I have been troubleshooting a new build all month and I’m at my wits end now. It’s built around an i9-9900kf and I went with an MSI Z390 board(full specs and models below.) It’s been so been so much so fast that I don’t remember how it responded when I first set it up. But as it is right now, the system has a problem where it will freeze so hard that the reset button isn’t able to restart the system. On Windows I thought it didn’t have the issue but after 4 days of stable use it froze once, then froze again the next day. If I load any Linux distro the problem will usually happen in minutes of loading the desktop environment. But sometimes it can last longer before it happens.
Here are the diagnostic steps I’ve taken so far:
Install Kubuntu 20.04, crashes
Install CentOS 7.3, crashes
Migrated existing Windows 10 1909 install, crashes
Disabled XMP, crashes
Updated/Wiped BIOS, crashes
Memtest86 test of 4 passes for 5 hrs, all pass
Tested each RAM stick independently, crashes
Intel Processor Diagnostic Tool, all pass
Replaced PSU, no change (both PSU’s are not new but came out of working systems)
Removed all PCIe cards, crashes
Replaced GTX 1080ti with GTX 970, crashes(cannot run without GPU due to being an “F” chip)
Booted from M.2/SATA/USB, crashes
Nothing has changed the crashing. Temps are all fine (I’m using a Noctua NH-D15). No overclocking, no RAM changes(so it’s running at 2133MHz). BIOS settings are all pretty much out-of-the-box
Another thing about the problem is that I haven’t been able to identify one particular trigger for it. The only possible correlation I’ve seen is that it may be more likely to crash after the system has been stressed. Not during the stress usually, but a minute or so after. Or it will crash if I restart after stress testing. All the stress testing has been done under Linux, I haven’t been able to reliably crash it in Windows so I haven’t tested it as much there.
I don’t know what is causing the freezing. But since I’ve had it fail with none of the cards, and with different RAM, I feel like it must be either the CPU, the motherboard, or how I have it configured. I would really appreciate advice on how to proceed.
Boot Drive: Samsung 970 Evo M.2
Bulk Storage HDDs: 5x Seagate IronWolf 2TB NAS (BTRFS RAID 5 with WinBTRFS driver)
Other PCIe cards:
Intel X520-T2 10Gb NIC
Marvell 88SE9215 based 4 port SATA controller
I haven been trying to avoid returning items on a whim to test because I’m not a huge fan of generating e-waste. I can return the motherboard to Amazon where I bought it from but I will have to RMA the CPU with Intel.
Hah, I don’t know if I qualify as being know as “THE” Tech Tangents but here’s a video of the issue happening that will verify that I’m at least the one from Youtube. It looks like I can’t add links but it at https://youtu.be/vKw-AbEPKX0
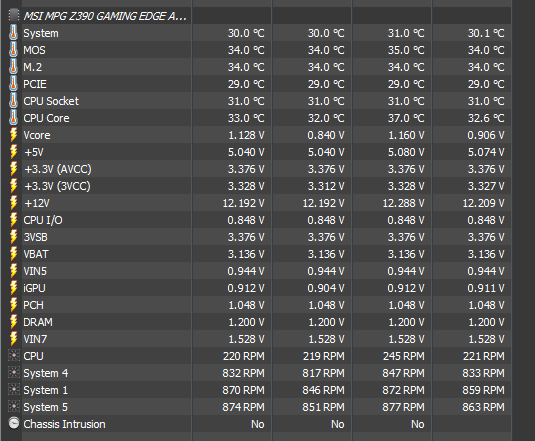
I’ve never used HWinfo64 but I think this is the area that would show those temps? Everything looks good there to me:
I’ll restart and bump up the RAM voltage to that and try to get it to crash again in Linux.
I bumped you up a level, new users can’t post links so it limits spammers, I can’t get it to embed though, I think MOS is the VRM temps which were fine but you were also probably at idle, keep an eye on them during load
To diagnose hardware problem with pc stuff, fastest and often cheapest way is to use more stuff. But use least amount stuff necessary to run it, removing variables is the first step.
That being said, judgeing from your description:
I would start with CPU first too. I cant remember ever having situation in which hardware reset doesn’t work, unless maybe cpu or bios died.
