Hey guys. So, I’ve been having a problem with my FreeNAS for a while now. The pool has been degraded with Disk 7 showing errors.
Last week I decided to attempt to replace the drive with a spare that I had. I followed some instructions I found in a Youtube video, as i have never had to replace a drive in a ZFS pool before.
Basically the process was:
Go to pool, hit cog button, go to status, select dropdown for drive and hit offline
Shutdown, replace drive, startup
Go back into pool, cog button, dropdown for offline drive, replace, select new drive
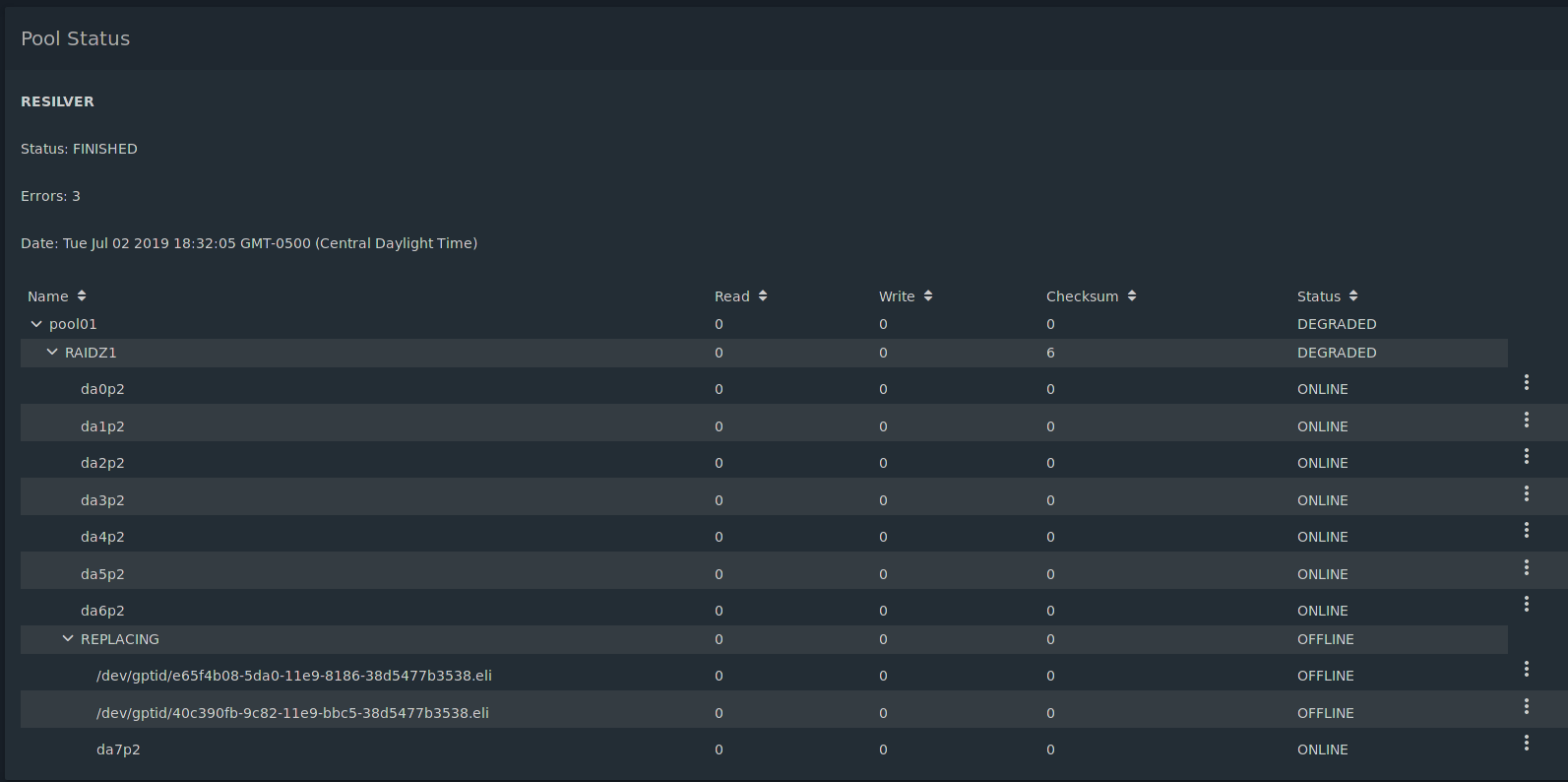
It then spends a lot of time resilvering, but nothing ever happens. The new disk is in the list, but so it the offline failed disk. It never replaces it.
