220718
_0523
Okay I’ve been do throwing this idea around in my head after getting that reader to work last week. I don’t think I need a Kafka just to use cross service just to send REST request between services. After coming to this concussion. My first thought was damn I wasted a lot of time. Then I tried to rationalize it which I think won out in the end.
- I learned to a small degree how Kafka works and how to integrate it with golang and the package go-kafka. Learning is my main goal of this whole thing, but I would like some at the end I would like to use.
- Kafka already has retry part and scalability built in, but is not really needed at the current state of things.
- to get the best use of some of these features I would have to send all REST request through them and that just seems silly
- I do think making the kafka reader and writer item could be useful later for items that don’t have a easily implementable REST requirement
- I am still going to have to do the orchestration part of the pattern with sage it self and adding the kafka part right doesn’t seem to add anything of value. SO what I think I am trying to say is adding the kafka messaging between services doesn’t have a huge add at the current state if I am going to just send a REST request.
Now what…
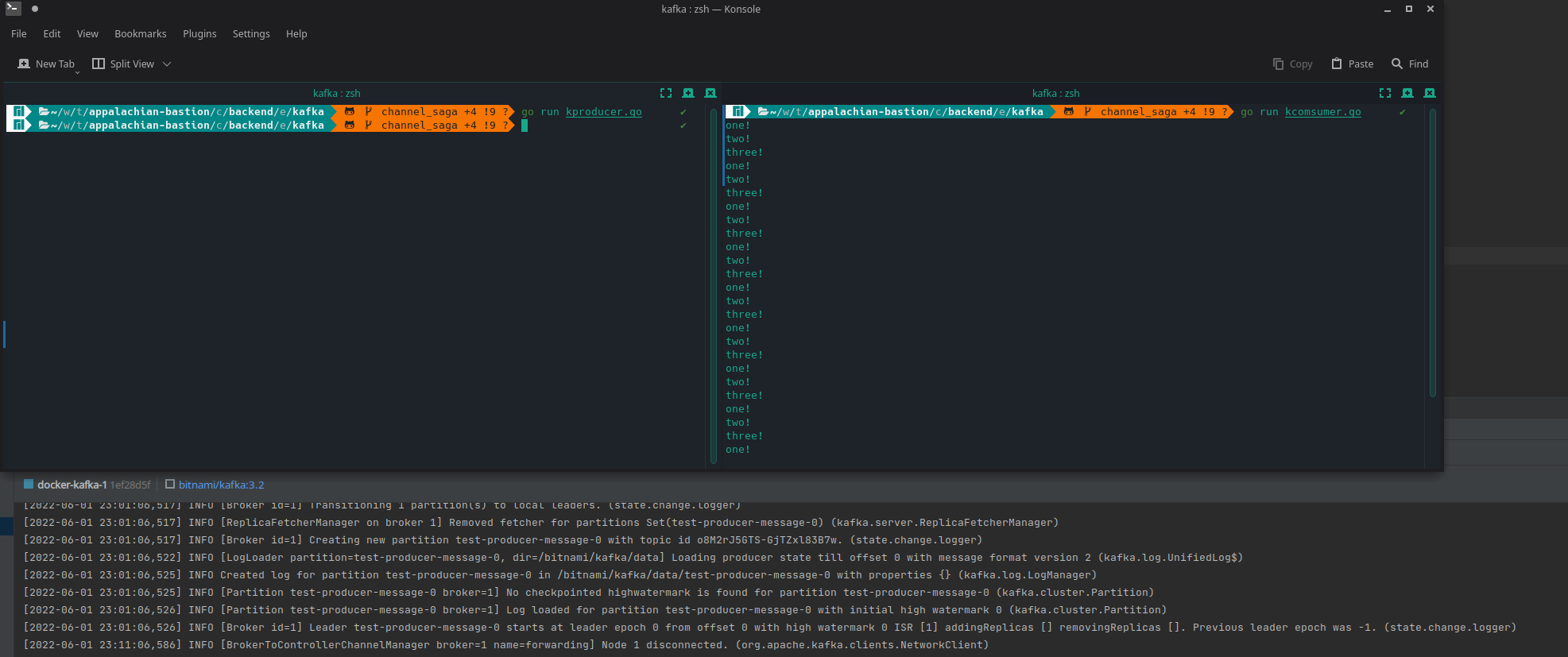
I’m the in the middle of the writing the kafka write that and service can use do some basic test to see if works as expected then move on start on the saga pattern it self.
