It has been about a year since the last update. There was also a warning about this before posting. I apologise if I’m breaking rules here!
I don’t have any glorious new features, but a lot has happened in the background.
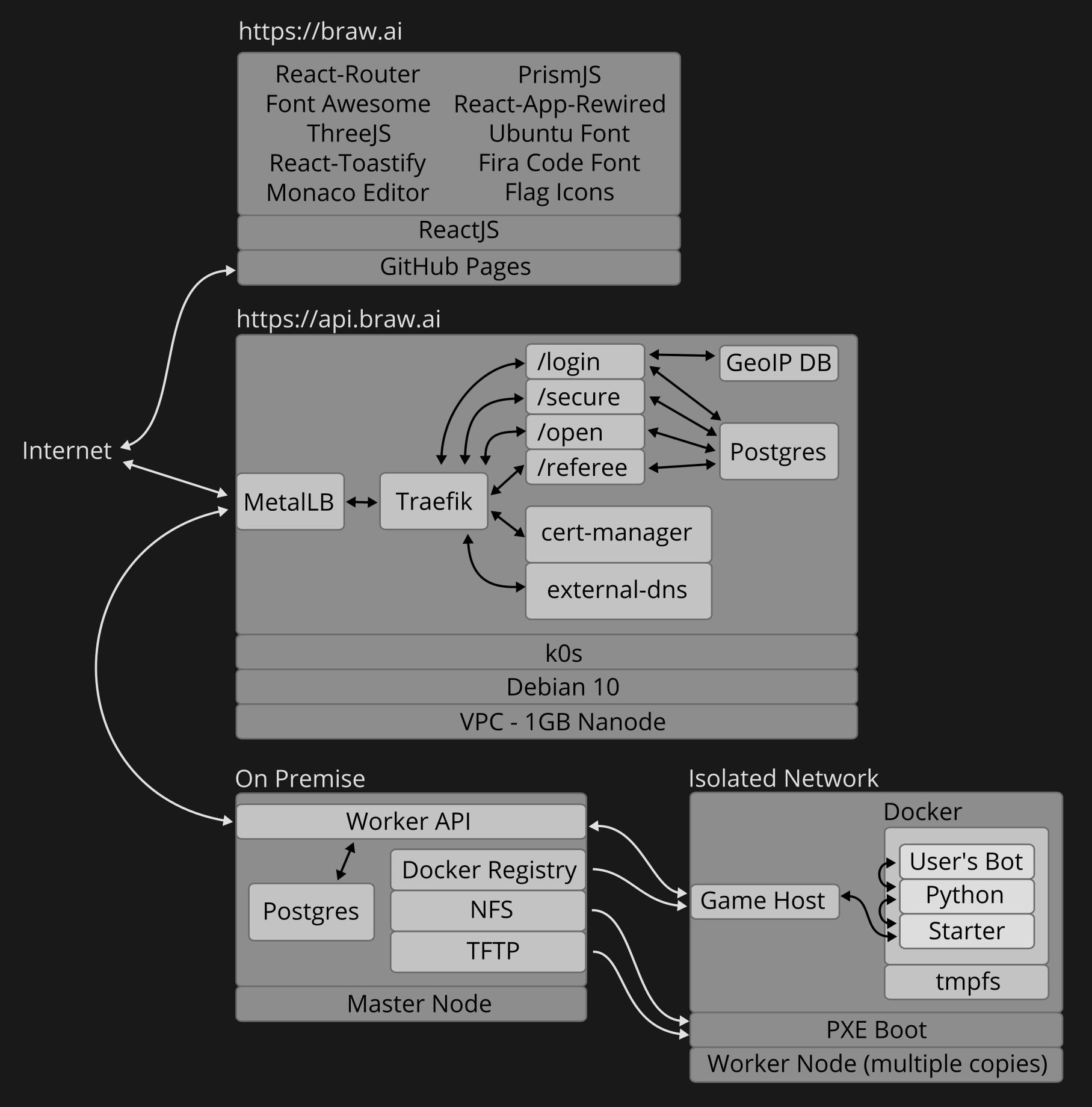
In a summary: brawl.ai website now runs on Cloudflare Pages + Workers, and Oracle Cloud. Currently the monthly cost is 0$. The only expense is the registrar fee for the domain name with .ai TLD.
