time to see of there’s any change in behavior.
Is there anything else I’m missing? The shelf was unpopulated when I bought it, so all the drives are formatted to 512 bytes per sector, and are otherwise recognized and seem to be writing data at full speed (91-130MB/s), at least in my most recent testing with only a small number of drives installed. I’m running a long SMART test on the drives right now (in theory, anyway, since I haven’t found any way to monitor the progress of the test), so I’ll see if anything is up in the morning once those have finished.
Edit: I should also mention that the checksum errors do not appear simultaneously across all the drives in the pool. They appear one at a time, and do not necessarily show up the same number of times across the drives.

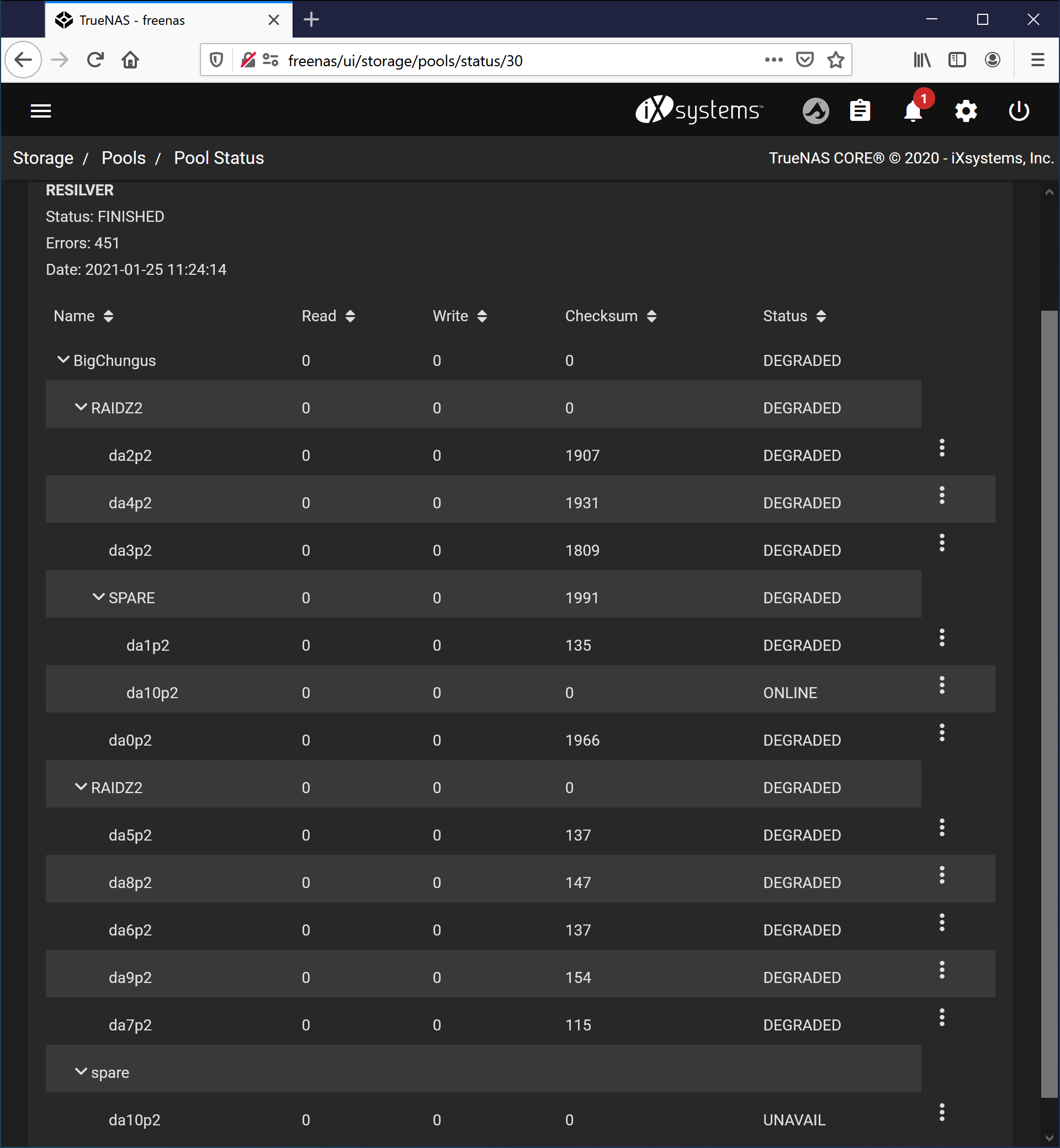
 I’ll pop the lid on the shelf tomorrow and take a look at the internal SAS connections, but I can’t imagine that being the problem since I’m (eventually) getting errors across all the drives in the shelf.