__
_0555
Wtf is a key kafka:
I have to keep looking this up for some reason
Straight from the Stack-overflow
“Keys are mostly useful/necessary if you require strong order for a key and are developing something like a state machine. If you require that messages with the same key (for instance, a unique id) are always seen in the correct order, attaching a key to messages will ensure messages with the same key always go to the same partition in a topic. Kafka guarantees order within a partition, but not across partitions in a topic, so alternatively not providing a key - which will result in round-robin distribution across partitions - will not maintain such order…”
So in other other word if First in First Out is the desired give it some uuid.
_
_0832
So the generic kafka writer is complete and seems to work. I was feeling froggy and started to work on for generic reader, but ran into mux. So this I can pass a generic REST mux then fill it out each of the services or create more custom one per service and function carry, but both of those are a good deal of work for something I really don’t plan on using.
I have a working reader made just for the server service with a working mux for both GETs so I’ll leave that code in for now.
_2048
Okay after a sleep I have one more thought on the idea. The Sending REST request to that start of the service would work fine, but it would limit the depth of
220719
_2023
So I am designing the saga pattern in golang and the no real Inheritance is fucking me up.
_220720_0174
220726
Okay I’ve been working the saga pattern. It took me a while of paper and thinking to figure it out. I have the concept worked out. Looking at it now it seems simple, but it took me a lot of big thinking to figure it out.
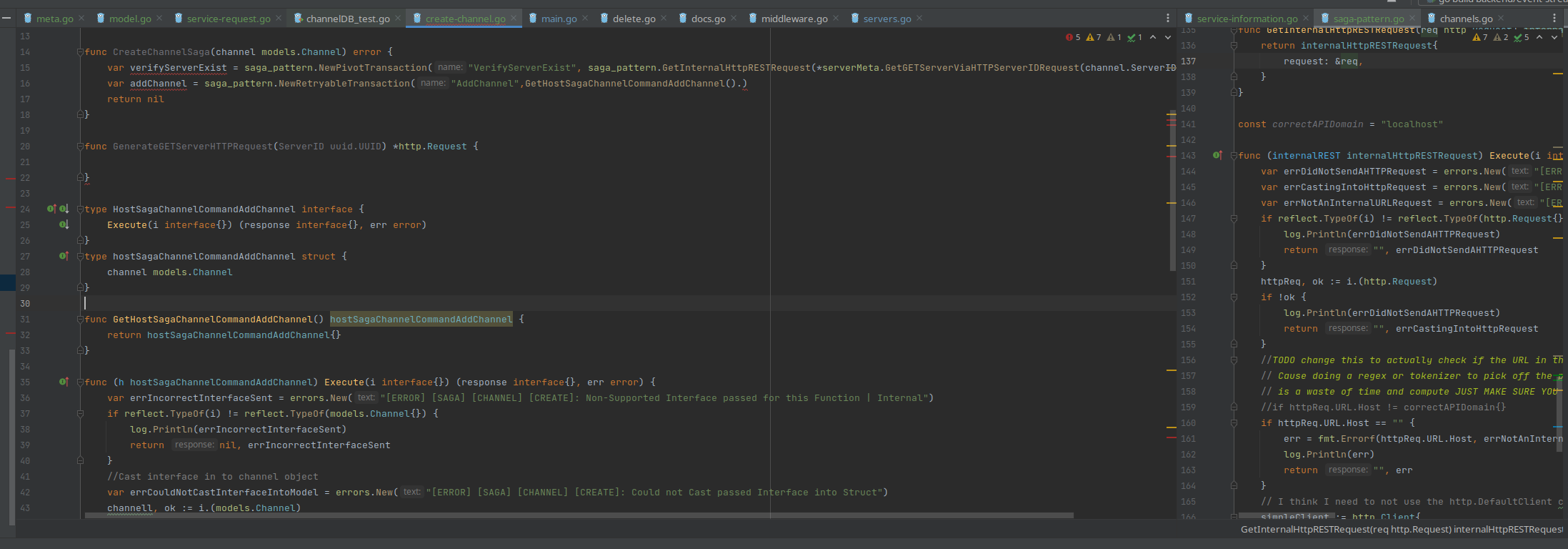
I stuck now how to cast an interface{} into its appropriate variable type. I have an to allow a standardize of the Execute (code snippet bellow) function cause I want to use the TransactionCommand as a collection. I know I could easy just make easier on myself to just have custom Transaction commands in each of the Transaction themselves, but I want to repeatable pattern to allow for REST or Kafka, and anymore Command message functions I mite need/want to use in the future. The idea that I really don’t need the Saga pattern at the projects current point is not lost on me. I have also argued with myself if the channel service and server service should be separated at this point.
