At this point it should be said that the method being used for timing these operations is not ideal. CLOCK_MONOTONIC_RAW is not a good indicator of how much time a program spends on CPU, because it includes all the time the OS spends doing things besides running your program (running other programs, for example).
Diffs
testmem_cputime.c
--- testmem_modified.c 2018-06-01 19:10:10.948411000 -0700
+++ testmem_cputime.c 2018-06-01 18:38:16.329042000 -0700
@@ -44,7 +44,7 @@
{
struct timespec time;
- clock_gettime(CLOCK_MONOTONIC_RAW, &time);
+ clock_gettime(CLOCK_PROCESS_CPUTIME_ID, &time);
return ((uint64_t)time.tv_sec * 1e9) + time.tv_nsec;
}
@@ -63,9 +63,8 @@
uint64_t t = nanotime();
- void *(*memcpy_ptr)(void *, const void *, size_t) = memcpy;
for(volatile int i = 0; i < 1000; ++i)
- memcpy_ptr(buffer1, buffer2, size );
+ memcpy(buffer1, buffer2, size );
printf("%2u MB = %f ms\n", s, ((float)(nanotime() - t) / 1000.0f) / 1000000.0f);
printf("-Compare match (should be zero): %2u \n\n", memcmp(buffer1,buffer2,size)) ;
free(buffer1);
testmem_cputime_sse.c
--- testmem_modified.c 2018-06-01 19:10:10.948411000 -0700
+++ testmem_cputime_sse.c 2018-06-01 18:38:16.330004000 -0700
@@ -44,7 +44,7 @@
{
struct timespec time;
- clock_gettime(CLOCK_MONOTONIC_RAW, &time);
+ clock_gettime(CLOCK_PROCESS_CPUTIME_ID, &time);
return ((uint64_t)time.tv_sec * 1e9) + time.tv_nsec;
}
@@ -63,9 +63,8 @@
uint64_t t = nanotime();
- void *(*memcpy_ptr)(void *, const void *, size_t) = memcpy;
for(volatile int i = 0; i < 1000; ++i)
- memcpy_ptr(buffer1, buffer2, size );
+ memcpy_sse(buffer1, buffer2, size );
printf("%2u MB = %f ms\n", s, ((float)(nanotime() - t) / 1000.0f) / 1000000.0f);
printf("-Compare match (should be zero): %2u \n\n", memcmp(buffer1,buffer2,size)) ;
free(buffer1);
Linux 4.16.9-1-ARCH (GCC)
model name : AMD FX™-8320 Eight-Core Processor
[ryan@fx8320-arch memcpy_sse]$ for src in testmem_cputime*.c; do
echo "${src} (64-bit)"
echo "---------------"
gcc -O3 -march=native -m64 ${src} -o tm64
for i in $(seq 10); do ./tm64 32; done
echo "${src} (32-bit)"
echo "---------------"
gcc -O3 -march=native -m32 ${src} -o tm32
for i in $(seq 10); do ./tm32 32; done
echo "${src} (32-bit, -fno-builtin-memcpy)"
echo "------------------------------------"
gcc -O3 -march=native -m32 -fno-builtin-memcpy ${src} -o tm32
for i in $(seq 10); do ./tm32 32; done