I’ll pop the lid on the shelf tomorrow and take a look at the internal SAS connections, but I can’t imagine that being the problem since I’m (eventually) getting errors across all the drives in the shelf.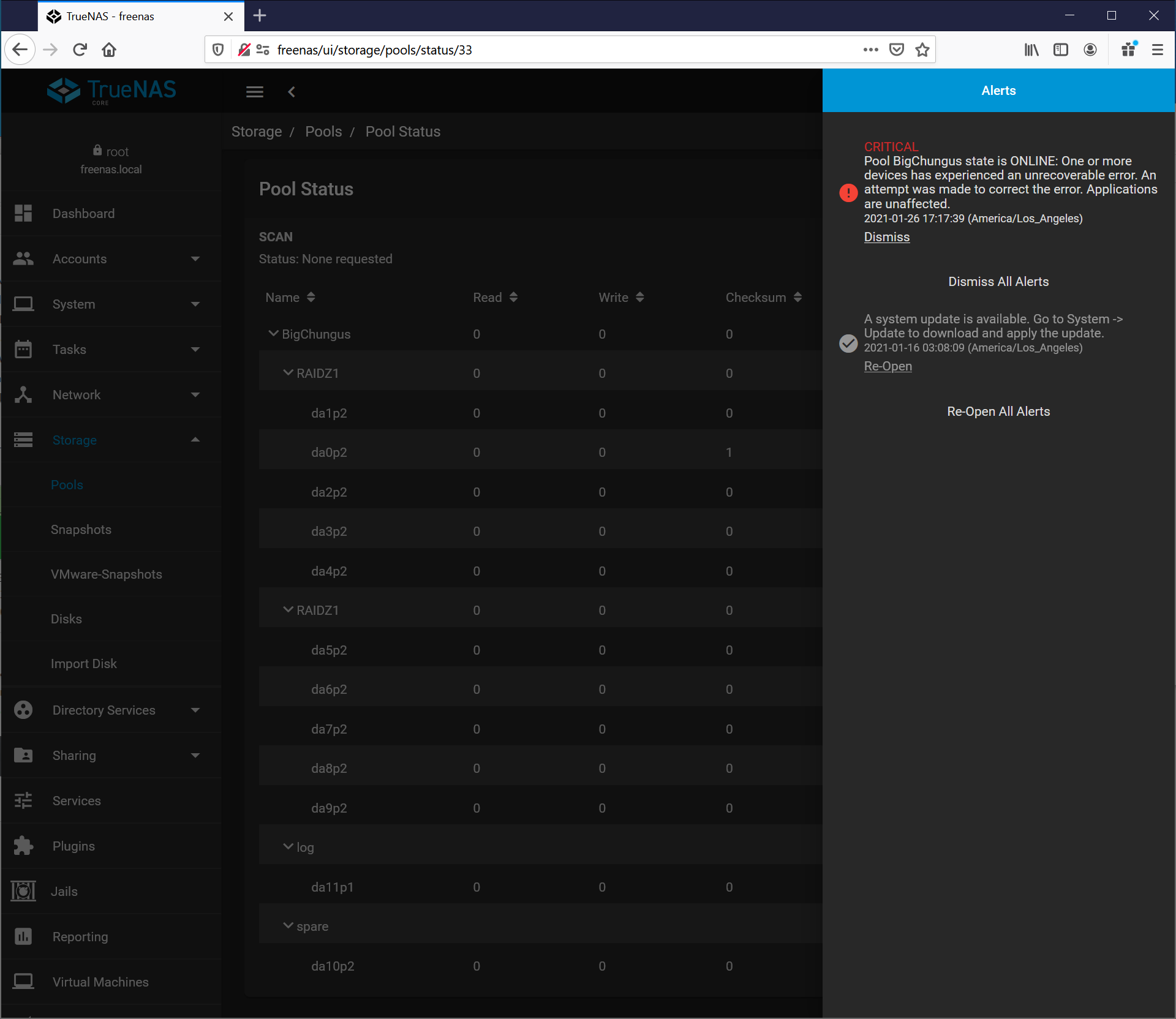











 If I go with 2 vDevs with RaidZ2, I feel like I’m getting a good compromise of speed and data loss protection, and I can always just buy one or two more drives as a hot spare. Is there a benefit to going with more/smaller vDevs beyond making it less expensive to expand the pool? Better odds of a multi-drive failure not all landing on the same pool?
If I go with 2 vDevs with RaidZ2, I feel like I’m getting a good compromise of speed and data loss protection, and I can always just buy one or two more drives as a hot spare. Is there a benefit to going with more/smaller vDevs beyond making it less expensive to expand the pool? Better odds of a multi-drive failure not all landing on the same pool?