I tried this twice, and now I have two offline failed disks and the new replacement disks.
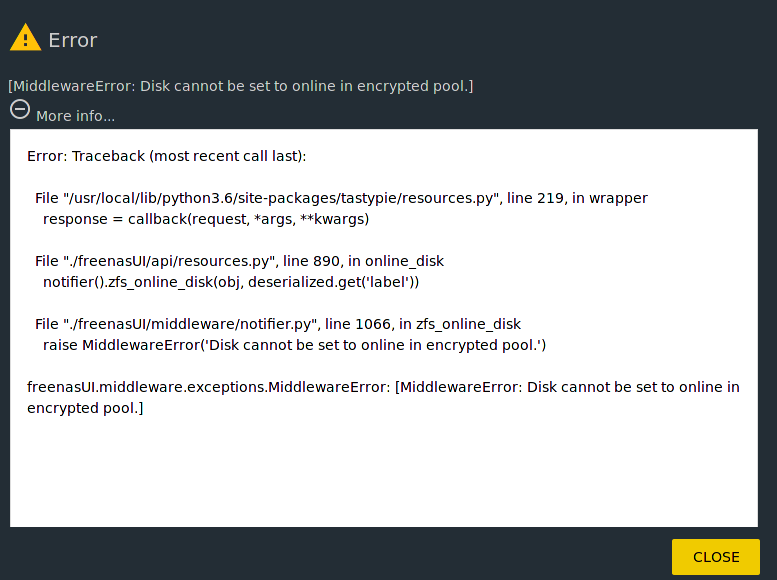
I think this might be happening because the pool is encrypted.
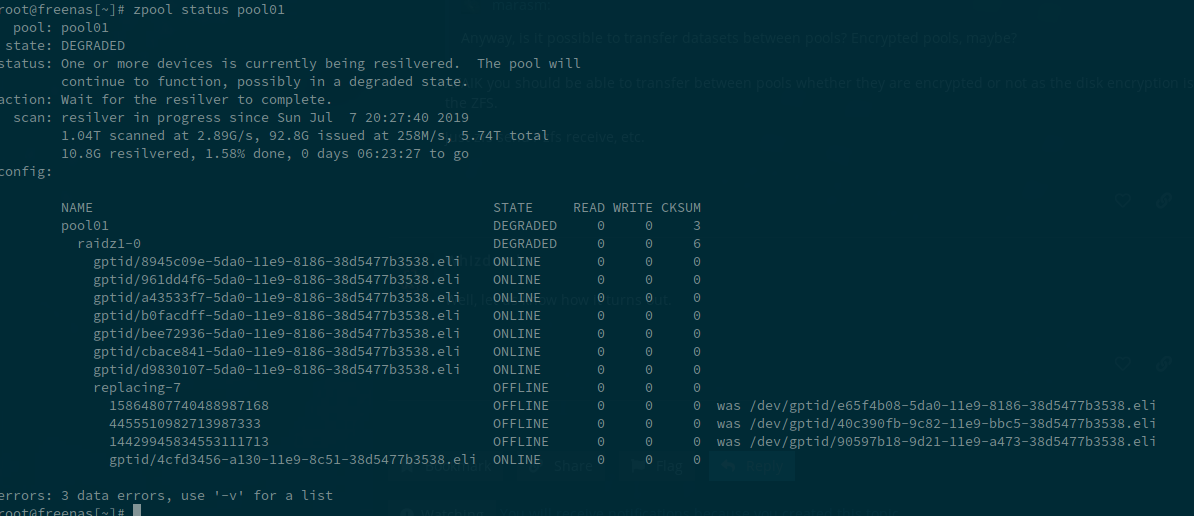
Now, I have been on vacation since Wednesday, and today I got this email from my FreeNAS:
Checking status of zfs pools:
NAME SIZE ALLOC FREE CKPOINT EXPANDSZ FRAG CAP DEDUP HEALTH ALTROOT
freenas-boot 111G 759M 110G - - - 0% 1.00x ONLINE -
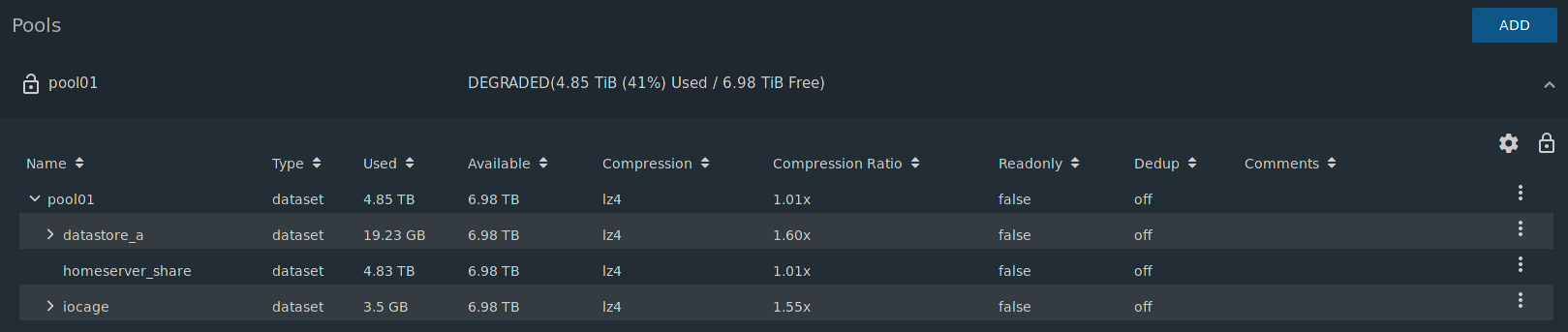
pool01 14.5T 5.74T 8.76T - - 0% 39% 1.00x DEGRADED /mnt
pool: pool01
state: DEGRADED
status: One or more devices has experienced an error resulting in data
corruption. Applications may be affected.
action: Restore the file in question if possible. Otherwise restore the
entire pool from backup.
see: http://illumos.org/msg/ZFS-8000-8A
scan: resilvered 697G in 0 days 06:45:09 with 3 errors on Tue Jul 2 23:17:14 2019
config:
NAME STATE READ WRITE CKSUM
pool01 DEGRADED 0 0 3