type TransactionCommand interface {
Execute(i interface{}) (response string, err error)
}
_
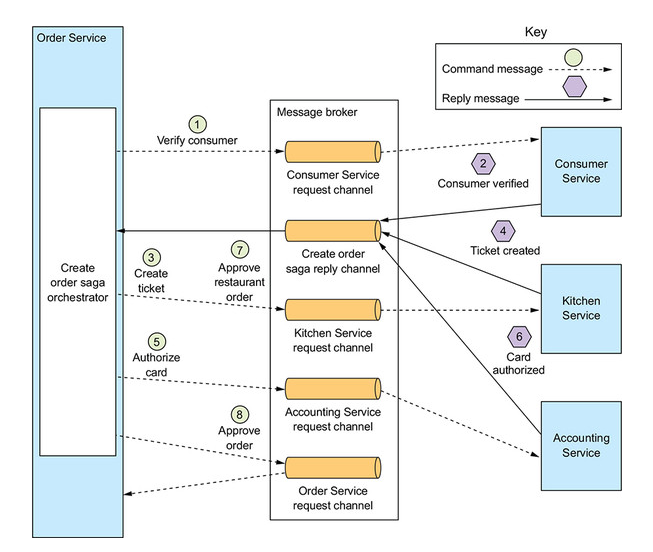
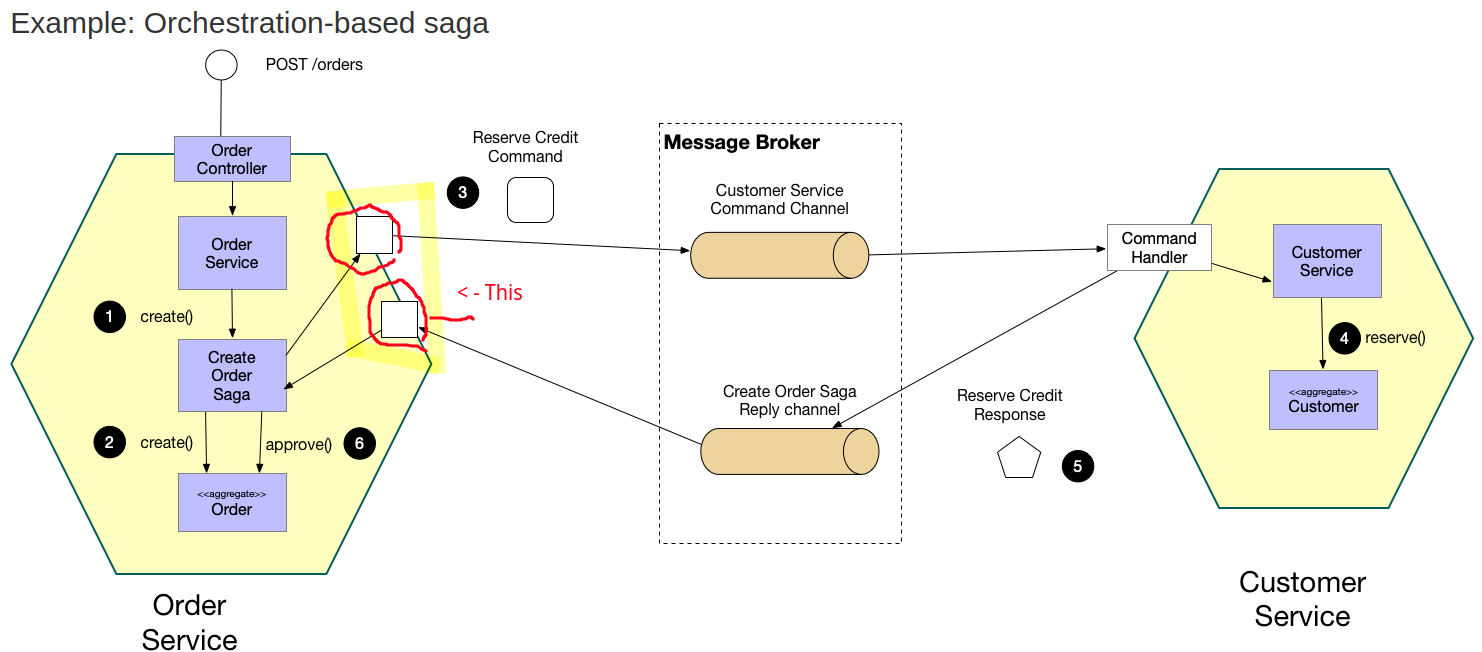
Another item that come to my mind is that if you send a kafka event message. There is no response like REST. Which I knew I and I have worked with in the past, but really tired to do the saga pattern with. So hear me out if you use the saga pattern using a message broker you end needing one permanent listener/reader then another temporary one every time a service tries to Execute a Saga. Cause that permanent one doesn’t have a straight line of sight into the on going function call running the Saga itself. So you you need to open the temporary listener with a unique key in the running Saga if you want a response from any other service you gonna need that temporary listener. I grabbed the example diagram from the microservices website. Is this really big deal not really you can still use the same docker/kube instance of Kafka you already have, but it just seems like a lot compute to use for something that could happen many times a second.
___22:57
Execute(i interface{})…
Okay after overthinking it for about 3 hours I got it go into a http.Request. I tried a few other things before I got here like JSON marshaling and unmarshaling(if you try this you will get a JSON end of line/file not found) and other option I almost did was looping threw the values and just copy/pasting them in which seemed really dumb but I was prepared if I could not think if somthing selse
Casting was the solution granted I didn’t think I could do this with non primitives
httprequest, ok := i.(http.Request)
if !ok {
log.Fatal("could not assert value to http.Request")