done
Results
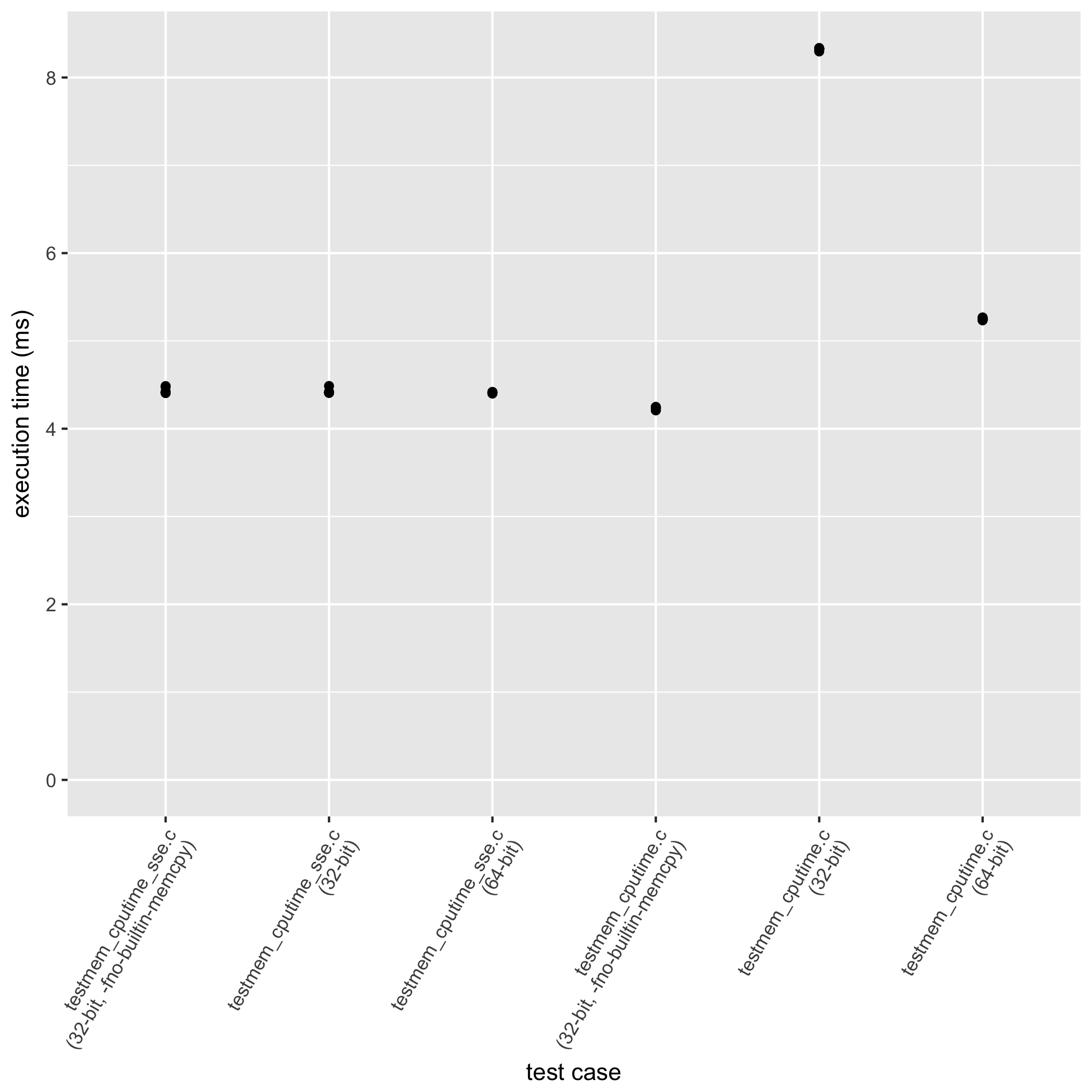
testmem_cputime.c (64-bit)
32 MB = 5.241058 ms
-Compare match (should be zero): 0
32 MB = 5.243259 ms
-Compare match (should be zero): 0
32 MB = 5.266191 ms
-Compare match (should be zero): 0
32 MB = 5.240136 ms
-Compare match (should be zero): 0
32 MB = 5.256821 ms
-Compare match (should be zero): 0
32 MB = 5.266900 ms
-Compare match (should be zero): 0
32 MB = 5.234083 ms
-Compare match (should be zero): 0
32 MB = 5.251327 ms
-Compare match (should be zero): 0
32 MB = 5.249514 ms
-Compare match (should be zero): 0
32 MB = 5.244353 ms
-Compare match (should be zero): 0
testmem_cputime.c (32-bit)
32 MB = 8.323980 ms
-Compare match (should be zero): 0
32 MB = 8.328946 ms
-Compare match (should be zero): 0
32 MB = 8.329352 ms
-Compare match (should be zero): 0
32 MB = 8.296982 ms
-Compare match (should be zero): 0
32 MB = 8.326883 ms
-Compare match (should be zero): 0
32 MB = 8.336661 ms
-Compare match (should be zero): 0
32 MB = 8.329819 ms
-Compare match (should be zero): 0
32 MB = 8.321874 ms
-Compare match (should be zero): 0
32 MB = 8.324215 ms
-Compare match (should be zero): 0
32 MB = 8.321898 ms
-Compare match (should be zero): 0
testmem_cputime.c (32-bit, -fno-builtin-memcpy)
32 MB = 4.249210 ms
-Compare match (should be zero): 0
32 MB = 4.238623 ms
-Compare match (should be zero): 0
32 MB = 4.223117 ms
-Compare match (should be zero): 0
32 MB = 4.246448 ms
-Compare match (should be zero): 0
32 MB = 4.232831 ms
-Compare match (should be zero): 0
32 MB = 4.211716 ms
-Compare match (should be zero): 0
32 MB = 4.236586 ms
-Compare match (should be zero): 0
32 MB = 4.208664 ms
-Compare match (should be zero): 0
32 MB = 4.215388 ms
-Compare match (should be zero): 0
32 MB = 4.238823 ms
-Compare match (should be zero): 0
testmem_cputime_sse.c (64-bit)
32 MB = 4.416759 ms
-Compare match (should be zero): 0
32 MB = 4.412868 ms
-Compare match (should be zero): 0
32 MB = 4.419092 ms
-Compare match (should be zero): 0
32 MB = 4.413001 ms
-Compare match (should be zero): 0
32 MB = 4.413273 ms
-Compare match (should be zero): 0
32 MB = 4.411419 ms
-Compare match (should be zero): 0
32 MB = 4.407824 ms
-Compare match (should be zero): 0
32 MB = 4.406849 ms
-Compare match (should be zero): 0
32 MB = 4.399800 ms
-Compare match (should be zero): 0
32 MB = 4.407373 ms