raidz1-0 DEGRADED 0 0 6
gptid/8945c09e-5da0-11e9-8186-38d5477b3538.eli ONLINE 0 0 0
gptid/961dd4f6-5da0-11e9-8186-38d5477b3538.eli ONLINE 0 0 0
gptid/a43533f7-5da0-11e9-8186-38d5477b3538.eli ONLINE 0 0 0
gptid/b0facdff-5da0-11e9-8186-38d5477b3538.eli ONLINE 0 0 0
gptid/bee72936-5da0-11e9-8186-38d5477b3538.eli ONLINE 0 0 0
gptid/cbace841-5da0-11e9-8186-38d5477b3538.eli ONLINE 0 0 0
gptid/d9830107-5da0-11e9-8186-38d5477b3538.eli ONLINE 0 0 0
replacing-7 OFFLINE 0 0 0
15864807740488987168 OFFLINE 0 0 0 was /dev/gptid/e65f4b08-5da0-11e9-8186-38d5477b3538.eli
4455510982713987333 OFFLINE 0 0 0 was /dev/gptid/40c390fb-9c82-11e9-bbc5-38d5477b3538.eli
gptid/90597b18-9d21-11e9-a473-38d5477b3538.eli ONLINE 0 0 0
errors: 3 data errors, use '-v' for a list
-- End of daily output --
So, yeah, it’s borked. I have a backup of the data, but I wanted to try to recover this. I’ll be home later today, but I wanted to get this out there to see if anyone can give me a hand in getting this working again.
