A lot of “housekeeping”-tasks a CPU sees are accelerated on a hardware level anyway.
Depending on your file server OS, either ZFS, BTRFS or ReFS exist already and solve the problems mentioned in the LTT video.
In case one is doing weird things to data going to storage, there are devices to take that load off the CPU in case that is actually a problem.
I may be wrong, but I learned that one server does one task (except for VM servers). So the file server CPU running at 80% during peak hours is fine since it is literally doing its job.
well, pcie is duplex so 32g in/32g out could be a thing.
And with iommu/direct storage it is possible for a pcie device to just talk directly to the block devices, which is what I initially thought was happening here.
I thought, why a GPU and not a network card… because these days NICs speak NVMe and do checksums and error correction and compression and encryption… so I searched for ZFS eBPF, ZFS XDP
Microsoft recently deprecated hardware accelerated offload for NICs (as in, their OS no longer uses it, never mind what the hardware CAN do) so i wouldn’t bet on that horse for much longer. You might be fine for current/old hardware but…
aside…
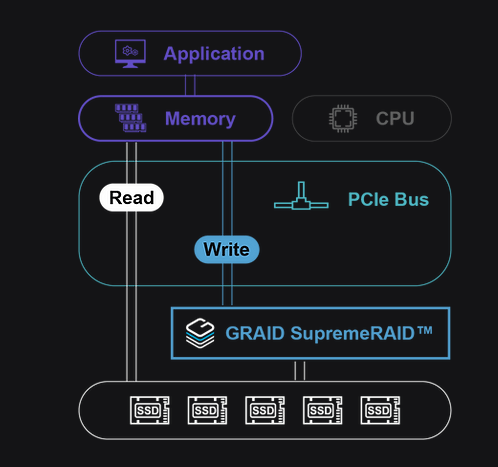
IF this g-raid stuff works, i will bet my house that it will be a very short term niche; there’s no way for a GPU to properly calculate parity without being fed the data to do the parity calc on, and unless you’re using a bunch of GPUs for this you’re limited to one slot worth of bandwidth.
And where is the data generally coming from? The CPU via the running OS’s application or network driver, etc.
Sticking a GPU in path just seems like a step backward.
There’s this AF_KTLS thing and with Mellanox it’ll do AES-128/256-GCM
It looks like an easy small localized patch to nginx or grpc would allow offloading – if you support AF_INET and AF_UNIX then surely AF_KTLS wouldn’t be much of a stretch.
I really don’t have a need for a 400Gbps Mellanox cx-7 at home to test (also, these are dual slot PCI-E 5.0 cards / 32 lanes each, pretty brutal).
How is 32 GB/s in one direction possible with a PCIe Gen3 x16 GPU (the T1000 used in the LTT video) or did you mean theoretically with a state-of-the-art Gen4 GPU?
Or is there a way to switch PCIe connections to half-duplex doubling the bandswith in one direction?
Xilinx has a range of “smart NICs” (huge FPGA with network ports) and in cooperation with Samsung, compute and storage in one package.
So some workload out there benefits a lot from having processing to a data stream with the CPU just pulling the strings.
Main difference to the rebranded T1000 there, the Xilinx offerings have insane memory bandwidth (and in some cases 64GB RAM on board).
Just got around to watching this. I believe I got how it works on a high level, but I cannot comprehend the graphs, or understand how it works at a low level.
Supposedly the only thing that goes into the GPU is the parity data. The read and writes happen in the system memory and the GPU only does parity calculation. But I’m really confused as to how the GPU can do a parity calculation and compute a checksum without reading the storage blocks. We’ve seen the supposed numbers, 25 GB/s on RAID5.
I don’t like magic, and there’s definitely magic happening here. As others mentioned in previous comments, the T1000 is a PCI-E gen3 card and can only do 16 GB/s, but we’ve seen higher throughput than that. I believe what may be happening is that data is cached in RAM and parity is done later and it’s using some form of async writes, basically cheating. They did have a 1TB RAM pool, so I wonder how the system would perform to write a 500 GB file using a 128 GB RAM pool. Their dashboard said that RAM was at 0.8% utilization, so out of 1000GB, that would be like 8GB used. I think the cached memory is not being shown, I do not trust that graph, it’s likely that it’s only shown used and not buff/cached mem.
And the sad part is, as Wendell mentioned, is that it’s not using the PCI-E to talk directly to the block devices, so the GPU is using the system memory as a middleman.