return
}
fmt.Println(reflect.TypeOf(httprequest), httprequest)
Output: http.Request {GET http://localhost:9292/servers 0 0 map[] 0 [] false map[] map[] map[] }
220727
_2337
Trying to OOP in go sure is fun. The more I do it the more fun it is…
Just realized I am going to need to rework this saga again
For the Execute interface for the transaction command I made each of the sub interfaces(classes in my head) take in an interface so you can pass anything to the sub Transactions Commands. Just using it cause there are few types of commands can be broken into. I spoke about this yesterday. But I just came to the conclusion right now that the empty structs I was making to accompany it have something later to call it with. I just realized I could just stick what I need in and just remove the incoming parm of the interface. Not a major thing just made me feel dumb cause I did some big brain thing about this I thought then when I went to implement it for the first time I noticed. Meh O well just thought give some insight. Cause this taking a lot of code to get working.
220728
_0852
Lost like 3 hours not cause I was messing up sub typing and design patterns of golang, but cause I did not know how slices work apparently which was fun, cause I was like it can’t be slice it has the more complex part of this. My stupidity knows no bound. I rewrote the Transaction relationship twice before I was sure they would work then before I looked at slice.
220809
Saga Pattern has been replicated
_2017
It took longer than I wanted to and stole my will a few times, but we’re here now.
Okay so there is still some work to be done on it. I still testing it, but I’ll push what I have now shortly.