I’ve detailed some of the migration/conversion process for those who may be interested. Before starting, here is a short list of the changes in the tech behind the scenes over the lifetime of the brawl.ai website:
API:
- DB: MongoDB → PostgreSQL → Cloudflare KV
- Language: Java Spring Boot → Golang → JavaScript Workers
- Engine: Google Kubernetes Engine (GKE) → Linode Kubernetes Engine (LKE) → k0s → microk8s → k3s → k0s → Cloudflare Workers (serverless)
- Auth: OAuth2 → JWT → sessions
- CI: scripts → Concourse CI → GitHub Actions
- CD: scripts → Terraform → Ansible → ArgoCD → GitHub Actions
- Email: Sendgrid → Postmark
Workers / Game host:
- Raspberry Pi cluster → Oracle Cloud
The webpage hasn’t changed, but here is its tech stack if interested:
- reactjs + monaco (VSCode) + threejs + fontawesome + flag-icon-css + fonts
Email:
Sendgrid closed my account as I wasn’t sending enough emails. Once I had a month or two without a single email being sent from my account (nobody reset their password), that was too long for them to keep my account open. Also, they didn’t notify me that they had closed my account. I was running tests after upgrading Kubernetes and found out that their API just happily responds with 200 for an email delivery request even if your account is closed, but without actually delivering the requested email. This is also when I found out that my account had been closed, and the reason for it.
I contacted Postmark and told them what I’m using emails for and what happened with Sendgrid and they were happy to have me.
Kubernetes:
I’ve come to the conclusion that managed Kubernetes (k8s) is nice. Very nice! I’ve tried k0s, microk8s and k3s. Here is a summary comparison between them and the issues I ran into.
Both k0s and k3s ran reliably, but microk8s automatically updates itself as part of the snap package system (part of modern Ubuntu). It managed to somehow eat all the memory on the server after some automatic restarts and failed to start up again. I had to purge snap (the package manager itself) by removing all its files from the system before I could get microk8s to start up again. It wasn’t enough for me to restart or even reinstall just the microk8s.
Upgrading k0s has rarely been pain-free. In most cases when I took the effort to upgrade it (every couple of months), something always broke. I used to run External-DNS… for the scalability and just for being able to declare domain names and get automatically correct DNS setting for automatic certs. This is entirely pointless for a project of this magnitude! For example, setting up some DNS records would have been the least painful part in scaling this cluster from a single-node to multiple nodes under load.
I used Cert-Manager for the certs. However, getting Traefik and MetalLB to work nicely with External-DNS and Cert-Manager requires careful research and experimentation to find the correct version numbers for both the software and the YAML configuration files. This includes scouring through source-code and reported issues for all these components. On every upgrade, some YAML configs had to be rewritten and often in a new layout as something was always broken between versions.
