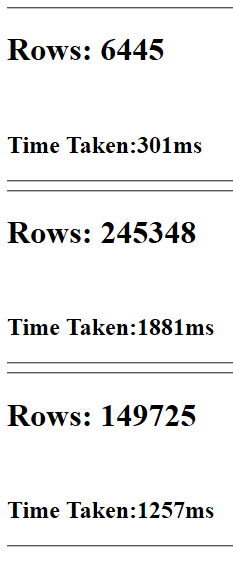
Okay, so considering the amount of data that these queries get back, it’s not too bad, but I need this application to be lightning fast, and I’m not sure how I can improve the performance even further, everything I’ve tried just slows it down a little more. I mean each query needs to be able to execute in under a second, if possible.
Source Code
Query1
WITH bp AS (
SELECT DISTINCT n, price, c, i, ps
FROM pttbl p
INNER JOIN sttbl AS s
ON s.alias = p.i
WHERE p.a = 1
AND p.price > 1
AND p.ps NOT LIKE '%se%'
AND p.pt = 1
AND s.stat = 'AVAIL'
)
SELECT DISTINCT c, i, img, n, price, ps
FROM bp
INNER JOIN (
SELECT DISTINCT * FROM (
SELECT DISTINCT img, pc,
ROW_NUMBER() OVER (PARTITION BY pc ORDER BY so ASC) RN
FROM pitbl
WHERE img != 'NoImage'
) AS imgsn
WHERE imgsn.RN = 1
) AS imgs
ON bp.c = imgs.pc
Query 2
WITH pats AS (
SELECT DISTINCT v AS sv, pc, k
FROM patbl
),
aks AS (
SELECT DISTINCT dn, ID
FROM aktbl
)
SELECT DISTINCT *
FROM pats
INNER JOIN aks
ON pats.k = aks.ID
Query 3 (QoQ)
SELECT Q1.c, Q1.sv, Q1.k, Q1.dn
FROM Q2, Q1
WHERE Q2.c = Q1.c
Yes, that is the number of rows returned for each query.
And no, that number will be dramatically reduced when in production.
I’m just trying my best to make these queries as fast as possible, purely because the page(s) that these queries will be put on, they’re pretty slow as it is, and I don’t want to make them any slower than what needs be.
Additionally, with query 3, for some bizzar reason, it executes in what appears to be constant time, it’ll take the same amount of time to execute and return data if you return 1 row or 100k rows. I personally find that a bit wtf worthy? …
Yeah, for #3 the database is probably creating the same joined temporary table every time you run the query, irrespective of how many rows you want.
Also, I would suspect the DISTINCT keyword would slow down the queries, as the DB has to check for duplicates.
Can you really need this? Are you getting duplicates? Can you handle this on insert or something?
It looks to me you are getting the DB to do quite a bit of work. Redesigning the queries/tables/program would make that faster. I.e. storing the data in the way you want to access it. I don’t know what the proper enterprise conventions are, I am just some chump on the internet who has dabbled a bit in sql.
You also might want to check https://stackoverflow.com/ there are some db wizards on here if you have no joy here.
If I recall correctly, I did try removing the key word distinct, and it did cause some invalid data to occur. However, even when I removed it, I can assure you that it caused no performance increase. I mean I’ve tested that multiple times, on both queries, I mean at first, for the first time I ran it, there was 100ms difference, and I was like yay… But then I ran it about 5 times, the remaining 4 times, it was slower than the average speed with the keyword distinct included.
In all fairness to your suggestion of removing the keyword distinct, I thought that would make a fair difference too, but apparently, it makes no difference what so ever from a performance perspective.
As for number 3, can you think of a better way to write that?
Like you said, if I don’t get anything on here, then I’ll resort to StackOverflow, I didn’t go there first because I thought I’d try here first.
I am wondering if some part of the delay is transmitting the volume of data.
Your DB could be running on a super computer, but if you are connected to that via 56k modem, it can take a while to get the data. Also, if you have a high latency connection, and you perform many db calls, each call has a time cost associated with it. Finally, if the db is on a slower computer, it will be slower when running the queries.
Also, I can’t really improve on #3. I am at the limit of what little advice I can offer. Best ask someone who does this for a living!
So I’m more of a SQL noob than ArgGrr and you’ll probably laugh at my code buuuut I’m trying to get gud at SQL so I thought I’d give it a try. For query 2 would SELECT DISTINCT sv, pc, k, dn, ID FROM patbl, aktbl WHERE k = ID
Work? I assumed you don’t need to create and inner join the tables pats & aks.
And for query 3 would SELECT c, sv, k, dn FROM q1
Work? It looked like you were only selecting values from table q1 but required q2 to be searched and then have its q2.c value be matched with the q1.c value of every single row that is created from that query.
I assumed you had a logical reason for structuring your queries the way you did and my answers don’t fulfill the required output requirements you have but I thought id pipe in.
I am not an SQL expert but I deal with it every day.
I see two issues.