-Compare match (should be zero): 0
testmem_cputime_sse.c (32-bit)
32 MB = 4.420913 ms
-Compare match (should be zero): 0
32 MB = 4.410238 ms
-Compare match (should be zero): 0
32 MB = 4.411091 ms
-Compare match (should be zero): 0
32 MB = 4.486512 ms
-Compare match (should be zero): 0
32 MB = 4.414333 ms
-Compare match (should be zero): 0
32 MB = 4.408229 ms
-Compare match (should be zero): 0
32 MB = 4.408923 ms
-Compare match (should be zero): 0
32 MB = 4.411462 ms
-Compare match (should be zero): 0
32 MB = 4.410039 ms
-Compare match (should be zero): 0
32 MB = 4.411212 ms
-Compare match (should be zero): 0
testmem_cputime_sse.c (32-bit, -fno-builtin-memcpy)
32 MB = 4.422927 ms
-Compare match (should be zero): 0
32 MB = 4.479233 ms
-Compare match (should be zero): 0
32 MB = 4.405762 ms
-Compare match (should be zero): 0
32 MB = 4.414087 ms
-Compare match (should be zero): 0
32 MB = 4.411552 ms
-Compare match (should be zero): 0
32 MB = 4.476846 ms
-Compare match (should be zero): 0
32 MB = 4.485496 ms
-Compare match (should be zero): 0
32 MB = 4.407228 ms
-Compare match (should be zero): 0
32 MB = 4.416489 ms
-Compare match (should be zero): 0
32 MB = 4.413395 ms
-Compare match (should be zero): 0
FreeBSD 11.1-RELEASE-p10 (Clang)
CPU: AMD FX-8370 Eight-Core Processor (4013.68-MHz K8-class CPU)
fx-freebsd ➜ memcpy_sse git:(master) ✗ for src in testmem_cputime*.c; do
echo "${src} (64-bit)"
echo "---------------"
cc -O3 -march=native -m64 ${src} -o tm64
for i in $(seq 10); do ./tm64 32; done
echo "${src} (32-bit)"
echo "---------------"
cc -O3 -march=native -m32 ${src} -o tm32
for i in $(seq 10); do ./tm32 32; done
done
Results
testmem_cputime.c (64-bit)
32 MB = 9.364038 ms
-Compare match (should be zero): 0
32 MB = 9.469106 ms
-Compare match (should be zero): 0
32 MB = 9.737254 ms
-Compare match (should be zero): 0
32 MB = 9.648358 ms
-Compare match (should be zero): 0
32 MB = 9.649680 ms
-Compare match (should be zero): 0
32 MB = 9.740510 ms
-Compare match (should be zero): 0
32 MB = 9.662104 ms
-Compare match (should be zero): 0
32 MB = 9.837167 ms
-Compare match (should be zero): 0
32 MB = 9.789955 ms
-Compare match (should be zero): 0
32 MB = 9.747930 ms
-Compare match (should be zero): 0
testmem_cputime.c (32-bit)
32 MB = 9.453690 ms
-Compare match (should be zero): 0
32 MB = 9.738267 ms
-Compare match (should be zero): 0
32 MB = 9.645654 ms
