The MOE states of the MOESI cache protocol do require a transition with a 32mb data set? The threadripper L3 is 32mb in size, to small for the data referenced, and the cache coherency operates at L2. I would guess that at best, the source and dest cache lines are loaded from L3, then the dest cache line is modifed. 2 x 32mb read, 1 x 32mb write.
The prefetch instructions are more useful for random access where the CPU can’t predict the next access.
So bottom line to what you’re saying is, two Zeppelin dies on a threadripper, each having two channels of DDR (48GB/channel at 3GHz). Being interconnected with a 42GB/s of non-infinite fabric, copying faster than 0.7ms, is unlikely… Unless split across cores and being very careful as to how buffers are allocated (what APIs do you even use to request ram from a specific die?), and even then it may make sense to use sfence.
What if what was copied was a 2MB buffer and was copied 16 times, would that be any better?
Would this help given how we need to take the frame data out using PCIe in the guest, and write it using PCIe on the host, does it help overall latency if we don’t need to write this temporary data all the way to main ram (the memcpy tests from this thread ignore the fact data is in PCIe).
Edit: with PCIe, for example, if we could take 2MB of a frame into L3, then take another 2MB… while that second 2MB chunk is coming into L3, the first 2MB could be on their way to the host GPU… That way, by the time you’re done reading 32MB, you only have 2MB left to write to host GPU and that’s already in L3. (2MB / 16GBps (pcie3.0) == 125uS + whatever the signaling overhead; leaving plenty of headroom for other things that might influence tail latencies).
I don’t know what I’m saying, it’s difficult operating at this level, nanoseconds matter. There are probably other more meaningful optimizations to look at.
You’d have to do numa & thread pinning tricks to get a specific mem region:
$ numactl -C <cpus> -m <mem-node> command
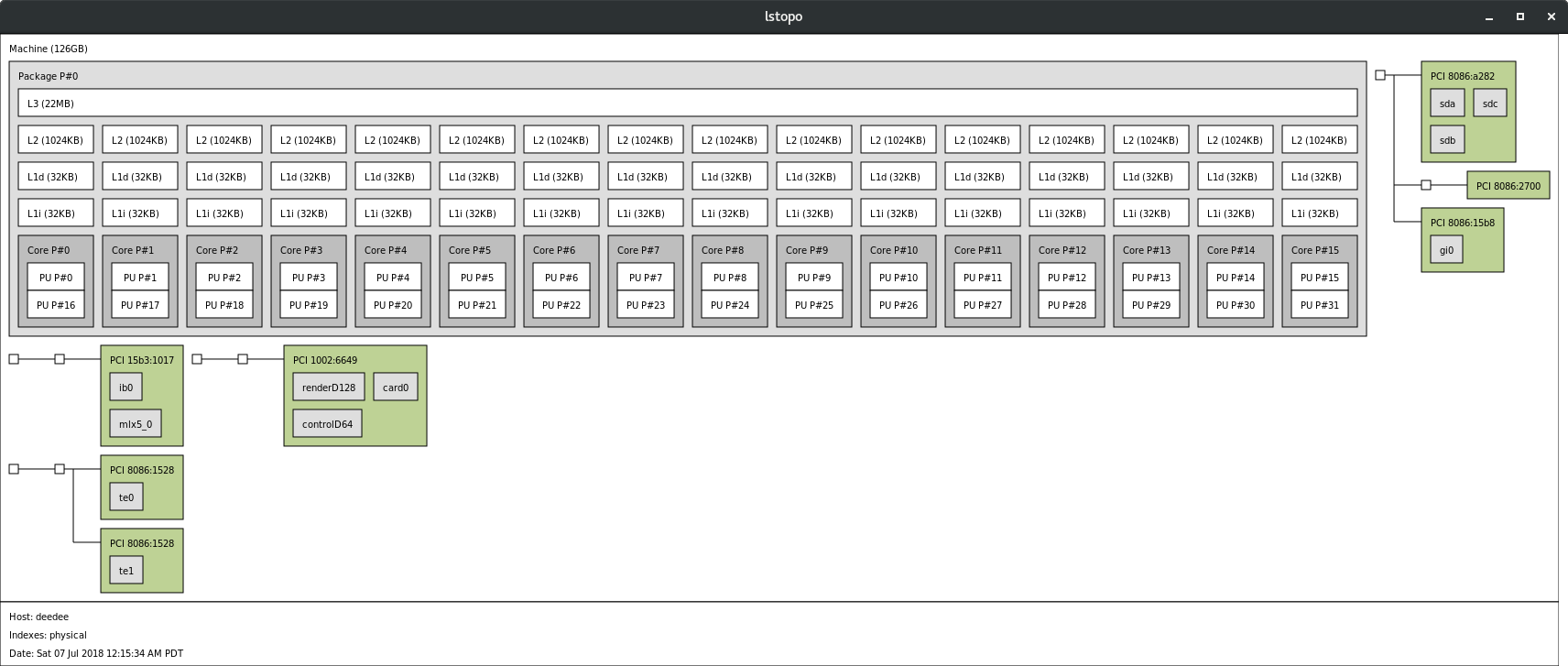
The “lstopo” command is useful (i9, sorry, my threadripper is in the shop):
The PCIe is going to be using DMA to pinned memory regions set up on the host, there’s no escape from main memory. The DMA does do a copy like the movtnq instruction, with weaker coherency rules (I have an option in BIOS to change that).
I would guess that multiple threads would be effective if they are running on the same numa node. To saturate the memory bandwidth, several threads are necessary. The timing issues with multiple threads are more difficult, I would be hesitant to do it that way.