It is 50/50. Usually a scrub deals with small read errors like this. As previously stated I have a CCTV array with a known bad 2TiB drive, it throws errors once every couple of days. FreeNAS eats them for breakfast and the array keeps on trucking. … that said I don’t really care about the data on that array so I live dangerously.
Monitor the drive, if it goes back again then it is failing. If it was just a random screwup then hey, you get a free HGST drive you weren’t expecting!
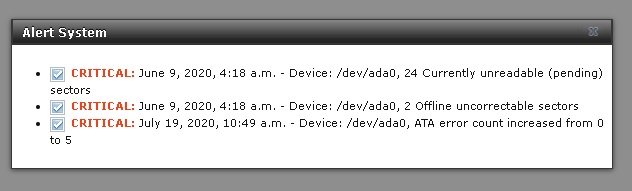
Edit: just 16 re-allocated sectors? I wouldn’t worry until the number is in hundreds, or growing visible, and then try cccleaner again…
Originally I posted:
It might be that the drive did not update its List of bad blocks until the advance format.
Little data errors are normal, and the drive tries to hide them, by marking sectors bad, but doesn’t always know.
Like you said, the drive is now untrustworthy, and will go wrong again down the road.
Thanks folks. I’ve put the drive back in the array and started rebuilding the pool. I’ll monitor the drive weekly see if anything “interesting” happens. I did order a 6TB drive as a spare just in case though.
It’s dying a slow death. You can wait for it to fail completely or replace it pre-emptively. It is possible that it will cause performance and even stability issues as it fails, but it could also be fine for months. Your data should be intact no matter what though.
Not as far as I am aware; scrub checks Data for corruption/bitrot. Whilst checking the data, it might call up a bad sector, which the drive might report as bad to the system, but it does not specifically look for them