AFAIK this indicates that reset vector isn’t called properly, so basically cpu is dead until power cycle.
Also one memory not working but all working seems like memory controller also in CPU. Try one stick in different slots if your mobo supports one stick only.
So start with only cpu, mobo, memory and psu, (outside case), in your case (KF) also some lowend GPU. Boot from usb, disconnect anything else.
Then if problem persists I would escalate as such:
Reseat CPU like Gigabuster said
Put CPU in another mobo, best in known good working computer
Get another mobo and put current cpu in.
Those 3 steps will tell you if cpu/mobo combo is ok, which is fundamental for troubleshooting anything else. Otherwise you will be running in circles.
Also there’s small chance that your reset button is just broken
last time it happened to me was when my friend told me to “go up one” on voltage of my new Athlon II X2, apparantly he meant not an entire extra volt, ah the old days of being a noob
So this (being unable to reset-button out of a crash) usually indicates the OOB management controller is broken. You know, that little ARM CPU that brings up the board for the x86 CPU to take over from?
I have a nagging suspicion that you’ve got a bad motherboard.
Is there anything interesting in the syslog?
You can quick-upload with: dmesg | curl -F 'f:1=<-' ix.io
Other folk: We should find the source of the crashes, rather than just assuming that chucking more voltage at it will solve the problem. Since it happens in Linux (I got the impression, at least) more frequently than Windows, I don’t know that cranking up the vcore will fix anything.
I may not have phrased my troubleshooting there well. The crash can happen with both sticks installed and with either of the two individually installed.
I do need to try reseating it still. I don’t have any other motherboards or CPUs this new, my last new system build was in 2013. I was thinking about getting a replacement for the motherboard next but wanted to make sure I wasn’t being premature on that.
I have done this inside the case essentially. When I reseat the CPU I can do it again as a sanity check.
Heh, it does work but it would almost be funny if that was it at this point. But it still freezes anyway.
This would be the easiest to fix so I’m hoping that’s it.
When it crashes it is a full stop. Nothing gets logged. But here is that still: http://ix.io/2FnL
This part is what has been driving me nuts the most. It will seem stable and then just crash out of nowhere.
Linux does seem more prone to crashes from my experience troubleshooting it.
I adjusted the RAM voltage to 1.35v. Since I still don’t really have a way to force it to crash so I’m just using my highly scientific method of running a couple games while rendering a video to try and stress everything all at once. If it doesn’t crash during that a restart after 30m of stress usually trips it.
