I see in the turntables that there are multiple md* arrays. Is there a way to mount multiple md* raid 5/6 arrays to one directory?
interesting stuff, did you test any other nvmes brand?
iam having some issues with micron ones that seems to cause straight up crashes, also on a gigabyte board. will test without MSI and some of your other tweaks!
did you experiment at all with numa balancing off? this is a bit out of my wheelhouse but some of the epyc performance documents mentioned it.
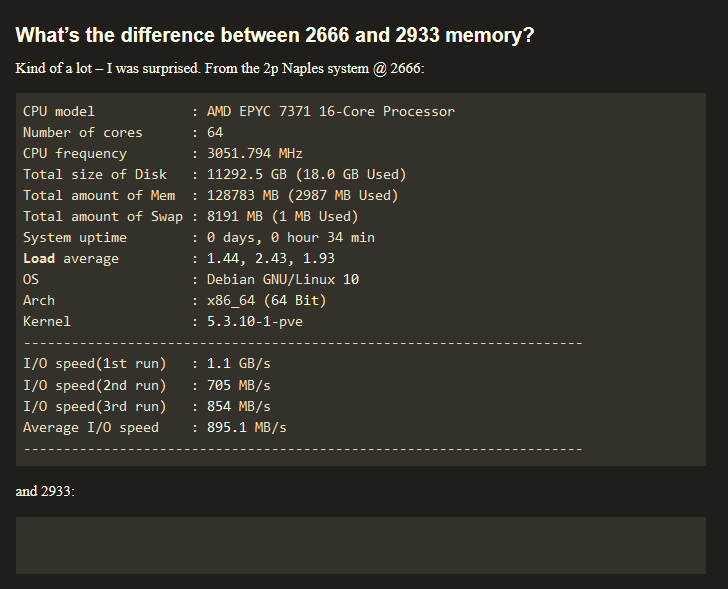
theres also the question of running 3200 or 2933 on ram to match infinity fabric for lower latency(your 2933mhz bench results is empty btw), but theres so many things to benchmark its hard to test all the different options against eachother.
The things you mention fix performance rather than straight up crashing. What’s the output of dmesg for the crashes?
How the hell did I miss this thread?
Edit Nvm, missed the 2021 update in the comment where Wendell goes over this
Note that the zfs_vdev_scheduler parameter is now obsolete and not used anymore, as it was sometimes flat out ignored in various systems anyways. Setting up a UDEV rule is now the recommended way to change schedulers around. The ZFS devs also seem to think that currently all default schedulers should work decently for common use cases and shouldn’t be changed without verifying that one is better for a use case.
https://github.com/openzfs/zfs/issues/9778
https://github.com/openzfs/zfs/pull/9609
Relevent bits:
set options zfs zfs_vdev_scheduler=none in /etc/modprobe.d/zfs.conf
reboot
check arc_summary or cat /sys/module/zfs/parameters/zfs_vdev_scheduler it will show “none”
finally check scheduler for zfs disks:
cat /sys/block/ DEVICE /queue/scheduler
it’ll show “mq-deadline”, but should be “none”
I’ve temporary made workaround via udev rule:
ACTION==“add|change”, KERNEL==“sd[a-z]”, ATTR{queue/scheduler}=“none”

I know it was just a snippet of the quoted GitHub, but does this address NVMe drives as well as sata?
Or better to just make sure zfs tools are at version 0.8+? Rather than temporarily setting”nvmep[0-9]” or what ever would be the syntax?
That’s a good point, it definitely won’t touch nvme1n1 and the like, and would need to be modified as you say.
As far as whether using it or not is good, I don’t know. My intention was just to point it out so people like me who sometime poke and test things, but don’t have good offhand or deep linux knowledge can use it as a reference to jump off and do further research.
And by zfs tools are at version 0.8+ are you refering to the “sorta kinda” direct IO added in ZFS version .8? If so there are still ongoing issues with them. My rough, surface level understanding is the real direct IO is here https://github.com/openzfs/zfs/pull/10018 and is yet to be merged.
Edit
And looking further, it looks like Wendell did exactly that in his script at the end, but shouldn’t be needed anymore because it’s default.
On Proxmox 6.3 as default I get
root@kobold:~# cat /sys/block/nvme4n1/queue/scheduler
[none] mq-deadline
1 Like
Thanks.
The 0.8+ was a reference to the closure on the bug with the note ‘moved from “to do” to “done” in 0.8-release’ and presuming newer versions would default to the “none” in Wendells script, from previous default of “noop “ or whatever? Was just an observation, I don’t have ballin’ NVMe drives to raid
could these settings be run on a single device for easier a/b testing or is it system wide only?
Anyone knowledgeable interested in helping with debugging NVME performance issues? Basically even RAID1 is slower than a single Kioxia SSD. More details in the thread below. Sorry for necro, but got to bring some attention in, somehow.
I’m planning for a NVMe ZFS server with a single socket EPYC Milan 7443, wondering has the situation being improved over the years?
Does the slow performance issue only related to EPYC CPUs, has anyone having good results with Xeon? Knowing that Milan L3 cache hit in remote die is ~110ns while Xeon 3rd is ~22ns.
CPU L3 cache performance should be largely irrelevant comparing storage performance due to significantly larger data volumes compared to L3 cache size.