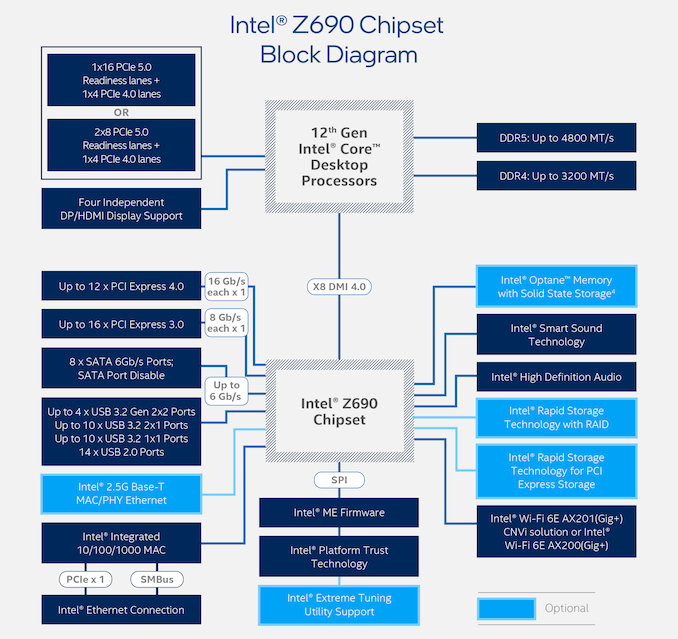
An Alder Lake cpu and the Z690 chipset talk through DMI 4.0 at PCIe 4.0 x8 speeds.
Or about 16 GB/s.
my 3 NVMe drives can achieve 7 GB/s each. The mobo and chipset can provide the slots and lanes.
Thats about 21 GB/s, or 5 GB/s over budget.
So, if I don’t want the bottleneck my thought is to only use 2 of the m.2/NVMe drives on the chipset, which could allow about 2 GB/s of headroom for all the other DMI duty. Right?
Check the documentation, but you are on to something.
You are right that The CPU only has a certain number of PCI lanes available, split between the chipset, and the rest of the bus.
Not only would the chipset constrain the number of lanes available for each M.2 socket, but it might also hold back a lane for USB connectivity and other stuff.
Perhaps a topographical chart block diagram would help.
Also, there may be a constrained number of lanes available for the sockets, like 16 for example, so if one populated a x16, and x8 and an x8 socket, the motherboard would decide how many lanes to activate for each slot.
So too many devices definitely do get constrained. But, NVME devices are still Very fast, so you might only notice during artificial tests, and particular transfers.
I would see if there is a block diagram like this:
No one talked about " all the time". But pulling a 100G file, backup, running scrub, whatever is severely bottlenecked by the chipset, which is a design flaw. And there are potential x4 or x8 chipset PCIe slots on that board with a GPU or 100Gbit NIC demanding bandwidth via chipset as well.
You may be fine with HDDs and 640k of memory, but if I buy a board with PCIe 4.0 NVMe slots, I expect to get PCIe 4.0 performance.
chipset bottlenecks and the lack of PCIe lanes on consumer boards is so anti-consumer and anti-expansion. And both Intel and AMD can’t be bothered changing this anytime soon.
The good kind of approach is giving all NVMe drives their own 4 CPU lanes for guaranteed bandwidth.
Doesn’t the motherboard also assign all the lanes at boot? So if each drive has only 2 lanes assigned, each will be bottlenecked, regardless of the other drives activity?
I mean, I heard PCIe was supposed to be “hot swap” able, but also looks like all the lanes get divided at the start
They all run on 4 lanes. Chipsets can have basically infinite amount of lanes. The problem is the connection CPU <-> chipset which is 8x 4.0 (or 4x 4.0 with X570).
16 CPU lanes for the (only) GPU slot and 8 for the chipset (or 4 for chipset + 4 for nvme/x4 slot. That’s the status quo in consumer land past, present and future.
Z690 has extra 4 lanes for a single NVMe at 4.0 speed (which is some progress I guess?)
edit: If you got 4 nvme slots, you probably RAID them. And you will have problems with chipset bandwidth and even more serious problems if you dare to plug some non-sound card into that PCIe chipset slot.