They are definitely not the correct drives for this use case: 2TB Seagate ST2000DM001. Just regular desktop-class drives. So far I’ve had to replace two in about four years of use. All eight are running through an IT-flashed PERC H310. Someday I’ll get some 4TB NAS rated drives.
The first failure was a couple years ago, and I was running Fedora with ZFS on top of LUKS. Now, with this one, it’s with FreeNAS and I know very little about it or BSD in general.
I think a scrub happens once a week. Or maybe once a day. I’m not sure. I get a ton of emails from FreeNAS with reports.
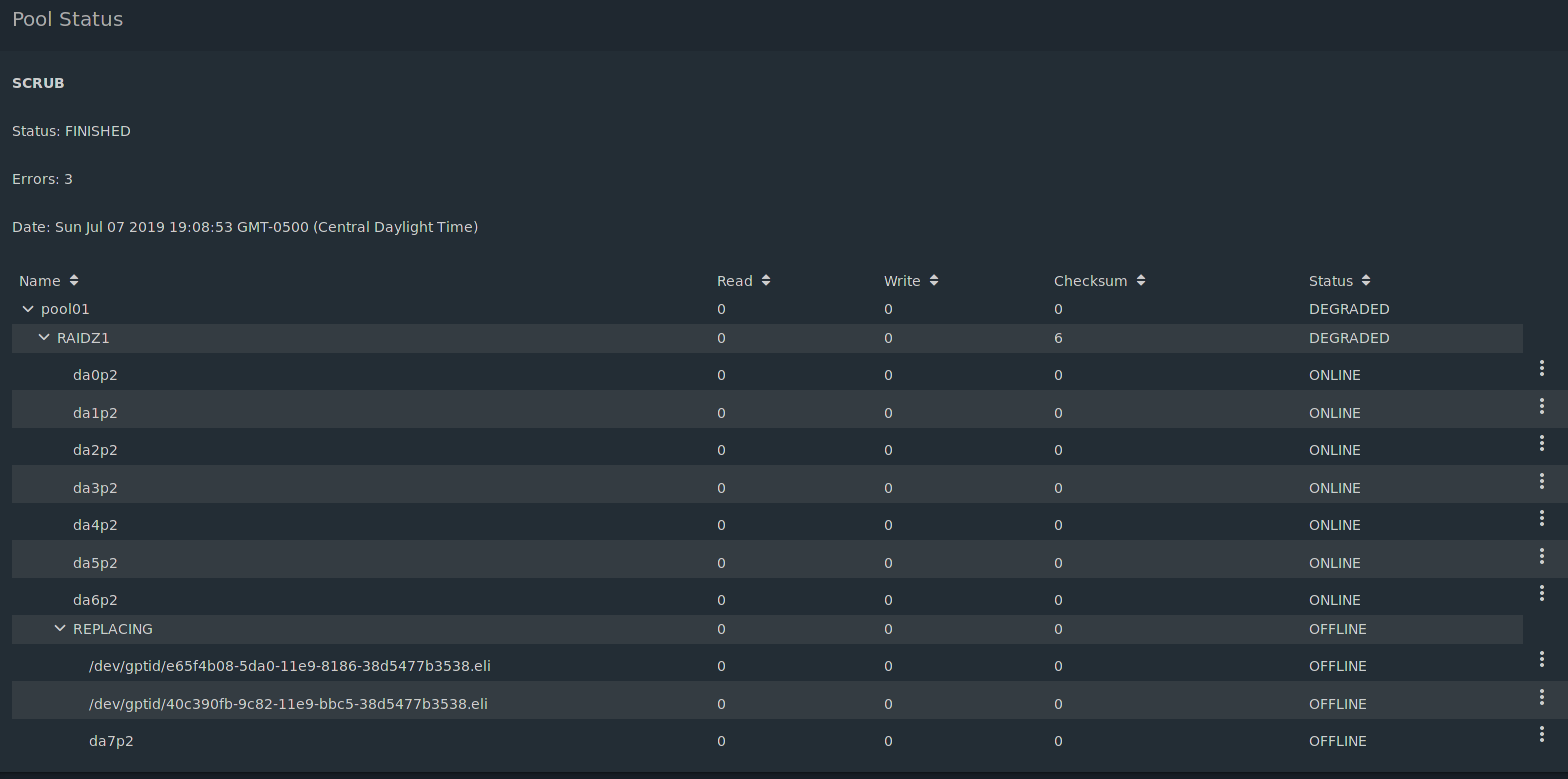
The two /dev/gpid/… entries shouldn’t be there. I tried replacing, it looked like it worked, then it didn’t. Tried again, looked like it was working, then didn’t, and a second /dev/gpid/… appeared.