-Compare match (should be zero): 0
32 MB = 9.653027 ms
-Compare match (should be zero): 0
32 MB = 9.742734 ms
-Compare match (should be zero): 0
32 MB = 10.306901 ms
-Compare match (should be zero): 0
32 MB = 9.746101 ms
-Compare match (should be zero): 0
32 MB = 9.655098 ms
-Compare match (should be zero): 0
32 MB = 9.553641 ms
-Compare match (should be zero): 0
32 MB = 9.412613 ms
-Compare match (should be zero): 0
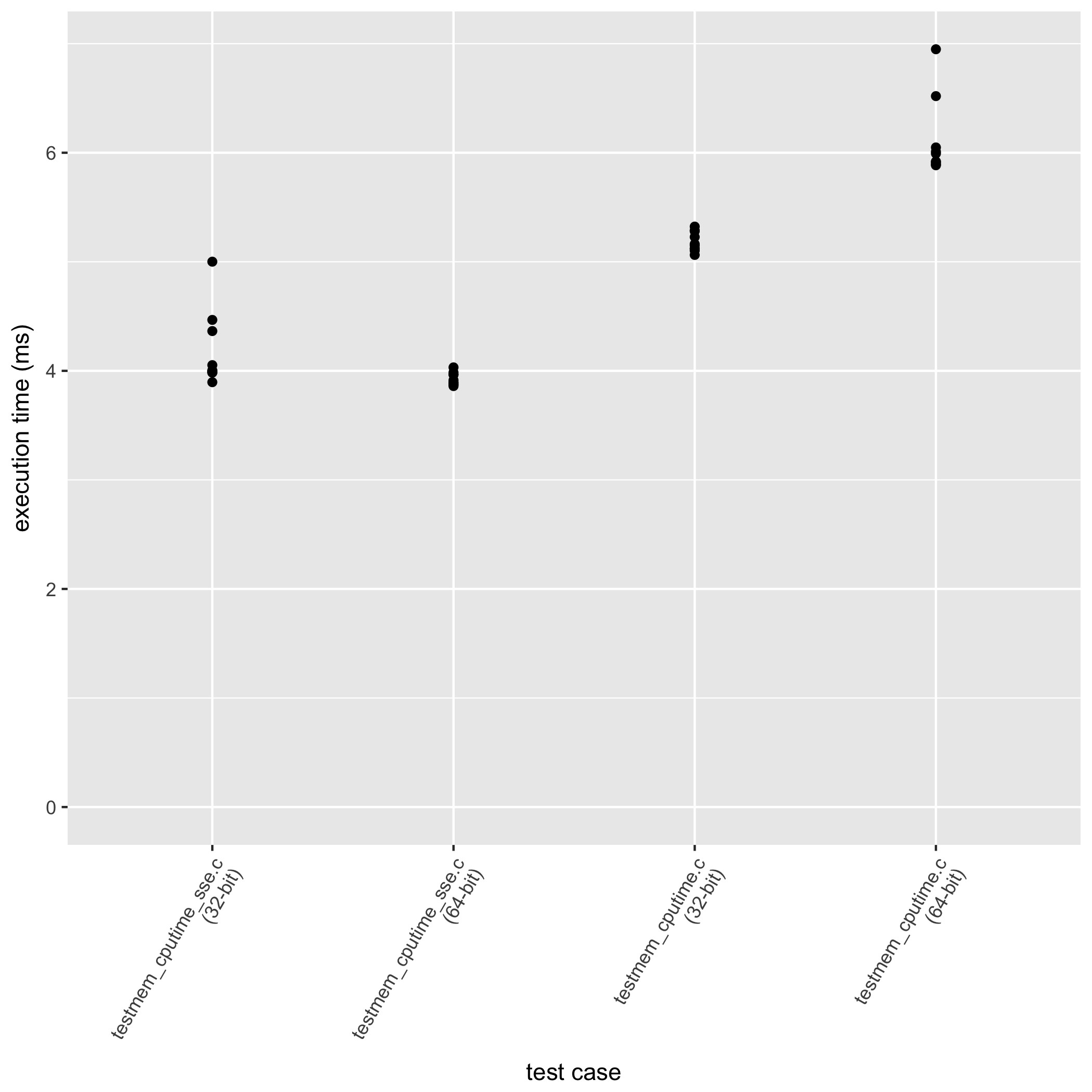
testmem_cputime_sse.c (64-bit)
32 MB = 5.203243 ms
-Compare match (should be zero): 0
32 MB = 5.205019 ms
-Compare match (should be zero): 0
32 MB = 5.373679 ms
-Compare match (should be zero): 0
32 MB = 5.184111 ms
-Compare match (should be zero): 0
32 MB = 5.114539 ms
-Compare match (should be zero): 0
32 MB = 5.110372 ms
-Compare match (should be zero): 0
32 MB = 5.109356 ms
-Compare match (should be zero): 0
32 MB = 5.109775 ms
-Compare match (should be zero): 0
32 MB = 4.921534 ms
-Compare match (should be zero): 0
32 MB = 5.119770 ms
-Compare match (should be zero): 0
testmem_cputime_sse.c (32-bit)
32 MB = 5.210353 ms
-Compare match (should be zero): 0
32 MB = 5.206656 ms
-Compare match (should be zero): 0
32 MB = 5.395012 ms
-Compare match (should be zero): 0
32 MB = 5.113557 ms
-Compare match (should be zero): 0
32 MB = 5.204370 ms
-Compare match (should be zero): 0
32 MB = 5.305252 ms
-Compare match (should be zero): 0
32 MB = 5.218168 ms
-Compare match (should be zero): 0
32 MB = 5.209056 ms
-Compare match (should be zero): 0
32 MB = 5.298002 ms
-Compare match (should be zero): 0
32 MB = 5.203724 ms
-Compare match (should be zero): 0
macOS 10.13.4 (Clang)
Intel® Core™ i7-6700HQ CPU @ 2.60GHz
i7-macos ➜ memcpy_sse git:(master) ✗ for src in testmem_cputime*.c; do
echo "${src} (64-bit)"
echo "---------------"
cc -O3 -march=native -m64 ${src} -o tm64
for i in $(seq 10); do ./tm64 32; done
echo "${src} (32-bit)"
echo "---------------"
cc -O3 -march=native -m32 ${src} -o tm32
for i in $(seq 10); do ./tm32 32; done
done
Results
testmem_cputime.c (64-bit)
32 MB = 6.048658 ms
-Compare match (should be zero): 0
32 MB = 5.885129 ms
-Compare match (should be zero): 0
32 MB = 6.949056 ms
-Compare match (should be zero): 0
32 MB = 6.519306 ms
-Compare match (should be zero): 0
32 MB = 5.916329 ms
-Compare match (should be zero): 0
32 MB = 5.919647 ms