Saga Pattern for microservices implementation
I am going to try and explain how this how thing works now (Bear with me)
SagaOrchestrator
This is main collector for the Saga it self. Its got a name, and a slice of Transactions
type SagaOrchestrator struct {
Name string
Transactions []Transaction
}
There’s a SagaOrchestrator Constructor that checks the order of the Transactions to insure they are ordered correctly which is important for proper saga execution. I am still testing this now. The count system was picked cause it seemed the most fast to write and easiest to read. I may go back make it so that you have to use the Constructor in the future, but for now I am fine with it cause I pass it around a little
func NewSagaOrchestrator(name string, transactions []Transaction) (*SagaOrchestrator, error) {
var sagaCreationErrorPrefix = "[ERROR] [SAGA_PATTERN] "
so := new(SagaOrchestrator)
so.Name = name
var countOfCompensatableTransactions = 0
var countOfPivotTransactions = 0
var countOfRetryableTransactions = 0
lastIndex := len(transactions) - 1
// Loops through the list of transactions to check for acceptable order has been passed
for index, transaction := range transactions {
//Checks for Compensatable Transactions
//Ruling:
// There cannot be a Pivot Transaction prior to any Compensatable Transaction
// There cannot be Retryable Transactions prior to any Pivot Transactions
if transaction.GetTransactionType() == GetCompensatableTransactionType() {
countOfCompensatableTransactions = countOfCompensatableTransactions + 1
//Checking if it's before any Pivot Transactions
if countOfPivotTransactions > 0 {
return nil, errors.New(sagaCreationErrorPrefix + "[SAGA_CREATION] [Compensatable]| Cannot put Compensatable Transactions after a Pivot Transaction")
}
//Checking if it's before any Retryable Transactions
if countOfRetryableTransactions > 0 {
return nil, errors.New(sagaCreationErrorPrefix + "[SAGA_CREATION] [Compensatable]| Cannot put Compensatable Transactions before any Retryable Transaction(s)")
}
}
//Checks for Pivot Transaction
//Ruling:
// There cannot be more than one pivot transaction
// There are no Retryable prior to the Pivot
if transaction.GetTransactionType() == GetPivotTransactionType() {
countOfPivotTransactions = countOfPivotTransactions + 1
//Checks that there is not already a Pivot Transaction in the List of Transactions
if countOfPivotTransactions > 1 {
return nil, errors.New(sagaCreationErrorPrefix + "[SAGA_CREATION] [Pivot]| There is more than one Pivot Transaction")
}
//Checks that there is not any Retryable Transactions prior in the list of Transactions
if countOfRetryableTransactions > 0 {
return nil, errors.New(sagaCreationErrorPrefix + "[SAGA_CREATION] [Pivot]| Cannot put Pivot Transaction After Retryable Transactions")
}
}
//Checking Retryable
//Note: currently 220801 that I do not think I need to check for anything for Retryable, cause the other two cover it.
//but I will leave this code here just in case
if transaction.GetTransactionType() == GetPivotTransactionType() {
countOfRetryableTransactions = countOfRetryableTransactions + 1
}
//Checks at last Transaction in the list
if index == lastIndex {
//Checks that there is a pivot if there is any Compensatable Transactions
if countOfPivotTransactions < 1 && countOfCompensatableTransactions > 0 {
return nil, errors.New(sagaCreationErrorPrefix + "[SAGA_CREATION] | Compensatable Transactions have not Pivot Transactions")
}
}
}
// So it passes the checks above its good to go.
so.Transactions = transactions
return so, nil
}
Transaction
Transaction is an interface cause there are multiple types( Compensatable, Pivot, & Retryable). There are currently three functions that they have to populate to be consider an Transaction. Sense I am using an interface and won’t access to the data if any directly. Cause golang doesn’t implement classes like other languages(there is no extend). I do have methods in which I can implement to return the data I need for the each of the separate sub types(this took much longer for me really understand and internalize. Which was most of time doing this part).
type Transaction interface {
GetTransactionType() sagaTransactionType
GetTransactionCommands() []TransactionCommand
GetTransactionName() string
}
GetTransactionType()
This gets a type I created in which I can compare during execution to know what type of Transaction it is. As each of them have there own logic. The custom type was made just to make coding it little easier and to insure an extra space/inconstant spelling/etc… cause I know myself I will mess up and string compare somehow and lose many hours of my life.
type Transaction interface {
GetTransactionType() sagaTransactionType
...
GetTransactionCommands()
This returns a slice of ‘TrainsactionCommands’ Its a list cause the Compensatable Transaction should have two by definition, even if the second one is empty, but it should have two. The others ones only need one, but this is why its a slice and not just the Command. ‘TransactionCommand’ Cause that is workhorse of this implementation of the Saga Pattern
type Transaction interface {
...