Additionally, I had to refresh the k8s ingress config every 3-months as Cert-Manager just didn’t do that by itself for some reason. This meant that the ingress controller didn’t stop using the old certificates by itself and start using the new certificates from Let’s Encrypt, and obviously new requests to the old expired certificates would fail. Not very automatic…
I ended up dropping both External-DNS and Cert-Manager after a while as Traefik could just get the certs by itself, or I thought so. After the service had been happily running for about two weeks, the log files started getting filled with these:
Jan 08 16:23:46 api.brawl.ai k0s[449]: time="2022-01-08 16:23:46" level=info msg="E0108 16:23:46.968824 469 cacher.go:420] cacher (*unstructured.Unstructured): unexpected ListAndWatch error: failed to list cert-manager.io/v1beta1, Kind=Certificate: conversion webhook for cert-manager.io/v1, Kind=Certificate failed: Post \"https://cert-manager-webhook.cert-manager.svc:443/convert?timeout=30s\": service \"cert-manager-webhook\" not found; reinitializing..." component=kube-apiserver
Jan 08 16:23:46 api.brawl.ai k0s[449]: time="2022-01-08 16:23:46" level=info msg="E0108 16:23:46.963754 469 cacher.go:420] cacher (*unstructured.Unstructured): unexpected ListAndWatch error: failed to list acme.cert-manager.io/v1alpha3, Kind=Order: conversion webhook for acme.cert-manager.io/v1, Kind=Order failed: Post \"https://cert-manager-webhook.cert-manager.svc:443/convert?timeout=30s\": service \"cert-manager-webhook\" not found; reinitializing..." component=kube-apiserver
Jan 08 16:23:46 api.brawl.ai k0s[449]: time="2022-01-08 16:23:46" level=info msg="E0108 16:23:46.076516 469 cacher.go:420] cacher (*unstructured.Unstructured): unexpected ListAndWatch error: failed to list cert-manager.io/v1beta1, Kind=CertificateRequest: conversion webhook for cert-manager.io/v1, Kind=CertificateRequest failed: Post \"https://cert-manager-webhook.cert-manager.svc:443/convert?timeout=30s\": service \"cert-manager-webhook\" not found; reinitializing..." component=kube-apiserver
Jan 08 16:23:46 api.brawl.ai k0s[449]: time="2022-01-08 16:23:46" level=info msg="E0108 16:23:46.074678 469 cacher.go:420] cacher (*unstructured.Unstructured): unexpected ListAndWatch error: failed to list cert-manager.io/v1alpha2, Kind=CertificateRequest: conversion webhook for cert-manager.io/v1, Kind=CertificateRequest failed: Post \"https://cert-manager-webhook.cert-manager.svc:443/convert?timeout=30s\": service \"cert-manager-webhook\" not found; reinitializing..." component=kube-apiserver
Yeah, that is probably a misconfiguration on my part, but it was happy for two weeks and then started spitting these! The certificates worked too, but it just spammed too much into the log files.
Traefik would write so much to the log files that the disk space would fill up. This is close to 20GB of log files on the 25GB nanode (at Linode). Kubernetes will start killing pods once the system starts to run out of resources, for disk space this happens when less than 10% is available.
I ran the latest k0s, latest Traefik and the problem still persisted. I could roll-back, but this also wasn’t the first time I ran into problems. I attempted to debug this a couple of times, but the errors didn’t show up until the service had run for about two weeks. I gave up in the end. This wasn’t worth it.
After spending a significant amount of my free time for just fixing upgrades and on maintenance, version after version, I decided it was time to look for a different platform. Maintained Kubernetes, like ones from Linode, Google, Amazon or elsewhere could be an answer, but they also cost a lot more money (for a good reason and I start to think it is well worth it when you must use Kubernetes).
Why not k3s? I run k3s on my NAS and I’m a happy user. It is by far the most polished one out of the three with the least amount of maintenance. Upgrades have been painless and things just work for the most part. Except you cannot get k3s to forward the real client IP address [1] [2], which I’d use to determine the country and flag for each user. This isn’t a big deal for my NAS/home server, but it is for brawl.ai website. It is the CNI k3s has chosen that prevents this. k8s is plug-and-play (like LEGO), and it is possible to change the CNI, but then you add this to the maintenance burden when you upgrade from version to version. This feels like going back to k0s.
If I continue with self-hosting and managing Kubernetes, I will not have enough free time to also work on improving brawl.ai. In the end, I decided to go as far managed as possible, without breaking the bank. I looked for the many different serveless platforms and the response times by Cloudflare Workers was what won me over. It was time for another rewrite. I merged all the microservices into a monolith JavaScript application and turned the Postgres queries to a “query-less” key-value format.
Cloudflare Workers:
The hardest part was to figure out how to store the data in a way that minimises read and write operations and doesn’t produce conflicts in an eventually consistent platform. If I wanted to stay on the free tier, I couldn’t use Durable Objects.