Yes, try that. Also there are plenty of reasons why getting rid of case is good idea.
Some time ago on reason was that some bug crawled between mobo and case and was shorting something.
Other time someone screwed mobo with one screw post in wrong place.
Point is, you want to remove as many variables as possible.
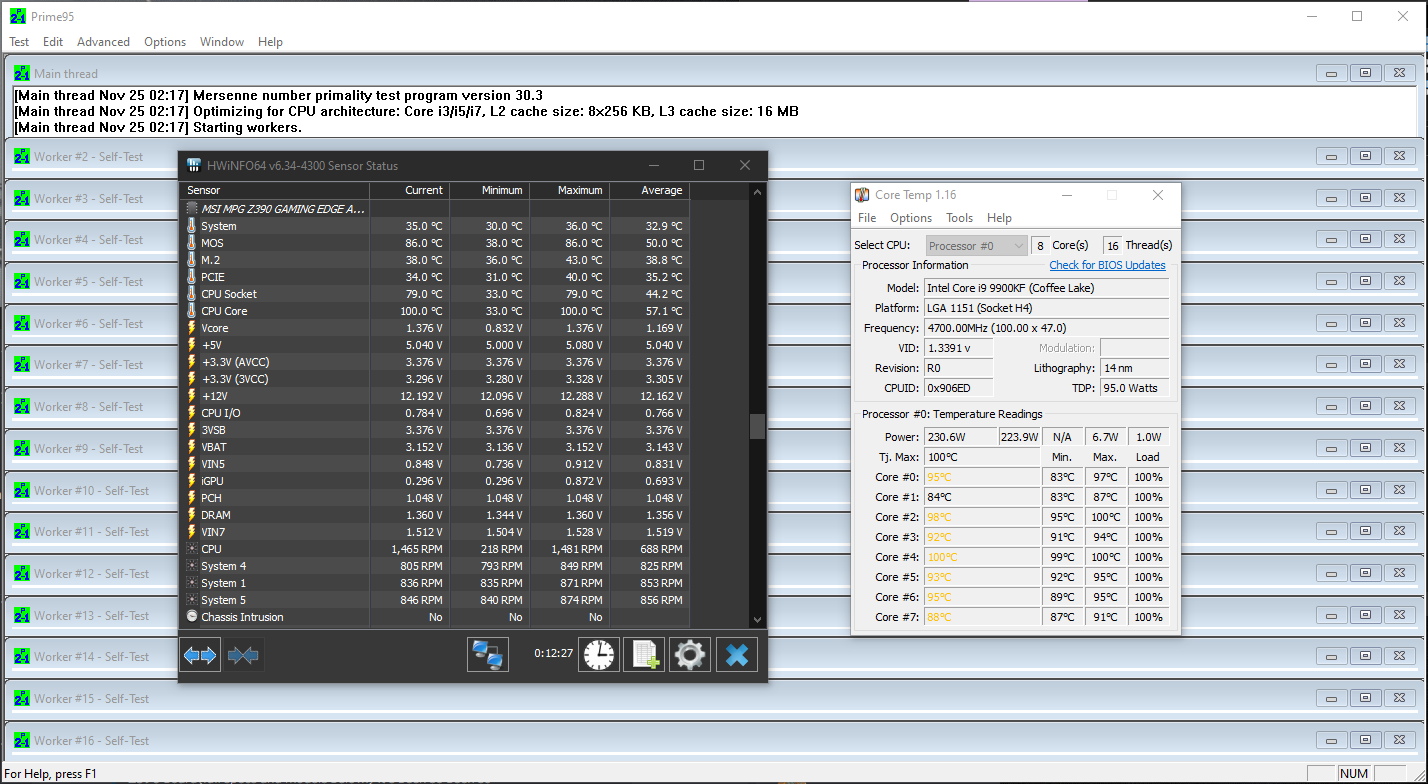
It crashed at 1.35V for the RAM still. And like I said before, it made it through the whole stress test without any errors and then crashed after I closed everything.
I tried to reboot into Windows as quickly as I could after that to get a better idea of VRM temps and they were about 10C higher at max. I’ll stress it in Windows and watch those now.
That’s hilarious, and I totally get eliminating variables so I understand doing that still.
Just in case, put mobo on something non conducting. I usually use box that mobo came in if it doesn’t have silver embossing.
But any piece of cardboard will be fine.
I’m not judging, but again past experience shows that people sometimes have weird ideas.
I couldn’t get it to crash on Windows, which is par for the course again. But I ram Prime95 for a minute or so on it while tracking temps. VRMs to get a lot hotter but so does the whole chip.
(not that it really matters in this case, but ambient is 21C right now)
I’m going to pull the motherboard now.
Yeah, the box is fine for this. I can understand people not thinking about putting it on the foil ESD bags they come in sometimes, but that will lead to a bad day.
Well i do have to mention that unfortunately your particular motherboard isn’t really a great board for overclocking i7’s or i9’s.
The vrm is a bit on the weak side, with a discrete mosfet setup.
I noticed in your screenshot mos temp of 86°C,
which i assume might be the mosfet temperature.
It’s technically is fine, however not really ideal for stock.
Likely not really a whole lot of overclocking headroom with that board.
I also noticed that your cpu temp is pretty high.
so my guess that the crashes might be related to that.
But if you can still return the motherboard and get a refund.
Then it might not be a bad idea investing a little bit more in a better board.
And another question which cpu cooler do you use?
Ah, that’s not very encouraging. I should add then that I think I can hear coil whine related to CPU stress so maybe I won’t exchange it I’ll just return it and get something else.
I don’t really plan on overclocking it, but I’d rather have something more appropriate for the CPU. I didn’t put a lot of thought into the board for CPU compatibility.
Well, that was with Prime95 running a torture test. The temps have been really good so far.
A Noctua NH-D15. I was trying to spec the system for OC’ing but I don’t really plan on doing it. I just want a lot of headroom and to have it run a little quieter.