GetTransactionCommands() []TransactionCommand
...
GetTransactionName()
just returns the name of the Transaction its nice to have when implementing and debugging
TransactionCommand
// TransactionCommand this action part of the Transaction in which Execute would do it and give the response if any.
// this was made to allow both REST and Kafka thus functioning taking an anonymous interface. Doing this allows for both
// of the possible solutions Actions to be in the same collection
type TransactionCommand interface {
Execute() (success bool, err error)
GetTransactionCommandType() string
GetTransactionCommandName() string
}
GetTransactionCommandType() & GetTransactionCommandName()
both just used for debugging. The GetTransactionCommandType() is leftover from earlier prototyping, but I think it could be useful later… maybe.
type TransactionCommand interface {
...
GetTransactionCommandType() string
GetTransactionCommandName() string
Execute()
This interface method allows for many implementations of it. In which it only needs to return two things a proceed boolean and an error. When going threw this I wanted to allow for just about any type of ‘Command’ as the book puts it and boiled that down in an Execute function that could a HTTP call to another service, Kafka Message, g/RPC, even Service side DB calls, essentially whatever. The Book did not go over this, but its what I took from it. Essentially a list of Actions with a pivot points to undo or complete.
NOTE: I am not positive on the bool, error parms cause I think should be able to just send an error for either and let implementation of Execute deal with which was the main goal of this whole ‘TransactionCommand’. I just don’t want to leave out the option of needing to send an error for some reason, but still wanting to proceed.
type TransactionCommand interface {
Execute() (success bool, err error)
....
Saga Execution
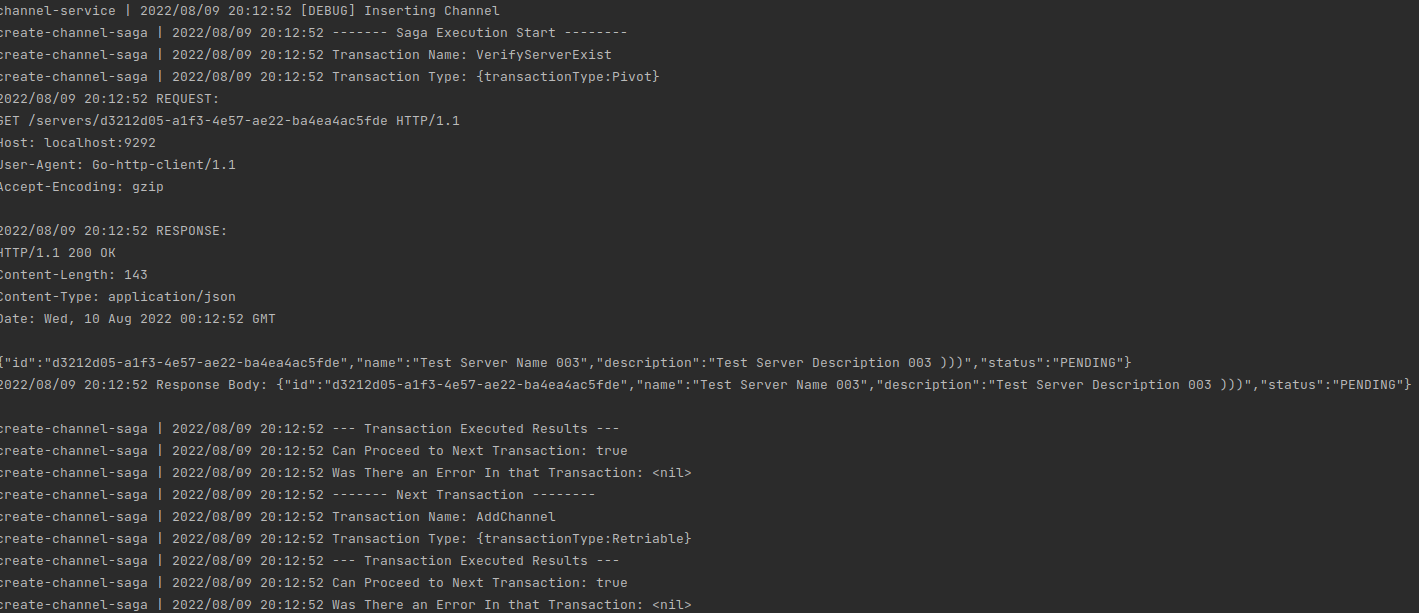
A Runner for the SagaOrchestrator its just a simple loop with some logic in it to ad hear to the rules of the saga pattern. The order of Transaction should be confirmed by using the SagaOrchestrator constructor. There are sub functions to deal with undo the necessary Transactions and retrying the ones that allow it. Still testing this logic but it seems to work enough for the write up and any changes will be in the git. I left a bunch of notes/comments in the code to help me write it and remind me when I would come back to it after the weekend.