1.) As mentioned, you have SQL doing a lot of heavy lifting on data retrieval when you should really be doing this on data insert. If you know that you do not want duplicates, you need to ensure that you have the constraints set on the table to discard or replace them on data insert. You may want to look at better table DB normalization as well as you are joining a lot and probably returning duplicate data stored in columns of each joined table. This is a big performance suck, data waster, and over all bad practice.
2.) Is there a specific reason why you are using so many nested queries?. This is another performance suck which could be better handled by carrying out the above point and better shaping your data so that you can use the logic built into SQL to handle the best way to retrieve your data. Think about you queries as Vin Diagrams. You are working from less specific to more specific. This does not allow SQL to exercise Data Acquisition plans which are smarter than you and I will ever be.
Lastly, your last query is in fact an O(n) function as you are always carrying out query 1 and 2 in order to retrieve something useful in query 3. If your data set or retrieval parameters change, there is no query execution plan and it will have to start over. This means that it has to go through all of that data linearly each execution. Besides points 1 and 2, indexes may help spead up query 1 and as a result, spead up query 2. Query 3 will still be a linear function, but may not need to wait as long.
Can you rewrite those subselects as joins, it’ll be easier to read.
Also, for readability, instead of distinct, try using group by, or just drop distinct if it’s not necessary.
Also, can you run explain select ... and show us the query plan.
Also, how are you measuring this, does this include connection establishment time or are you using a connection pool?
Reading further, you use row_number + where to get a single random row, containing a product image… , again you can just group by instead and drop the partition stuff
Alright, so I’m going to try and explain how query engines work.
You send some SQL to the server, server parses it the way any programming language would be parsed except SQL is simple and builds an AST … tree-like structure that unambiguously determines what you asked it to do.
It cross checks all the references does some validation that tables exist and so on, and begins compiling your query from the AST into a query plan.
A query plan is a tree of iterators, at root is your query output and formatting, and various database tables are on leaves. Leaves will do things like reading a table that then gets filtered at a later stage, or reading an index where each row triggers a another read perhaps, and so on. In the middle you’ll have iterators that do buffering for distinct, or will do some kind of sorting, or will read from multiple iterators to do a join of some kind.
Then you have your query optimizer pass, it’ll look at the query plan and try to generate an equivalent plan so that the whole thing processes less data in the CPU and uses less IO. It mangles the tree in some way, looks at some number it thinks it’s the overall query cost, looks again, does it again. Eventually it stops and gives you a “query plan”.
This query plan is the final set of how iterators will all be chained/organized together, everything they’ll do and it’s what determines your performance.
You can look at the query plan, and look at what data you have, and say: “hmmmm if I had such and such data in ram and needed to write code to filter it and cross reference it myself using lists and ordered/unordered maps, would I be able to do it smarter”. With good SQL, that matches how the database works, the answer is usually “no, this makes sense, my implementation is would be 2x or 10x faster in wall clock time, but it’s not worth the hassle, and there’s transactions and disk persistence to take care of, and I’m lazy and just need things done”. Sometimes, you look at a query plan and think “wtf that makes no sense, … oh I see, missing index/short table makes sense to buffer”, sometimes you look at the query plan and go “wtf that’s just stupid, looks like optimizer have up and returned garbage, that’s a bug in a database”, and then you file a bug with whoever is your database vendor and the fix comes out 2years later and your product and use case are both dead and have been replaced in the meantime. This happens rarely.
Usually you either fix your schema or your queries, but you always look at the query plan to tell you what’s going wrong, because that’s the closest you can get at what your SQL is doing.
This is one of the reasons redis is so popular, developers get more control over their simple queries cause they can do everything themselves, and simple queries are really really simple and fast. And when things are slow it’s usually the developer was stupid and it’s obvious how they were stupid in that particular instance. With SQL, you get a lot more power, but it’s much more high level and nothing is obvious any more.
I appreciate your input, but as you said, you assume there’s a logical reason behind why I’ve written the 3 queries as I have. You’re spot on. I’ve written them like that because from what I’ve been doing, those speeds are the best so far, and I’ve tried a lot of alternative solutions which returns the same amount of data, but tend to be slower on average.
As for you suggesting the improvement on Q2, I think that would be slower because judging from what a senior developer said about the execution plan, due to the subqueries, it executes those in parallel. Hence why in the image Q1 is so fast, it can’t really get much faster than that unless you cache it. I actually think that the maintenance of the data and the tables has been appalling in the past.
The way in which my company works, we buy out up and coming businesses, and we then make them 100% ecommerce, one website we had to recently do… sigh… All of the static pages were built using tables, anyone that’s even looked into HTML should know that when you structure a page, you should not make it 100% using just tables. That’s a big no no…
And this data which I’m currently working with, it hasn’t had a chance to be 100% performance optimised, due to the fact that our CEO wanted us to put this website live ASAP, so we haven’t had a good chance to play around with it and tweak the hell out of it. I’m sure if we indexed it all as it should be and maintained it even better, then your solution or just a normal inner join with no subqueries probably would improve the performance of q2, if not leave it the same… The fact that for such a simple query, I had to write it like that, it’s insane. Doing a simple solution such as the one you mentioned, it increases the time taken by up to 20, but normally more around 8 times slower. That’s pretty awful.