-Compare match (should be zero): 0
32 MB = 6.008809 ms
-Compare match (should be zero): 0
32 MB = 5.992583 ms
-Compare match (should be zero): 0
32 MB = 5.890260 ms
-Compare match (should be zero): 0
32 MB = 5.900751 ms
-Compare match (should be zero): 0
testmem_cputime.c (32-bit)
32 MB = 5.162855 ms
-Compare match (should be zero): 0
32 MB = 5.062851 ms
-Compare match (should be zero): 0
32 MB = 5.122910 ms
-Compare match (should be zero): 0
32 MB = 5.227316 ms
-Compare match (should be zero): 0
32 MB = 5.102281 ms
-Compare match (should be zero): 0
32 MB = 5.117700 ms
-Compare match (should be zero): 0
32 MB = 5.322892 ms
-Compare match (should be zero): 0
32 MB = 5.150164 ms
-Compare match (should be zero): 0
32 MB = 5.280897 ms
-Compare match (should be zero): 0
32 MB = 5.287386 ms
-Compare match (should be zero): 0
testmem_cputime_sse.c (64-bit)
32 MB = 4.031928 ms
-Compare match (should be zero): 0
32 MB = 3.895115 ms
-Compare match (should be zero): 0
32 MB = 3.913997 ms
-Compare match (should be zero): 0
32 MB = 3.871658 ms
-Compare match (should be zero): 0
32 MB = 3.965120 ms
-Compare match (should be zero): 0
32 MB = 3.860322 ms
-Compare match (should be zero): 0
32 MB = 3.876988 ms
-Compare match (should be zero): 0
32 MB = 3.967155 ms
-Compare match (should be zero): 0
32 MB = 3.985467 ms
-Compare match (should be zero): 0
32 MB = 3.888782 ms
-Compare match (should be zero): 0
testmem_cputime_sse.c (32-bit)
32 MB = 4.000218 ms
-Compare match (should be zero): 0
32 MB = 3.992098 ms
-Compare match (should be zero): 0
32 MB = 3.983450 ms
-Compare match (should be zero): 0
32 MB = 3.985040 ms
-Compare match (should be zero): 0
32 MB = 3.895962 ms
-Compare match (should be zero): 0
32 MB = 4.052533 ms
-Compare match (should be zero): 0
32 MB = 4.364831 ms
-Compare match (should be zero): 0
32 MB = 4.003279 ms
-Compare match (should be zero): 0
32 MB = 4.467057 ms
-Compare match (should be zero): 0
32 MB = 5.001040 ms
-Compare match (should be zero): 0
FreeBSD 11.2-BETA2 (Clang)
CPU: Intel® Xeon® CPU E3-1275 v3 @ 3.50GHz (3491.98-MHz K8-class CPU
xeon-freebsd ➜ memcpy_sse git:(master) ✗ for src in testmem_cputime*.c; do
echo "${src} (64-bit)"
echo "---------------"
cc -O3 -march=native -m64 ${src} -o tm64
for i in $(seq 10); do ./tm64 32; done
echo "${src} (32-bit)"
echo "---------------"
cc -O3 -march=native -m32 ${src} -o tm32