There are a lot ghost prints in it, but that a future me problem I am still tweaking it in testing.
const RetryableTransactionRetryLimit = 3
type sagaRunner struct {
logger *log.Logger
generalErrorPrefix error
}
//ExecuteSaga
/*
Order of Transaction is import in passed ListOfTransactions - Compensatable Transactions: -- NOTE: Compensatable Transactions should have two Transaction Commands. The first one for the intended Transaction and the second one to Roll back that Transaction encase of failure/issues in any of the following Transaction
-- Can only be in place prior in order to the Pivot Transaction and never after -- If there is no Pivot Transaction Action then there cannot be any Compensatable Transactions - Pivot Transaction:
-- There can only be one per list of Transactions or - Retryable Transactions: -- If the Pivot Transaction exist in the List then Retryable Transactions can only be in after that Pivot Transaction
-- Retryable Transactions should never be in the list of Transactions prior to the Pivot Transaction if it exists
- NOTE Other Use Cases: -- You can have a Pivot Transaction without Compensatable Transaction(s)
-- You can just have list of Transactions without Pivot nor Compensatable Transactions(So just Retryable Transactions (Granted idk why you would tho))*/
func ExecuteSaga(orchestrator SagaOrchestrator) error {
prefixSagaExecutionError := errors.New(prefixSagaExecutionError + "[" + orchestrator.Name + "]")
sagaRunnerLogger := sagaRunner{
logger: log.New(os.Stdout, orchestrator.Name+" | ", log.LstdFlags),
generalErrorPrefix: prefixSagaExecutionError,
}
//This is the list of the undo transaction in the event of a failure or
var compensatableTransactionCommands []TransactionCommand
var hasCompensatableTransaction = false
sagaRunnerLogger.logger.Println("------- Saga Execution Start --------")
for _, transaction := range orchestrator.Transactions {
//Pull the List of Transactions Commands
// [1] is the intended transaction Command // [2] would be a compensatableTransaction Command transactionCommands := transaction.GetTransactionCommands()
sagaRunnerLogger.logger.Println("Transaction Name: " + transaction.GetTransactionName())
sagaRunnerLogger.logger.Printf("Transaction Type: %+v\n", transaction.GetTransactionType())
//Execute the Transaction
// To handle result a lil later canProceed, err := transactionCommands[0].Execute()
sagaRunnerLogger.logger.Println("--- Transaction Executed Results ---")
sagaRunnerLogger.logger.Printf("Can Proceed to Next Transaction: %t\n", canProceed)
sagaRunnerLogger.logger.Printf("Was There an Error In that Transaction: %v\n", err)
//COMPENSATABLE TRANSACTION
//If it's a Compensatable Transaction Type add the second transaction to the list undo Transaction Commands if transaction.GetTransactionType() == GetCompensatableTransactionType() {
hasCompensatableTransaction = true
compensatableTransactionCommands = append(compensatableTransactionCommands, transactionCommands[2])
}
//FAILURE IN COMPENSATABLE OR PIVOT TRANSACTION
// If get the do not proceed flag or an error (the canProceed is for Transaction Commands that get responses) if !canProceed || err != nil {
// This is just in case you get a Pivot Transaction without any CompensatableTransaction(s) in an effort to try and save some compute
if !hasCompensatableTransaction {
if transaction.GetTransactionType() == GetPivotTransactionType() {
if err == nil {
err = errors.New("got a Do Not Proceed, but No Error(So now you get an Error)")
}
log.Println(err)
return err
}
}
//Check if the Transaction Type is Pivot/Compensatable then undo the Transactions providing the list of undo Transaction Commands
if transaction.GetTransactionType() == GetCompensatableTransactionType() || transaction.GetTransactionType() == GetPivotTransactionType() {
undoErr := undoCompensatableTransactions(compensatableTransactionCommands, &sagaRunnerLogger)
if undoErr != nil {
// This process fails I really don't want to tell the end user. So I guess I'll just log it.