There are a couple of key points to CF Workers KV store that let you use it without the Durable Objects. One is that if you just wrote data to the KV, then it is immediately consistent if you read it from that exact same location (data centre/edge node). It can take up to a minute to propagate elsewhere, but it is consistent for the same client at the same location, immediately. I found out that while it isn’t mentioned anywhere, the list operation isn’t consistent immediately, but the put and get operations are. For example, if I created a new bot and then immediately listed all the bots that I had by the KV list operation, it would not necessarily find my new bot. This makes caching difficult and breaks the user interface. Even if you refresh the page, it may still show you old data, but not always.
The solution ended up being to separate users’ data into their own key-value pairs. There are not shared tables to query from. Each user’s data is stored in its own document or value. For example, when a user requests data, its session information is behind one key, which needs to be requested first to verify the username in the request. Then another key is used, based on the request, to get the actual data that is being requested. All data is aimed to be as pre-processed as possible to reduce cross-referencing. Ideally, a single key-value read or write would fulfil the entire request.
All users also write to their own keys only to avoid two users having a race condition to the same key (remember: the latest write wins). But this is difficult for the worker, that actually runs user’s programs and produces results. The worker also writes to its own files only. Without Durable Objects, I’m limited to just a single worker, but with the current amount of traffic, it is still plenty. When a user submits a bot for the brawl or testing, it writes a copy of that bot for the worker to find out and marks its own copy as read-only. The worker gets notified immediately. Once the worker is finished, it will modify its own copy only, and only once. The user’s read-only copy will remain untouched. But once the user requests information about its read-only copy, it will check if the worker has updated its version. If there is an update on the worker’s copy, it means the worker is now finished and the user’s read-only copy can be updated with worker’s copy, and the worker’s copy can now be deleted. This only works due to the single update (flag) on the worker’s copy.
What about backups? The list operation doesn’t return values with keys, only keys, and reading the value for each key is rather expensive and slow. However, each key can have metadata associated to it, which is returned with the list operation. So, you can get keys and its metadata with the list operation. To find out what keys’ values need reading, I encapsulated the KV write operation to update the metadata for each write. More specifically, each write adds a “writeTime” value, which is very similar to what all common filesystems do. The backup software can check from the metadata’s “writeTime” if a key’s value has changed and can then query that key to back it up automatically. What about all the keys that I don’t want to backup, such as session data or other temporary data? You can list by prefix, and all permanent/backup keys have “permanent:” keyword as a prefix. This filters out any temporary data.
The implementation is still not perfect, and there are still some bugs with the UI that I haven’t managed to solve yet. For example, if two browser windows are open, and both are logged in, they can go out of sync. Adding a project, or launching a project on one window doesn’t necessarily appear on the other window even when refreshed. I’m guess that this could be due to the two browsers hitting different end points or edge servers from Cloudflare. Sometimes even on the single browser window, the refresh doesn’t always get the latest data from the server. So, I still have some bugs to solve…
Workers / Game host:
I listened recently “EP 86: The LinkedIn Incident” from Darknet Diaries, and I was convinced that I wanted the self-hosted solution of brawl.ai workers that run untrusted user-submitted code, out of my home network.
I searched for an affordable solution to host the worker software. Ideally it would be run in a serverless environment and on-demand. This would allow it to scale when needed and not accrue expenses when it was not needed. As far as I can tell, none of the serverless offerings out there can meet the odd requirements of brawl.ai website/project. For example: there are either one or two untrusted applications running, which need to be isolated and resource limited (including no network access), but they are also controlled by another software which talks to them via STDIN, STDOUT and STDERR.
The target platform would be capable of running a multi-core node/computer/VPS, and ideally with consistent performance portfolio for each core and not the shared-core types that vary significantly in performance over time. This would give both applications an equal amount of processing power (for fairness) and allow limiting each one to its own core (or set of cores) to prevent one from affecting the other (for fairness again).
Something like a Linode/VPS instance could work, that would be automatically started and automatically destroyed. Cloudflare workers are limited to HTTP requests/fetches and cannot control instances via SSH. This rules out Ansible and Terraform. However, there are REST API and stackscripts. While I was working on this, I stumbled across Oracle Cloud’s free-forever-tier: 24GB memory, 4-core arm64 instance. Perfect. I’ll run that one forever and that does all the worker stuff now.
