I realized I am going to need a good amount of assistance learning and creating this script. So here is the idea. I have this music library of both high and low quality FLACs right? Its all FLAC and all of the meta data is accurately placed in it by MusicBrainz Picard.
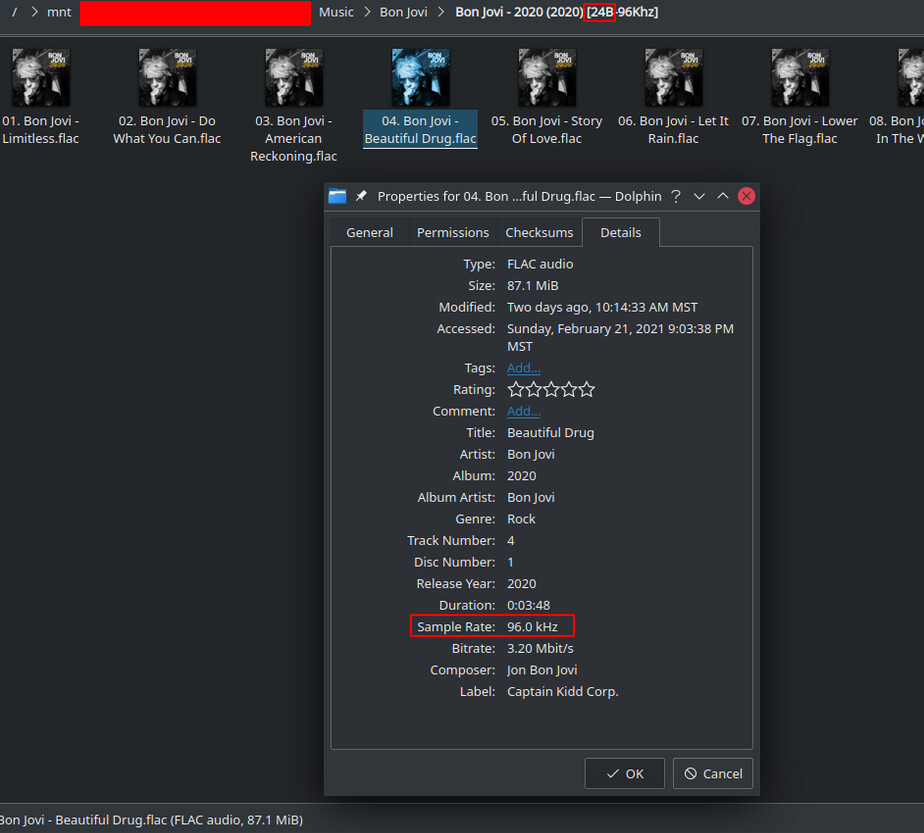
As we can see above its sorted by artist>release-album>files.flac
The idea here now becomes what duplicates do I keep. I wish it were as easy as just choosing the higher sample rate FLAC but it isnt. We all know that when it comes to true masters of music 24 bit depth is chasing fidelity where 16 bit depth is driving volume so to speak. The sample rate is a different story. I want to make sure im not deleting my ONLY copy of a release.
So here is the concept I want to employ is that we need to pull this information for every single file.
#➤ [Bon Jovi - 2020 (2020) [24B-96Khz]] metaflac --show-sample-rate --show-bps 01.\ Bon\ Jovi\ -\ Limitless.flac
96000
24
#➤ [Bon Jovi - 2020 (2020) [24B-96Khz]]
So the first thing I need to do is create an array or data set with ALL the files full directory paths. I am assuming find -type f > musicPaths.txt In the directory would work but thats not storing the directories in an array to step through? This is an array I can pull from for each directory and run the above command on it and store whatever is 24 bit and 16 bit into respective smaller arrays
From there the script would have to go in and sort each of the 24 bit and 16 bit arrays into smaller arrays of which are which sample rate. Sorting them into named arrays 16B44.1K, 16B48k, 16B96k, 24B44.1k and so on and so forth
From there the script would then need to sort for duplicate MAIN song title names excluding stuff like live etc…
From there it would need to choose the least quality duplicates and place those in an array. Then rm would have to just remove each file from the directory as listed in the deleteThis array. I want to make sure im not deleting my ONLY copy of a release.
How would I start. Where would I start. I have a sort of idea of what to do. If I need to clarify this please expound on where you need clarification in order to assist me in brainstorming.

 'd
'd