sagaRunnerLogger.logger.Println(undoErr)
}
if err == nil {
err = errors.New("got a Do Not Proceed, but No Error(So now you get an Error)")
}
return err
}
}
//Check if the Transaction Type is Retryable then try to reattempt them to preset retry limit
if transaction.GetTransactionType() == GetRetriableTransactionType() {
if !canProceed || err != nil {
didItFinallyWork, err := retryRetractableTransactionToPresetLimit(transactionCommands[0], &sagaRunnerLogger)
if err != nil {
return err
}
if !didItFinallyWork {
retriesFailed := fmt.Errorf("%v [UNDO] | After the Preset Number (#%d) of Retries this RetryTabiable Transaction(%v) has still Failed. Look at contruction of this Transaction and its Transaction Command(%v)", sagaRunnerLogger.generalErrorPrefix, RetryableTransactionRetryLimit, transaction.GetTransactionName(), transaction.GetTransactionCommands()[0].GetTransactionCommandName())
sagaRunnerLogger.logger.Println(retriesFailed)
// I am not positive If I am supposed to return this error I will for now
return fmt.Errorf("%v | %v ", retriesFailed, err)
}
}
}
sagaRunnerLogger.logger.Println("------- Next Transaction --------")
} //End of loop
sagaRunnerLogger.logger.Println("------- End of Saga Execution --------")
return nil
}
func retryRetractableTransactionToPresetLimit(command TransactionCommand, runner *sagaRunner) (bool, error) {
var didItFinallyWork = false
var err error
for i := 1; i <= RetryableTransactionRetryLimit; i++ {
runner.logger.Println(fmt.Sprintf("%v [RETRYABLE] Retrying Retryable Transaction %d of %d", runner.generalErrorPrefix, i, RetryableTransactionRetryLimit))
var err1 error
didItFinallyWork, err1 = command.Execute()
//TODO Learn proper error handling
err = fmt.Errorf("retry #: %d | error: %v | %v", i, err1, err)
}
return didItFinallyWork, err
}
func undoCompensatableTransactions(listOfCompensatableTransactions []TransactionCommand, runner *sagaRunner) error {
//TODO Need to learn to Wrap errors
undo := errors.New("[UNDO] |")
errCollector := errors.New("")
for _, transactionCommand := range listOfCompensatableTransactions {
workAsExpected, err := transactionCommand.Execute()
if err != nil {
runner.logger.Printf(" %v %v | TransactionCommandName: %v, Error: %v", runner.generalErrorPrefix, undo, transactionCommand.GetTransactionCommandName(), err)
errCollector = fmt.Errorf("%v | %v | %v", runner.generalErrorPrefix, undo, err)
return errCollector
}
if !workAsExpected {
runner.logger.Printf("%v %v | | TransactionCommandName: %v . Got an do not proceed on the undo that's not good so here is your sign", runner.generalErrorPrefix, undo, transactionCommand.GetTransactionCommandName())
}
}
return nil
}
Other items
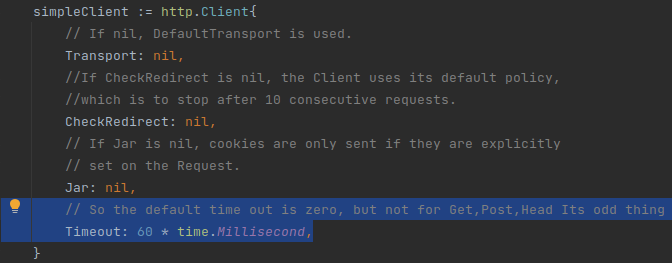
For future me if you see this error in the stack it most likely means the http request timed out and just add some time to the timeout.
"context deadline exceeded"