That’s me in a nutshell, I’ve literally had no experience with SQL prior to my current job role, so it’s been a bit of a fun learning curve.
That’s purely because the current setup I’m working with, our SQL server is a monster, it can handle it, as for our other servers… Honestly, I ran a script which used a built in function… There was nothing complex about it, there was no nested loops or anything like that, yet, it still crashed the server for 5 minutes… All it was doing is writing some data to a .txt file, that it honestly it… I believe it was 1000 rows from a query, and the query wasn’t huge or anything…
Yes, as I’ve mentioned above, when you do things in a NORMAL way, the performance is reduced to a DRAMATIC extent. I mean the performance difference is so much that I’ve recently had a hell of a lot of praise for this discovery. I mean I alone have increased the performance of our dynamic pages by about 8 times the speed. Great for me, because I’m now loved for my queries.
That may be the case, and I believe you totally, honestly, but it’s weird how with 1 row, it will take ~1.5s, yet it takes the same amount of time when you get out 100k+ rows. I personally find that a bit… Odd?.. I mean even if I only get 10 rows from both query 1 and query 2, again, it’ll still take the same amount of time, that’s the only reason why I mentioned it being constant, I didn’t mean it’s constant from a complexity perspective, I just meant that the time taken is always ~1.5s
It’s worth a try, I’ll be sure to give it a go when I’m next in work! - I believe I did try that, but there was 0 performance difference, as for readability, I personally prefer using distinct over group by, like if you have to retrieve a lot of data from a lot of tables, the group by clause can begin to look pretty huge, then it’s just an eyesore.
This part is essential actually, as each product image can have let’s say 20 images, I want to get back just the first image that appears on the product page. And using the same logic, only without the row number, it doesn’t actually work for some reason, me and a senior developer did go through this in a great amount of detail, and this solution, while it’s a bit disgusting, it works as you’d hope.
As for your mentioning with query plans, I’m not actually able to view them myself, I don’t actually have access to the SQL server, annoying as f%$k, I know, you can’t imagine how annoying it gets, writing queries and hoping for the best, half the time I have to harass senior developers asking how the data links up between tables, due to the mismatch of column names, sometimes column names being ultra vague and generic, etc. Although I enjoy writing queries, it does sometimes make me want to skull f$!k myself with a brick.
Like I’ve recently had to write a dynamic query, because of the way in which our data is structured, and a dynamic query is f$!king horrible, I had to create ‘x’ amount of temp tables, and insert ‘z’ amount of data into table ‘x’, as well as ‘y’ amount of data into table ‘x’ on column ‘i’. It really was not fun creating a query like that, I only prey I never have to do something like that again! … Talking about it is giving me PTSD…
I have no intentions of getting bogged down in this thread, becuase with SQL that’s easy to do, especially without sample data, an understanding of the table design, or the query plans… plus I am crap at SQL.
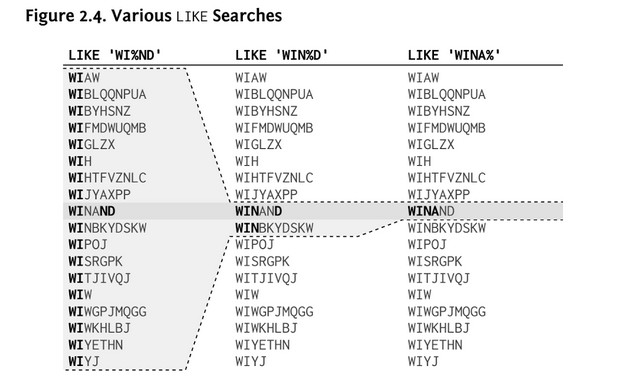
…but, this;
Is not going to work well, a % wildcard at the start of the string means the operation is going to scan all the rows as there is nothing infront of the first % wildcard.
Borrowing a diagram from the rather excellent SQL Performance Explained book by Markus Winnand helps explain this;
If you can’t eliminate the leading wildcard you could likely use a fulltext index - assuming the DB Engine you are using offers one. They all do it differently and have different functions to call it e.g. PostgreSQL is @@ and MySQL is MATCH or AGAINST (iirc).
Suggestions of changing table schema to make a query faster are all well and good, but often completely unworkable in ther real world - the tables might have originally been designed for completely different purposes - as is often the case if you are now performing reporting or analytics on what is an OLTP databases with proper 3rd NF normalisation. Often you just have to suck it up or replicate the data to another DB, cube or stream.
I note that you have chosen to write your queries as CTE’s rather than temp tables, nothing wrong, but depending on your DB Engine you might be able to use global temp tables that persist multiple sessions and can be created with indexes to help speed up searches and cache data.
 …
…