To be honest, the idea is not bad. I wonder how well an integrated GPU would have worked for this kind of task, kinda like Intel Quick Sync accelerates video encoding and decoding, but instead using Heterogeneous System Architecture (HSA), if AMD and co. didn’t kill it off (the HSA Foundation didn’t have a commit over on their git page since December 2020). hUMA would have sped this compute task further, by not having to copy data from main memory to the VRAM. We will never know, HSA is not even present on AMD’s Technologies webpage anymore. Sorry for the off-topic rant about HSA.
Writes: in raid5 are 10GB/s (in LTT video), this is less than 16GB/s PCIe 3.0 x16 lane limit. In their test, you get about 1GB/s of parity data as a result. PCIe is full duplex, so if you did 15GB/s of data → 4GB/s parity with a different raid scheme – that shouldn’t be problem.
Reads: in raid5 from video are 25GB/s - obviously doesn’t fit into GPU. For raid5, you don’t need parity at all (most of the time). You need data, and some way of knowing the data is good. You could achieve data integrity either by reading parity and comparing (waste of i/o) or by recomputing hashes of data. Generally, you can get 10-20GB/s of hash computed per core with popular algorithms like crc32/spooky/murmur/cityhash/…
Computing hashes is more CPU intensive than computing parity, but less i/o intensive, and arguably more useful for data integrity overall as it helps with the raid write hole problem.
The thing is, to calculate parity, you need to sum up the bits, which means… needing the bits to calculate the parity.
Even if this works, I feel that we have plenty of CPU cores to handle this now, and the CPU has more bandwidth available between it and NVME than the GPU does.
Additionally, as above hashes are more useful as they give you things like deduplication capability (if you can store an index of the hashes, see a hash match = same data) in addition to error checking. And modern CPUs can hash real fast for crypto…
I just don’t see GPUs being a long term fit for this. What I can see is any CPU deficiency this is “fixing” being implemented in the CPU/chipset within a generation.
A lot of people seem to say that there is no real world benefit of GRAID, but in this review there is a significant performance improvement over mdadm in raid 5. They measured: read, write and IOPS; all with improved performance.
Many are saying that reads are improved, because it does not calculate the parity, but that would not explain why the write performance is so much higher.
Some are guessing it hasn’t actually written the data to disk, but that it is in (ram) cache, but there are not many tests or other evidence to know what is going on.
I would love to see some kinda of a deep dive or something that goes over the pros and cons of GRAID vs other raid with some examples and tests. @wendell for example in a level1techs video .
What I’d be curious to know is if pinning the NVME IO to a particular CPU core (or CCX/die/etc.) would help.
In these CLI only server machines the GPU is doing literally nothing (whereas the CPU(s) are being hit with interrupts, background tasks, etc.), and thus it is free of scheduling hiccups which could perhaps interfere with streaming data to/from the NVME.
 (also, these are dual slot PCI-E 5.0 cards / 32 lanes each, pretty brutal).
(also, these are dual slot PCI-E 5.0 cards / 32 lanes each, pretty brutal).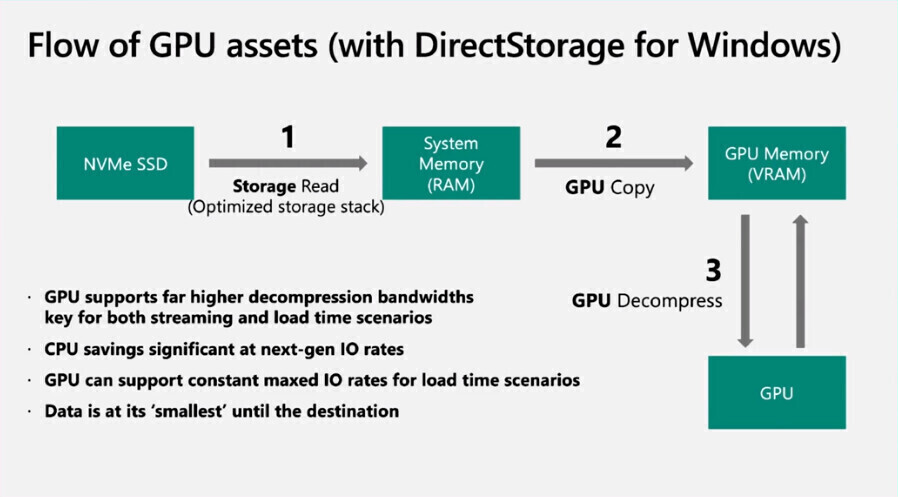
 .
.