In my previous implementation of the workers, I was annoyed with the delays that I had when I submitted some code for a bot, it could take up to a minute for the workers to even pick it up and start processing it. I had my original worker cluster in my home network, behind a firewall. I didn’t want to open up a port for it and I left it polling. It would poll once a minute, 1,440 times a day. For Cloudflare Worker’s free tier this was too frequent and had to be reduced. I made some changes after merging the whole cluster code together for the single VPS: it has an open port and will get notified immediately when code is submitted. It will also poll every 10 minutes (144 times a day) in case it missed something and there was an error with the initial notification. It is now much more responsive than before!
But, now the API… doesn’t update reliably (see the previous section)! Aaargh! The worker now responds within seconds, but the API doesn’t show the results immediately. I’ll get to the bottom of this sooner or later. For now, you win some and you lose some.
Web UI:
Not that much has changed.
One user requested an ability to drag and drop files to the UI from a home computer. I added this capability last summer.
Another user asked why the failed project/bot cannot be edited and it had to be duplicated. I’ve changed this too. Now, once the bot has failed the initial test, it can be edited and resubmitted without making any duplicates.
Visual Studio Code can now run in a browser. The brawl.ai website uses VSCode’s text-editor part (called monaco) and I’ve been looking into adding the rest of the VSCode capability if possible. The editor hosted by Microsoft can even run python language server in the browser version (for auto-completion and navigation). However, the web version of VSCode is closed-source and the language server that runs in the browser (pylance) is also closed-source. The odds are not in my favour.
Now that brawl.ai isn’t so memory and space limited when running inside Oracle Cloud, I can start looking into adding other language options for the bots. The language choices probably need to be platform/hardware architecture agnostic, in case I need to migrate to x86 or some other architecture in the future.
Visitor counts
After moving the site from GitHub Pages to Cloudflare Pages, I got to view some analytics. In February 2022 (the first full month on Cloudflare pages), the webpage had the following number of requests according to Cloudflare:
- United States: 5,977
- Czech Republic: 3,470
- United Kingdom: 2,433
- Australia: 1,292
- Other: 4,101
That’s 17,273 in a month. Unexpected!
In March 2022, the following traffic was reported:
- United States: 3,442
- United Kingdom: 2,935
- Czech Republic: 2,027
- Poland: 1,930
- Other: 6,671
Totalling 17,005 for that month.
At this point I’m suspecting that these are mainly bots and crawlers on the website, but are there actually that many crawlers? Cloudflare thinks that is about 500 unique visitors per month. That’s all for the static pages portion of the site. The API gets just over 5,000 requests a month.
The main site is a single page application (SPA), built with reactjs. Webpack splits the JavaScript portion of the website to around 327 individual JavaScript files. That’s the whole site. So, if each unique visitor browsed every part of the site each visit (without CSS or fonts), that would be 163,500 requests. The request count is probably this high due to the multitude of files.
Cloudflare also blocked 4 attacks in March, and 1 attack in February. March attacks came from the US, and the February attack from Japan. I don’t know more about these incidents.
Going forward:
Hopefully all this effort will actually end up reducing the maintenance required for this website. Note: the maintenance (or updating k0s/microk8s/k3s) isn’t really that much if I was doing this full-time, but for a hobby project that I work on my free time, it eats up way too much.
Moving the API to Cloudflare Workers probably means that the .onion address (TOR) is postponed quite a bit.
I find it incredible that I can run the whole site now with zero monthly cost (apart from the domain name registration cost). The whole site should also be a lot snappier for everyone around the world, as it should always be available at the closest location. There is a cold-start, but after the first query things should fly!
Final words
I obviously didn’t explain every change in the list at the beginning of the post. A lot has happened in a year. A lot of decisions and thoughts. If you’re interested to know more on anything specific, just let me know and I’m happy to dig deeper.
I’m not going to leave another TODO list, I’ll just let you know when noteworthy things are in!