for i in $(seq 10); do ./tm32 32; done
done
Results
testmem_cputime_sse.c (64-bit)
32 MB = 5.397115 ms
-Compare match (should be zero): 0
32 MB = 5.396561 ms
-Compare match (should be zero): 0
32 MB = 5.679435 ms
-Compare match (should be zero): 0
32 MB = 5.492458 ms
-Compare match (should be zero): 0
32 MB = 5.461031 ms
-Compare match (should be zero): 0
32 MB = 5.338261 ms
-Compare match (should be zero): 0
32 MB = 5.489692 ms
-Compare match (should be zero): 0
32 MB = 5.398943 ms
-Compare match (should be zero): 0
32 MB = 5.487649 ms
-Compare match (should be zero): 0
32 MB = 5.498127 ms
-Compare match (should be zero): 0
testmem_cputime_sse.c (32-bit)
32 MB = 5.586349 ms
-Compare match (should be zero): 0
32 MB = 5.398066 ms
-Compare match (should be zero): 0
32 MB = 5.399075 ms
-Compare match (should be zero): 0
32 MB = 5.394996 ms
-Compare match (should be zero): 0
32 MB = 5.582423 ms
-Compare match (should be zero): 0
32 MB = 5.516856 ms
-Compare match (should be zero): 0
32 MB = 5.777014 ms
-Compare match (should be zero): 0
32 MB = 5.403728 ms
-Compare match (should be zero): 0
32 MB = 5.405563 ms
-Compare match (should be zero): 0
32 MB = 5.398723 ms
-Compare match (should be zero): 0
testmem_cputime.c (64-bit)
32 MB = 3.977475 ms
-Compare match (should be zero): 0
32 MB = 3.976020 ms
-Compare match (should be zero): 0
32 MB = 4.095995 ms
-Compare match (should be zero): 0
32 MB = 3.886303 ms
-Compare match (should be zero): 0
32 MB = 3.888495 ms
-Compare match (should be zero): 0
32 MB = 3.982998 ms
-Compare match (should be zero): 0
32 MB = 3.883676 ms
-Compare match (should be zero): 0
32 MB = 3.929006 ms
-Compare match (should be zero): 0
32 MB = 4.082254 ms
-Compare match (should be zero): 0
32 MB = 4.077366 ms
-Compare match (should be zero): 0
testmem_cputime.c (32-bit)
32 MB = 3.887418 ms
-Compare match (should be zero): 0
32 MB = 3.978700 ms
-Compare match (should be zero): 0
32 MB = 3.978148 ms
-Compare match (should be zero): 0
32 MB = 4.162944 ms
-Compare match (should be zero): 0
32 MB = 4.218827 ms
-Compare match (should be zero): 0
32 MB = 4.071517 ms
-Compare match (should be zero): 0
32 MB = 4.266001 ms
-Compare match (should be zero): 0
32 MB = 4.173596 ms
-Compare match (should be zero): 0
32 MB = 4.303510 ms
-Compare match (should be zero): 0
32 MB = 3.973035 ms
-Compare match (should be zero): 0