Totally agree that use case specifics will point towards workstation/server builds. I have those machines where “most” work gets done.
This dialog here is super helpful. Thanks gang
So, I’m building a consumer platform that is going to get more play than work, but it is going to do some work… and I don’t want to leave bandwidth/potential on the table, but I REALLY don’t want to overdo it with components that “could” get bottlenecked.
Knowing when and how the bottlenecks occur is necessary in that case. And you guys confirmed that already.
There is the option on using bifurcation on the x16 slot, running the GPU at x8 (I heard the upcoming PCIe 5.0 GPUs might only use PCIe 5.0 x8).
This frees 8 lanes to be freely used for everything. You can run e.g. 2x NVMe there or other high bandwidth stuff like GPU, HBA or NIC. And then using a NVMe via chipset is much more manageable, but >2 NVMe SSD via chipset is just madness.
On EPYC, there is only CPU lanes, 128 of them. And Threadripper Pro has a chipset, but it is far from being as overbooked as consumer chipsets and you got 7 full slots anyway. But price delta is real and you need deep pockets for proper/guaranteed bandwidth.
While one wouldn’t be living in the 1980s (640k of mem), it’s also not reasonable to assume an average consumer having a 100GbE NIC in the near future. NBASE-T barely took off and there really isn’t anything that demands 100Gb/s of bandwidth in the consumer space.
I can see 10GbE or 25GbE in high end workstations for direct connections to NASes, but beyond that it’s really niche use case.
I too, would like 40 CPU PCIe lanes on the cheap (read: consumer platform), but as you’ve said that’s not happening anytime soon. 24 lanes is all we get and I don’t think the niche market (L1/STH) is big enough to change that.
Exactly, and that happens to be the kind of work I do. The nature of my work is massive data transfers and translation… processes that take days and weeks, not minutes and hours. My network is 25 gbe today, but will be 100 gbe whenever ubiquiti offers a device.
The lions share of the work is running on servers and workstations, but I can (and will) test and prep work things on this 12900K while the server and workstation are crunching away. My gaming rig is going out to pasture… so this 12900K is a gaming rig that can do some small scale workstation duties when needed.
I agree. But promising your customers “up to 12x USB 3.2” + 4x NVMe SSD+ 3x PCIe x16 slots is just borderline lying because it doesn’t work if you use more than 1/3 of it at the same time. Only on enterprise stuff you actually see the fine print, otherwise it is 99% intransparent sales jargon for consumers.
And we’re at the point where a good Z690 board costs as much as a baseline EPYC/Xeon board. Market segmentation is a bitch and we’re paying for it. FCK duopoly.
I totally get what @Exard3k is driving at, but the market is segmented in a way where if you require such I/O, consumer platforms just isn’t going to cut it unless you’re willing to accept the shortcomings.
Consumer platforms are designed for the average consumer, and in that sense it’s not a design flaw that a Z690/X570 chipset will bottleneck a 100GbE NIC, because such a use case falls under the traditional workstation/server market segment.
Well, it is. Someone up there figured they can milk 1 to 2 thousand from your joe blow gamer and I guess 24 lanes now cost 1 to 2 thousand (for a full system). If NVMe storage gets cheaper and workloads that can regularly saturate the PCIe bus exists then we might see more PCIe lanes for joe blow gamer…
As it stands if the average gamer won’t come close to even hitting the I/O limits, I guess it’s fine to lie and oversell their shit, which is exactly what ISPs are doing for consumer internet.
Corporations are just trying to maximise their profits while spending the least amount of money, min max. Sucks but it is what it is, and I guess I’m living the rest of my life getting milked.
You need to step up to a workstation class board for workstation tasks. If this is what you want look at a HEDT platform or a server. Or a PCIe card you can put into a x8 slot. The consumer platforms are cost compromise aimed at consumer grade tasks. If you’re planning to push multiple m.2 drives concurrently then you need to pick an appropriate platform.
The way they’re hook-up is 100% fine for the intended use case - multiple drives that are used individually.