I have no idea where to go from here. Like I said, the pool is encrypted, and after reboot I have to supply both the passphrase and the keyfile to unlock it. I don’t know if that is what’s causing this or not.
So, after reading the FreeNAS guide (RTFM, right?) I have pretty much come to the conclusion that this thing is hooped. Like, fucked off into low earth orbit, it’s dead Jim, sort of hooped.
Apparently if you don’t this janky rekey thing immediately after hitting replace drive, and then you reboot the system, “access to the pool might be permanently lost.”
I mean, I guess it makes some sense in retrospect. But seriously? That couldn’t be taken care of behind the scenes? No, let’s hope the user knows this.
Anyway. If anyone knows if there’s a way out of this, it’d be great to know.
Otherwise, since the data on the pool is still accessible, I’d like to find a way to transfer two of the datasets to another pool. One has a couple VMs, the other has the jails. Plex, to be specific, which I do not wish to recreate at all costs. That was a nightmare to get working right.
I’ve got four WD RE4 500GB drives I can throw in there and use as a second pool just for the jails and VMs. Can I move the datasets from the degraded pool to the new one?
It looks like all of your disks are still there. 8 Disks are online 0-7 and the resilver process says completed. Make sure you have an offline backup of everything first (which it sounds like you do), attempt to remove the offline disks from the pool with their respective menus, do an encryption rekey on the pool and then export a new recovery key. Hopefully everything appears as normal after that. Whatever you do, don’t power cycle any further until you get this straightened out.
All three disks (the two gpid ones and the actual disk da7) are set as Offline. There isn’t any option to remove the disks. Just Edit, Replace, and Online.
Yeah, it’s pretty terrible. And yes, good that I have a backup. I’m going to have to root around and try to backup the Plex database. The last two or three times I’ve had to set Plex up from scratch because I didn’t get the right files or put them in the right place or something.
Feels like I’m stuck in a loop. If you miss that crucial step that’s buried in the manual in an “oh, by the way” sort of way, you’re hosed. Might be nice to add a warning in the regular disk replacement section for encrypted scenarios.
Anyway, is it possible to transfer datasets between pools? Encrypted pools, maybe?
To be honest, if it’s this much of a hassle to encrypt I might go back to ZoL. The LUKS route worked great, and now ZoL has native encryption. Not sure if I will come across this issue in the future with that.
If you have your geli.key backed up, you can attempt this…
Honestly, at this point, you can try anything if you are confident in your backup. But, as you said, you don’t want to wipe your whole config or screw with any VMs you already have working. So I would attempt anything I could find if it’ll save you that hassle and then just know that worst-case, you might have to start over again.
I’ll wait until the resilver is done. Then I will see if I can truly hotswap by slamming those 500 gig drives in and create a second pool and attempt to move the jails and VMs to that.
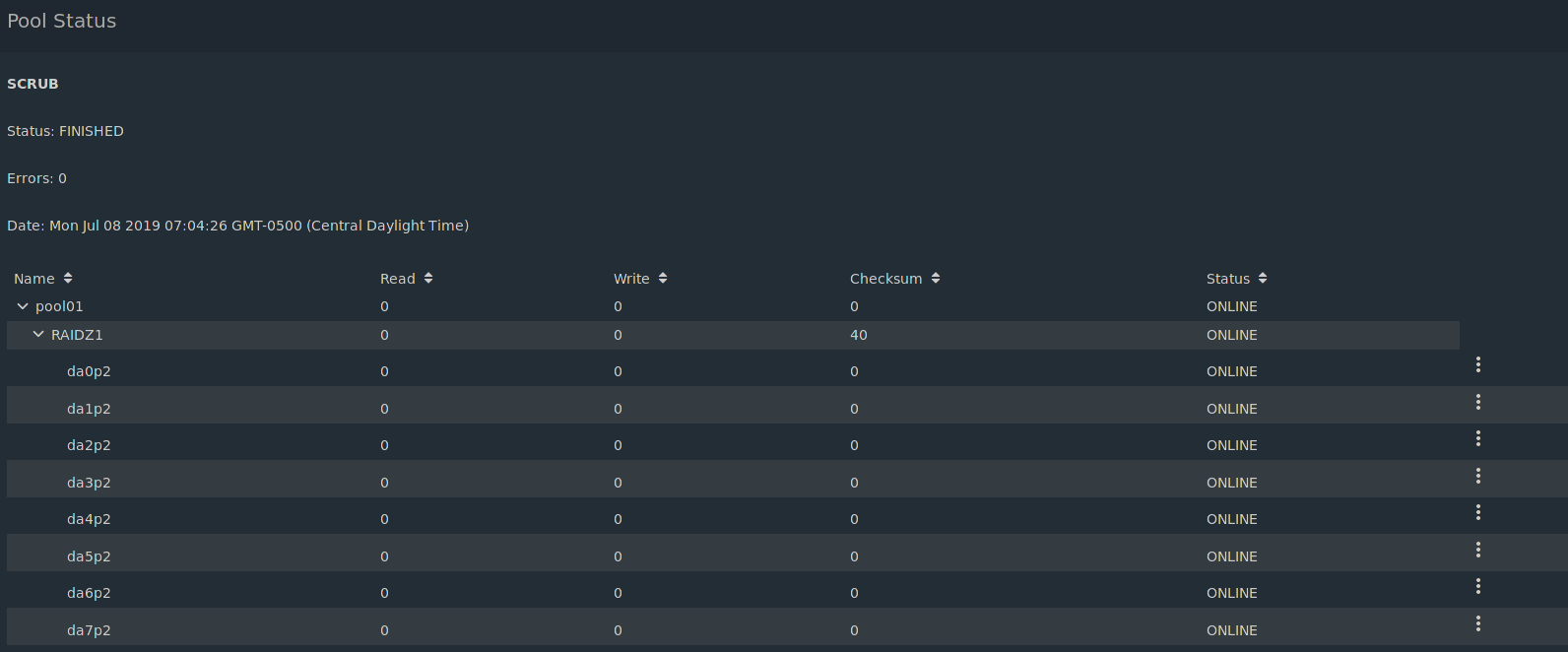
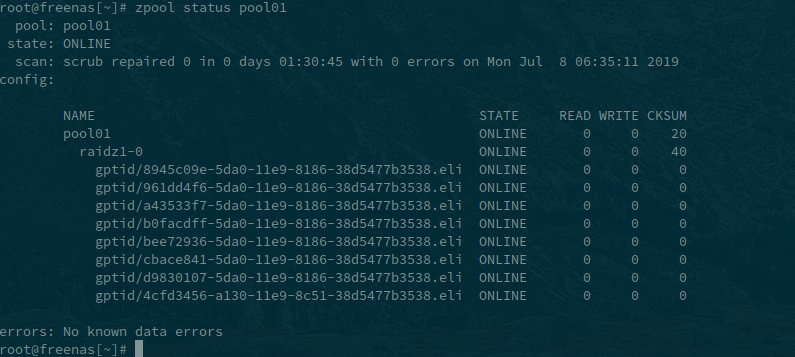
Well, it’s fixed. This morning when I checked the resilver hadn’t done anything. Still had the three gpid entries and da7. Decided to do the -v option like it suggested and it listed three files that were corrupted. I deleted those and did another scrub. An hour or two later I got an email at work from FreeNAS saying the scrub was done, then another saying that the notification for the degraded pool had cleared.
Just checked when I got home and everything’s happy. Dunno.